
Truth Discovery from Conflicting Data:A Survey
2023-09-22 14:29:56FANGXiuWANGKangSUNGuohao孫國(guó)豪SISuxin司蘇新LYUHang
FANG Xiu(方 秀), WANG Kang(王 康), SUN Guohao(孫國(guó)豪), SI Suxin(司蘇新), LYU Hang(呂 航)
School of Computer Science and Technology, Donghua University, Shanghai 201620, China
Abstract:With the rocketing progress of the Internet, it is easier for people to get information about the objects that they are interested in. However, this information usually has conflicts. In order to resolve conflicts and get the true information, truth discovery has been proposed and received widespread attention. Many algorithms have been proposed to adapt to different scenarios. This paper aims to investigate these algorithms and summarize them from the perspective of algorithm models and specific concepts. Some classic datasets and evaluation metrics are given in this paper. Some future directions for readers are also provided to better understand the field of truth discovery.
Key words:data mining; truth discovery; conflicting data; source reliability; object truth; ground truth
0 Introduction
The current world has entered an era of information explosion. Social networks are flooded with a large amount of conflicting data, due to the rapid development of the web. Truth discovery acts an important role in resolving conflicts among multi-source noise data since it was first formulated by Yinetal.[1]Truth discovery can benefit many applications that require serious information for decision-making, like social sensing[2-11], information extraction[12-13]and crowdsourcing[14-18]. For example, an online medical system may receive different feedback from many patients. Users on social network platforms can post different observations at any time and anywhere. Answers on crowdsourcing may offer different answers to the identical question. During the COVID-19 epidemic in 2020, rumors surfaced online that drinking cow urine or even consuming poisonous bleach could prevent or treat the virus, and some people became sick and even died from it. Such misinformation is everywhere, and we need to address it urgently.
Truth discovery mainly involves three concepts, namely, source, object and claim. For example, when we search for the departure time of a certain flight online, we would get a lot of related entries. Among those entries, a specific website is a source, such as Ctrip and Fliggy. The departure time of the flight is an object of interest. A time given by a specific website is a claim. Due to the existence of data errors, missing data, outdated data, useless data, and even plagiarism, different sources may offer conflicting claims on one object. The objective of truth discovery is to find the truth for every object by integrating conflicting data.
The straightforward method to conduct truth discovery is majority voting. It takes the claim with the most occurrences as the truth. However, it supposes that every source is reliable equally which is impossible in most cases. In fact, there is considerable variation in quality between different sources.
To distinguish source reliability while conducting truth discovery, tremendous advanced algorithms[19-60]have been developed for various scenarios over the years. Lietal.[22]proposed a confidence-aware truth discovery (CATD) method to deal with the long-tail phenomenon. Wangetal.[23]proposed a multi-truth Bayesian model (MBM) to capture unique features to deal with multi-truth-finding problems. Lietal.[25]proposed dynamic truth discovery (DynaTD), which considered source reliability and truth to change over time. Wangetal.[28]proposed multiple truth discovery (MTD), which considered that an object had multiple truths. Zhangetal.[30]published influence-aware truth discovery (IATD), which considered the relationship between sources. Xiaoetal.[31]proposed a random Gaussian mixture model (RGMM) to represent multi-source data and truths were used as model parameters. Xiaoetal.[33]proposed a method(ETCIBoot) which considered confidence interval estimates. Lyuetal.[36]proposed claim and source embedding model (CASE) to learn the representations of sources and claims. Lietal.[37]proposed adaptive source reliability assessment (ASRA) to convert an estimation problem into an optimization problem. Linetal.[39]proposed domain-aware truth discovery model (DART) to capture the possibility that a source might vary in reliability on different domains. Zhietal.[41]proposed a method(EvolvT) which considered dynamic scenes on numerical data. Yangetal.[42]proposed an optimization-based semi-supervised truth discovery (OpSTD) method for discovering continuous object truths. Yangetal.[44]proposed a probabilistic model for truth discovery with object correlations (PTDCorr). Yeetal.[46]proposed constrained truth discovery (CTD) algorithm. Jungetal.[47]utilized the hierarchical structures among data(TDH) to find truth. Wangetal.[48]proposed a distributed truth discovery framework (DTD). These algorithms have different assumptions and considerations in the form of source relationship, source coverage, source reliability enrichment, object relationship, object difficulty, object importance, object uncertainty, number of truths and original data type. However, they all apply the same principle:when a source always offers true information, it would be more trustworthy; when the information is supported by trustworthy sources, it would be believed to be the truth.
Truth discovery plays an important role in data mining. Although some papers[61-65]have summarized the literature of truth discovery, many new methods and directions have emerged since 2016. Therefore, an up-to-date survey is a necessity in the truth discovery research area. This paper makes a comprehensive investigation of methods in the field of truth discovery and helps readers understand the latest methods and provides up-to-date future directions. In general, this article makes the following contributions.
1) We investigate current truth discovery algorithms and classify these algorithms into an iterative model (IM), probabilistic graphical model (PGM), optimization model (OM), heterogeneous network graph model (HNM), maximum likelihood estimation model (MLEM), which can help readers clarify these algorithms and have a deeper understanding of truth discovery.
2) We conduct a thorough comparison of 20 classic truth discovery algorithms in terms of four aspects,i.e., source, object, claim, and their relationships. Moreover, from the experiment perspective, we also summarize the popular real-world datasets and performance evaluation metrics utilized for method comparison.
3) Although many approaches have been proposed in the field of truth discovery, there are still some issues to be resolved. Based on the survey of the latest techniques, we provide several promising future directions in section 5.
The content is as follows. Section 1 formally defines basic concepts. Section 2 summarizes five main models in truth discovery algorithms. Section 3 analyzes the existing truth discovery methods from four perspectives. Section 4 summarizes the popular real-world datasets and performance metrics utilized in experiments. Section 5 gives some future directions and we conclude the survey in section 6.
1 Definition of Truth Discovery
In this section, we describe several important concepts of truth discovery and give definitions.
1) Sourcesis a data provider. It gives information about objects that it is interested in. Source can be people, website, sensor.
2) Objectois a question which we want to know the answer to, for instance, the departure time of a flight, the author of a book, the director of a movie.
4) Source weight (reliability or trustworthiness)wsis the probability that the claimed value given by sourcesis true.
5) Source copying relationship describes a type of relationship between sources. The information provided by one source may be plagiarized from other sources, which can lead to inaccurate results of truth discovery. For example, one website copies information from another website, or workers copy other workers’ claims in crowdsourcing.
6) Source coverage measures the percentage of objects on which the source provides claims. It is tricky to estimate its reliability when a source coverage is small.
7) Object correlation refers to the relationship among objects. It can be a time relationship, spatial relationship, or a collection of multiple relationships. For example, ifAtakes 0,Bcan only take 0.
8) TimestampTis a complete verifiable data that indicates the specific point in time when a piece of data exists. This concept applies to dynamic environments where data arrives in different timestamps sequentially.
9) Attribute refers to different features of an entity or item and attribute value means the value claimed by the source on the different features of the entity or item.
10) An entity can have multiple attributes. Domains can be divided according to these various attributes, and source quality usually varies among different domains. In fact, no source is an expert in all domains.
Based on these concepts and notations, we give the definition of truth discovery. For a set of objects that we are interested in, conflicting dataVcan be obtained from a set of sources. The target of truth discovery is to get the truthx*of each objecto∈Oby handling the conflicts inV, while estimating the source weights {ws}s∈S.
2 Five Main Models
In this section, we describe five popular models which are common in truth discovery to help readers have a deeper understanding of popular algorithms. The classification of the classic truth discovery methods based on the model is demonstrated in Table 1.
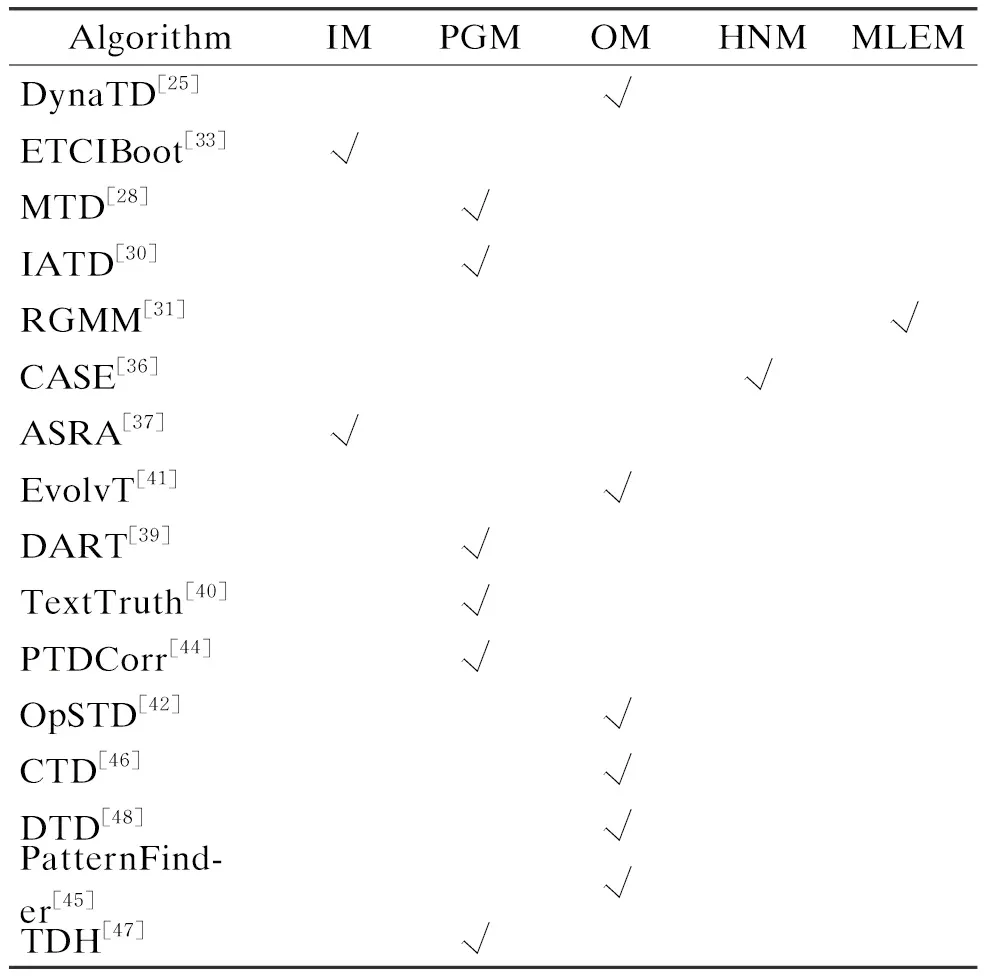
Table 1 Classification of truth discovery methods from model perspective
2.1 IM algorithm
Truth calculation and source reliability estimation are the two most important parts in truth discovery, as truth calculation would become more accurate by calculating the source reliability. The iterative method models the process of truth discovery as a mutual calculation process[1, 22, 25, 29, 33, 37, 48]. Specifically, the general iterative process is conducted by iteratively applying the following two steps until the convergence condition is met. 1) The truth calculation step. Source reliabilities are first initialized, and then truth can be calculated by applying weighted aggregation, where source reliabilities are regarded as the weights. 2) Source reliability estimation step. Source reliability is estimated based on the identified truth.
We take ETCIBoot[33]as an example to better demonstrate the mathematical logic behind the iterative model. In the source weight estimation step, source reliability is considered to be inversely proportional to the total distance between claims and estimated truth, the mathematical formula is
(1)
According to formula (1), when claims are closer to the estimated truth, the source would have a higher weight. In the truth estimation step, ETCIBoot[33]adopted weighted voting for categorical data or weighted average for continuous data. The source weight is obtained from formula (1).
2.2 PGM algorithm
A probabilistic graphical model[14-15,23,44,49]depicts the conditional dependency structure between random variables. Nodes represent random variables, such as source reliability. The directed edges between child and parent nodes represent conditional dependence. Some hyperparameters would also be set as the prior knowledge of source reliability and estimated truth to satisfy probability distributions. For example, Wangetal.[28]adopted the graphical structure of conditional dependence as shown in Fig.1.
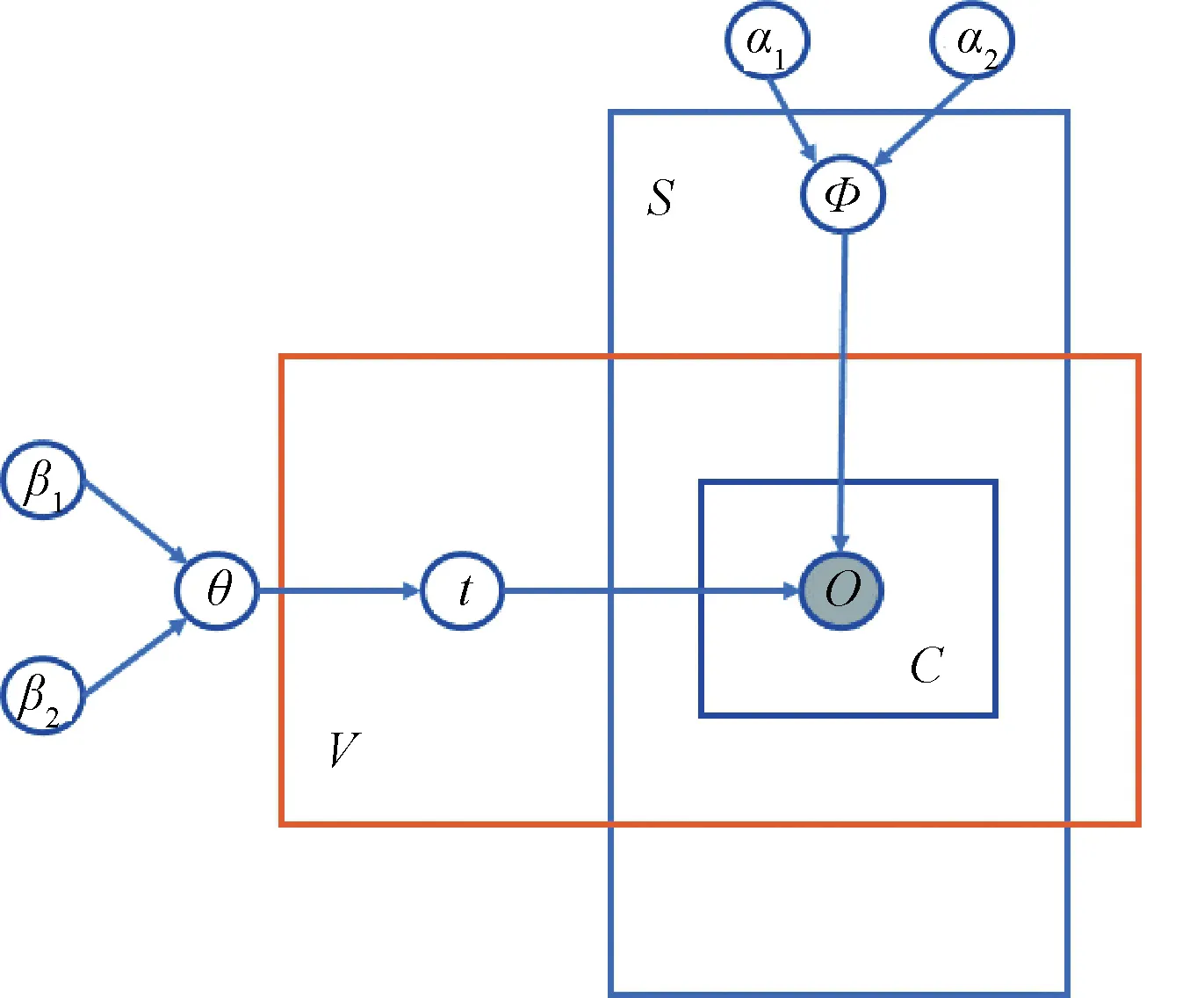
Fig.1 Graphical illustration of probabilistic approach
In Fig.1,Vrepresents the set of all values, andtrepresents the veracity of each value, which obeys a Bernoulli distribution with parameterθ.θis the prior probability whentis true, andtis generated by a beta distribution withβ=(β1,β2).Srepresents the set of all sources, andΦrepresents the reliability of each source, which obeys a beta distribution with the parameter asα=(α1,α2).crepresents the claims of objecto.Xcrepresents the observation of claimcand it is generated from a Bernoulli distribution with parameterΦsc.To get the probability that the value is true and the reliability of each source, Wangetal.[28]established a joint probability formula:
(2)
whereQdenotes the impact of sources’ claim.
By maximizing the joint probabilityp(X,s,t), we can obtain reasonable truth labels on values.
2.3 OM algorithm
The most important part in the OM[21-22,25,50]is the setting of the optimization function. A popular optimization function is
(3)
It reflects the relationship between the source reliability and the distance function, where the distance functiond() represents the distance between estimated value and claims provided by the source. The optimization function can be processed by applying the coordinate descent method[25]in which source weight is fixed in order to infer aggregated results, or by applying the Lagrange multiplier method[48]in whichλis a Lagrange multiplier and the reliability degreewscan be obtained by making the partial derivative of LagrangianLwith respect towsbe 0. Finally, the relationship between the source weight and the distance function can be obtained. Distance function would be 0-1 loss function for categorical data or the square error function for continuous data. By means of minimizing optimization function, the estimated truth can be closer to claims provided by higher quality sources. Relatively, a source can be assigned to a lower weight when its claims are far away from truth.
2.4 HNM algorithm
CASE[36]was the first approach, which adopted a heterogeneous network graph model to get truth. It utilized the interaction between source and target to automatically learn the representations of sources and claims. Heterogenous network can capture the relationships between truth and claim, source and source, and source and claim. The network between truth and claim models the relationship between the global truth and claims. The source-source network models similarity between sources. That is, how often two sources make the same claim on different objects. The source-claim network models the preference of the source who presents a claim on an object. Each relationship is embedded from a sparse high-dimensional space into a dense low-dimensional space and the representations of sources, and claims and truth can be learned from it. The learned representations incorporate the internal structure which is associated with trustworthiness. CASE could be implemented in either semi-supervised learning scenario or unsupervised learning scenario to solve the problem of label sparsity in the actual truth discovery scenarios.
2.5 MLEM algorithm
Reference [11] raised a question on how to obtain the truth when only knowing the claims without source reliability. The authors developed a maximum likelihood estimator to measure truth when the source reliability was unknown a priori. In order to represent multi-source data with different credibility, Xiaoetal.[31]proposed a random Gaussian mixture model (RGMM) formula and transformed the truth discovery problem into maximum likelihood estimation for inferring unknown parameters in RGMM. The maximum likelihood estimation uses the expectation maximization (EM) algorithm to estimate the parameters. Intuitively, what EM algorithm does is iteratively “fulfills” the data by “suspecting” the value of the latent variable, and then re-estimates the parameter by using the suspected value as the truth. The difficulty of EM algorithm is to wisely choose the unknown parameter vector to formulate the likelihood function. After getting the formulation, the EM algorithm achieves the maximum likelihood estimate by iteratively running expectation step and maximization step. In the expectation step, it takes the expected value of the latent variable based on the current data to build the log-likelihood function. In the maximization step, it finds the parameter that maximizes the likelihood function for next iteration. The EM steps are repeated until convergence (e.g., the likelihood function reaches the maximum).
3 Four Comparative Perspectives
Various truth discovery methods are designed for different real-life scenarios based on different assumptions about the sources, objects, claims,etc. As mentioned above, no method could consistently outperform the others in all scenarios. Different scenarios have different unique features. Customized methods in its applicable scenarios could perform better than the other methods. Therefore, it is essential for users to choose the most suitable method given a specific scenario. In this section, we try to give guidance for users by summarizing and analyzing the existing methods from the following four aspects:sources, objects, claims, and their relationships in Table 2.
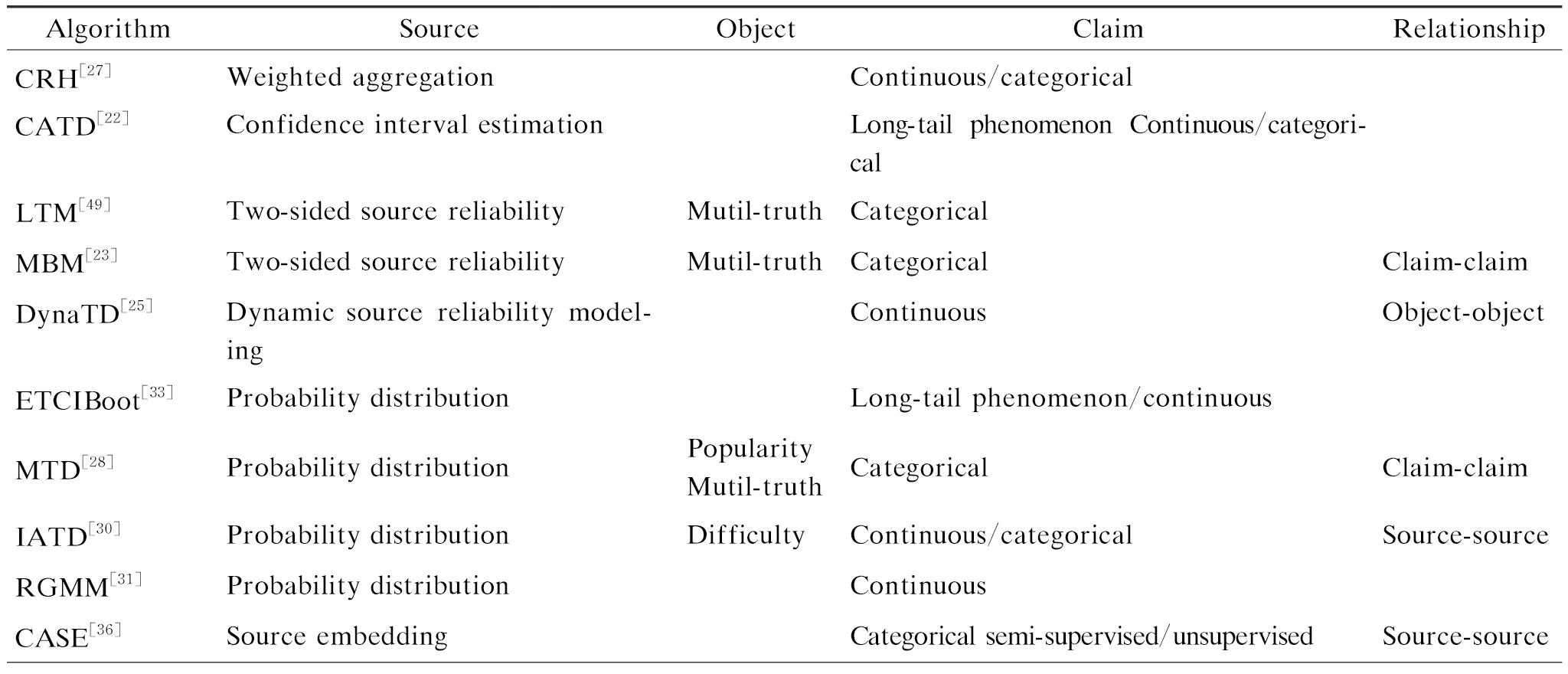
Table 2 Truth discovery algorithm comparison from four comparative perspectives
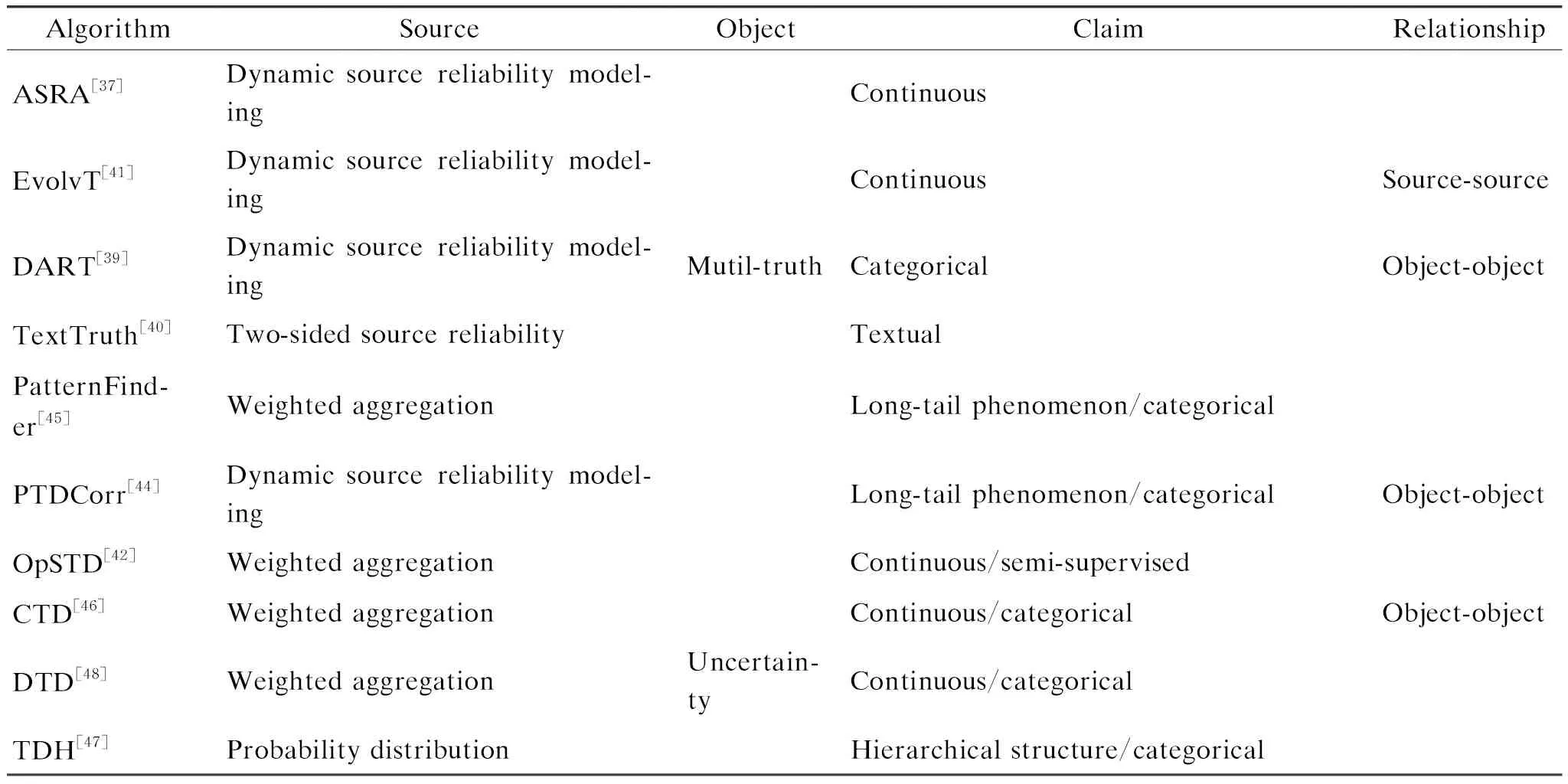
(Table 2 continued)
3.1 Sources
Source reliability estimation is the key process in truth discovery. We discuss how existing methods quantify source reliability in this part. Some advanced considerations regarding source reliability estimation are also introduced.
3.1.1Mathematicalmodelofsourcereliability
1) Weighted aggregation. In Refs. [42, 45-46], source reliability is modeled as weighted aggregation by minimizing the objective function. The reliability of the source is estimated by
(4)
whered(·) is a loss function that measures the distance between estimated truth and claims provided by sources.
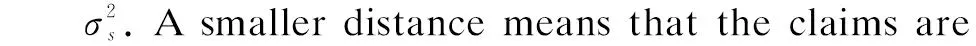
3) Source embedding. Lyuetal.[36]constructed a source-source network and adopted the graph embedding approach to study the representations of sources according to the interaction between sources and targets so as to infer the truth.
3.1.2Enrichedmeaningofsourcereliability
1) Confidence interval estimation. The authors of Ref. [22] observed that most sources only provided a few claims, and a few sources provided claims for most objects, which was called the long-tail phenomenon. They applied confidence interval to measure the reliability of these sources that provided varying amounts of claims.
2) Two-sided source reliability. References[23, 49, 51] utilized the generation process of two kinds of errors (false positive and false negative). These methods modeled two different perspectives of source quality,i.e., precision and recall, to better estimate source reliability.
3) Domain-aware source reliability. Some methods suppose that source has the same reliability on all objects, often known as the source consistency assumption. They ignore the possibility that source quality could vary on different entities or topics. In reality, none of the sources are experts in all areas. Linetal.[39]utilized the amount of data the source provided in different domains to divide the domain expertise of the source for a more precise source reliability estimation. Similarly, when objects can be clustered into sets, Guptaetal.[52]gathered objects into multiple sets and estimated the source reliability for each set of objects. When objects had different properties, Luetal.[16]argued that source reliability should vary on the properties of the objects.
4) Dynamic source reliability. Many existing approaches focus on static data[14, 30-31, 33, 36, 48]. They assumed that a source provided claims for all objects identically and all the data were dealt with simultaneously. However, this assumption is not held in dynamic environment[20, 25, 37, 41, 44], where the information may arrive sequentially, and the truth of objects together with source reliability can change dynamically. Lietal.[25]and Lietal.[37]demonstrated that source reliability changed over time with experimental results on three datasets. In their methods, source reliability was quantified by comparing the distance between sources’ claims and truth. Specifically, at each timestamp, source reliability and estimated truth are calculated based on two parts. The information collected on this timestamp and the results of the previous calculation. The computational cost is effectively reduced as there is no need to revisit information from previous timestamps. Based on Refs. [20, 25, 37], Zhietal.[41]considered not only the variation of source quality over time, but also the source copying relationship under dynamic environment.
5) Source selection. How the source is chosen has a significant impact on the outcome and computational cost of truth discovery[53]. This requires us to find a balance between the accuracy of the result and the calculation cost. Dongetal.[54]considered how to select a subset of sources before integrating the data to balance the quality of the estimated truth and the cost of integration. Yuetal.[19]found that when assigning negative weight to a bad source, it also contributed to the truth discovery result. That is to say, information from a bad source is likely to be wrong.
3.2 Objects
Modeling of objects in truth discovery can capture more accurate results, and there are several types of object modeling.
1) Object popularity. Object popularity refers to the degree to which an object is known to its source and an object is more popular when it is provided by the source more frequently. Fang[38]considered the popularity of objects. The authors used object occurrences and source coverage to measure object popularity.
2) Object difficulty. Object difficulty refers to the difficulty of obtaining information about an object. Gallandetal.[55]studied the different levels of difficulty in obtaining the truth of the object by applying the reliability of each claim. For example, a question can have different levels of difficulty, such as easy, medium, hard. Considering the object’s difficulty allows a better estimate of the source reliability.
3) Object uncertainty. Object uncertainty means that there are differences between objects, and we cannot treat them uniformly. Most algorithms deal with the objects equally, but they ignore the differences among objects. Wangetal.[48]considered the uncertainty of the object from the following two aspects:the difficulty of the object (internal factors) and the number of claims for the object (external factors). Intuitively, if an object is very difficult, it is difficult to infer its true information. Therefore, the object should have a high uncertainty value. On the other hand, if only a few sources provide claims for this object, the estimated truths would be less trustworthy with insufficient data. In this case, the object would also be assigned high uncertainty.
4) Object with multi-truth. Most existing research assumes that each object has only one truth and takes the value with the highest score as the truth. However, this assumption ignores the number of truth, and a single score cannot represent multiple truth values. The traditional single truth discovery problem can be regarded as a special case of the multiple truth discovery problem. Zhaoetal.[49]proposed a Bayesian model that supposed prior distributions of latent variables, which could be used to deal with multi-truth problems. Wangetal.[23]also proposed a Bayesian model that captured the mutual exclusive relation among claims. It also integrated the confidence of data sources on their claims and finer grained replication detection technology into the Bayesian framework to solve the problem of multi-truth discovery. Wangetal.[29]proposed a multi-truth discovery approach which could detect different numbers of truth. The authors utilized the number of truths as an important clue to facilitate multiple truth value problem. Wangetal.[28]proposed a probabilistic approach that added three implications into the truth discovery process which focused on the distribution of positive and negative claims, the implicit negative claims, and the co-occurrence of values in one claim. Linetal.[39]also proposed a Bayesian approach which utilized the sources’ domain expertise and confidence scores of values. It took advantage of a situation where the data source might provide partially correct values for objects. Fang[38]proposed a graph-based approach, which incorporated object popularity, two types of source relations, loose mutual exclusion, and source long-tail phenomenon into graph-based truth discovery process.
3.3 Claims
In this section, we introduce the features of claims that have been considered by truth discovery methods, including data distribution, data type, labeled data.
1) Long-tail phenomenon. In reality, it is common to observe that most objects are mentioned by only a few sources, while a few objects get a lot of data from most sources. Xiaoetal.[33]captured the phenomenon on flight dataset and game dataset. They fitted them into an exponential distribution which was a typical long-tail distribution.
2) Data type. Current methods could be divided into different groups according to the data type they deal with. References [25, 31, 33, 37, 41-42, 44, 56] were designed for continuous data, Refs. [28-29, 36-37] were proposed for categorical data, Refs. [40, 57-59] dealt with text data and Refs. [27, 50] considered heterogeneous data. Some methods[30, 46]were more general, and they could be used for both continuous and categorical data.
3) Hierarchical structure of claims. Existing methods designed for categorical data usually suppose that claimed values are mutually exclusive and each object has only one truth. However, many claims may not be mutually exclusive because there is a hierarchical structure between them[47, 66-67].
4) Semi-supervision. Most truth discovery algorithms are unsupervised and usually employ heuristics to iteratively compute source reliability and truth. However, a part of data labels is available in many real-life situations. Yangetal.[42]employed a semi-supervised framework and defined an optimization framework where object truths and source reliabilities were modeled as variables. It used a regularization term to model the ground truths and set a parameter to control the contribution of the ground truth to the source weight estimation.
3.4 Relationships
Relationships are ubiquitous in conflicting multi-source data. Capturing the data correlations would improve the accuracy in truth discovery. We mainly focus on the following three types of relationships.
3.4.1Source-sourcerelationship
Most truth discovery methods[21, 25, 28, 31, 33, 37, 39-40, 44, 46, 48, 50, 56]suppose that sources are independent, by considering sources are not affected by other sources when making the claims. However, explicit and implicit effects between sources are common in real life. Source relationship can be a replication relationship or a complementary relationship. Pochampallyetal.[51]and Dongetal.[68]inferred source correlations based on the idea that “it was possible that one copies from the other if two sources provided the same false claims”. Zhangetal.[30]took source correlations as prior for truth discovery. Specifically, it blended the credibility of the source and the credibility of its influencer. The model could handle continuous and categorical data, using different distributions. Lyuetal.[36]defined two types of weights in the source-source network which captured the similarity between sources. Zhietal.[41]proposed a model for dynamic truth discovery which captured source dependency by capturing correlation of truths between timestamps.
3.4.2Object-objectrelationship
Many methods assume that objects do not affect each other[25, 31, 33, 48]. In fact, objects may have relations[41, 44, 46]. When limited information could be collected regarding a given object, its truth can still be estimated by related objects. For example, the weather may be similar in two nearby places. Zhietal.[41]found that truth of the same object at continuous timestamps was relevant in a lot of real-world scenarios. Yangetal.[44]proposed an incremental method that considered object correlations in dynamic environments. Yeetal.[46]combined denial constraints, which could express many valid and widespread relationships between objects into truth discovery. This prior knowledge or common sense of the relationships between objects could improve the result of truth discovery.
3.4.3Claim-claimrelationship
The single truth assumption is very common in the field of truth discovery. This is equivalent to the assumption that claims are mutually exclusive. Under this assumption, mutual exclusive relations may exist for categorical data, and mutual supportive relations may exist for continuous data. Wangetal.[29]took similarity between claims into consideration and utilized the uniqueness of numerical data which similar numerical values were more likely to have similar probability of truth. For instance, if number “6” has high reliability, it could increase the reliability of numbers “5” and “7” and may have a negative influence on number 1. Wangetal.[28]used the distribution of positive/negative claims, the cooccurrence of values in sources’ claims and implicit negative claimed value to boost multiple truth value discovery.
4 Overview of Experimental Settings
So far, in truth discovery research area, several real-world datasets have been widely used for method evaluation and comparison. In this section, we demonstrate and analyze those datasets, to provide user guidance. Whenever the dataset is publicly available, we provide the link for download.
4.1 Datasets
1) The weather dataset in Ref. [27] was crawled from three platforms:weather underground, HAM weather, and World Weather Online. Three sources are selected for each website, so there are nine sources in total. Each source provides high, low, and weather conditions of the day. The authors crawled the true weather information for twenty cities over a month as the ground truth.
2) The book-author dataset in Ref. [39] was collected from AbeBooks.com. The dataset includes 54 591 different sources which are registered as booksellers. These sources provide 2 338 559 book author information for 210 206 books. The authors randomly checked the authors of 407 books for ground truth.
3) The stock dataset in Ref. [41] was collected one hour after the stock market closed to avoid the impact of different collection times on every day in July, 2011. It consists of 55 sources and 1 000 stocks. A stock information at a certain time of day is an object.
4) The flight dataset in Ref. [41] collected daily departure and arrival time about 1 200 flights from 38 websites in three airlines over a month. All times are refined to minutes (for example, 7∶30 am translates to 450).
5) The movie dataset in Ref. [39] was collected in July, 2017. The dataset includes 1 134 432 director information for 468 607 movies. There are 2.32 different directors and 3.25 websites for each film on average.
4.2 Evaluation metrics
Though various advanced methods have been proposed over time, common metrics are applied for performance evaluation. We enumerate these metrics in this section.
1) Mean absolute error (MAE) is used for numerical data. It is the average value of absolute error, which can better reflect the actual situation of predicted value error. Lower value indicates better performance.
2) Root mean square error (RMSE) is also applied for numerical data. It is the arithmetic square root of the mean square error. The lower the value, the better the performance.
3) Error rate is applied for categorical data. It is the ratio of value which is misclassified for all the values. The accuracy is equal to 1 minus error rate.
4) Precision describes how many of the estimated values predicted by the algorithm are accurate from the perspective of prediction results.
5) Recall describes how many truths in the test set are selected by the algorithm from the perspective of real results from the perspective of actual results.
6) F1-score is an evaluation metric on categorical data. It is the harmonic average of accuracy and recall which ranges from 0 to 1.
7) Running time quantifies how long it takes for a method to output the truth. Generally speaking, the shorter the running time is, the more efficient a method is. However, some methods sacrifice efficiency for effectiveness.
5 Future Work
Although various approaches have been proposed, there are still several important questions to be explored for the task of truth discovery.
1) Distributed data. Wangetal.[48]proposed a distributed method for processing data. Mass data are distributed on multiple local servers. However, with the widespread use of smart devices, sources are not independent with each other in reality. How to capture source relationships while conducting truth discovery is a big challenge.
2) Source reliability estimation. In crowdsensing scenarios, data may have multiple types. One future work of estimating the source trustworthiness is to leverage multiple data types. Studies have shown that using all the data types together in source reliability estimation is more accurate than estimating each data type separately.
3) Semi-supervised. As we all know, existing truth discovery methods are mostly unsupervised, and there are three semi-supervised studies[21,42,54]. Yinetal.[21]found that even only a small fraction of the ground truth could help identify reliable source greatly. Yangetal.[42]changed the semi-supervised truth discovery problem into an optimization problem. How to design better semi-supervised methods is a future direction.
4) Neural networks. The recent development of deep neural networks has also promoted truth discovery[69]. Multi-layer neural network models can capture the complex dependence regarding source reliability and value accuracy without any prior knowledge. How to apply neural networks to truth discovery is an interesting problem.
6 Conclusions
In this paper, we investigate current truth discovery algorithms and classify them into five main models. We compare 20 classic truth discovery algorithms in terms of four aspects,i.e., sources, objects, claims, and their relationships, to help readers have a deeper understanding of the development of truth discovery. Moreover, we also summarize the popular real-world datasets and performance evaluation metrics utilized for method comparison from the experiment perspective. Finally, we provide several promising future directions based on the survey of the latest techniques.
 Journal of Donghua University(English Edition)2023年4期
Journal of Donghua University(English Edition)2023年4期
- Journal of Donghua University(English Edition)的其它文章
- TSCL-SQL:Two-Stage Curriculum Learning Framework for Text-to-SQL
- Unifying Convolution and Transformer Decoder for Textile Fiber Identification
- Optimization of Insulin Rapid Amyloid Fibrosis Conditions
- Data-Centric Approach to Digital Twin Modeling of Production Lines
- College Basic Development Status Data Management System Based on Data Governance Framework
- Complex Dynamics Analysis of Generalized Tullock Contest