
Attention-based efficient robot grasp detection network?
2023-11-06 06:14:52XiaofeiQINWenkaiHUChenXIAOChangxiangHESongwenPEIXuedianZHANG
Xiaofei QIN ,Wenkai HU ,Chen XIAO ,Changxiang HE ,Songwen PEI,3,4 ,Xuedian ZHANG?,3,4,5
1School of Optical-Electrical and Computer Engineering,University of Shanghai for Science and Technology,Shanghai 200093,China
2College of Science,University of Shanghai for Science and Technology,Shanghai 200093,China
3Shanghai Key Laboratory of Modern Optical System,Shanghai 200093,China
4Key Laboratory of Biomedical Optical Technology and Devices of Ministry of Education,Shanghai 200093,China
5Shanghai Institute of Intelligent Science and Technology,Tongji University,Shanghai 201210,China
Abstract: To balance the inference speed and detection accuracy of a grasp detection algorithm,which are both important for robot grasping tasks,we propose an encoder-decoder structured pixel-level grasp detection neural network named the attention-based efficient robot grasp detection network (AE-GDN).Three spatial attention modules are introduced in the encoder stages to enhance the detailed information,and three channel attention modules are introduced in the decoder stages to extract more semantic information.Several lightweight and efficient DenseBlocks are used to connect the encoder and decoder paths to improve the feature modeling capability of AE-GDN.A high intersection over union (IoU) value between the predicted grasp rectangle and the ground truth does not necessarily mean a high-quality grasp configuration,but might cause a collision.This is because traditional IoU loss calculation methods treat the center part of the predicted rectangle as having the same importance as the area around the grippers.We design a new IoU loss calculation method based on an hourglass box matching mechanism,which will create good correspondence between high IoUs and high-quality grasp configurations.AEGDN achieves the accuracy of 98.9% and 96.6% on the Cornell and Jacquard datasets,respectively.The inference speed reaches 43.5 frames per second with only about 1.2 × 106 parameters.The proposed AE-GDN has also been deployed on a practical robotic arm grasping system and performs grasping well.Codes are available at https://github.com/robvincen/robot_gradet.
Key words: Robot grasp detection;Attention mechanism;Encoder-decoder;Neural network
1 Introduction
The development of intelligent robots has brought great convenience to people’s lives.Intelligent robots can replace humans in labor tasks,such as handling,assembly,palletizing,household service (Wang Q et al.,2022),and logistics sorting.In these applications,robot grasping plays a vital role,in which the position of the object relative to the robot’s gripper must be calculated.Traditional methods are based on model analysis,such as form closure and force closure methods,in which the specific parameters of the object must be known and the calculation process is complicated.Therefore,model analysis methods are difficult to use in unstructured scenarios.In recent years,algorithms based on computer vision and deep learning have become mainstream in the field of robot grasping due to the great progress in artificial intelligence.These algorithms usually use a deep neural network to detect the grasp configuration of the object in a visual image.This process,called grasp detection of the object,can be conducted using system parameters.
Jiang et al.(2011)conducted a pioneering work of grasp detection based on computer vision,giving the definition of correct grasp box,and many subsequent works follow this definition in evaluating performance.Lenz et al.(2015) proposed a two-step grasp detection method based on fully connected neural networks and presented a five-dimensional representation of the grasp configuration.Guo et al.(2017)fused tactile and visual information,and used the sliding window mechanism for grasp detection.Although these early methods achieved good accuracy,they suffered from poor real-time performance,which is important for grasp detection tasks.Therefore,many algorithms optimized for execution speed have emerged subsequently.Redmon and Angelova(2015)proposed a method using the idea of meshing to directly regress multiple grasp configurations of the object.Kumra and Kanan (2017) used ResNet(He et al.,2016)as the feature extraction backbone,extracted features from RGB and depth inputs separately,and fused them in the middle layer.Morrison et al.(2018) proposed a pixel-level grasp detection network with much fewer network parameters and less computation,making it fully meet the real-time requirement of robot grasping.However,although many existing methods have achieved good performance,the balance between the real-time requirement and accuracy still needs improvement.
To meet the real-time requirement of grasp detection and obtain better accuracy,in this paper we propose an attention-based efficient robot grasp detection network(AE-GDN)with an encoder-decoder structure.Inspired by Asif et al.(2019),this network uses DenseBlocks for feature modeling,which is efficient with less computation.In the encoder stages,spatial attention modules are used to improve the detailed information modeling capability.In the decoder stages,channel attention modules are used to improve the semantic information modeling capability.
In the mainstream grasp detection methods,a grasp detection result is regarded as correct if the intersection over union (IoU) between the predicted grasp rectangle and the ground truth (GT) is larger than the threshold.However,as shown in Fig.1,although the predicted rectangles of the top row seem to meet the IoU threshold,if the grasp is performed,a fingertip on one side of the gripper will collide with the object.For clarity,Fig.2 presents the top row of Fig.1.If an IoU threshold of 0.25 is used,as in most methods,the robot will grasp the objects with its fingers at the red bars,which will obviously collide with the objects at the cross points in Fig.2.

Fig.1 Visual comparison of grasp detection results and the ground truth

Fig.2 The collision explanation
The reason is that in the calculation of IoU the central area of the predicted grasp rectangle and the area near the fingertips are treated equally,although the area near the fingertips is obviously more important than the central area.Therefore,when IoU loss is calculated during training,this work parses the predicted grasp configuration into hourglass-shaped boxes,so the impact of the central area of the predicted grasp rectangles is reduced.Note that because the test accuracy given by other methods is based on the IoU calculated by rectangles,for fair comparison,the test accuracy results of this work are also calculated based on rectangles.
The main contributions of this work are summarized as follows:
1.We propose an encoder-decoder structured grasp detection neural network named AEGDN.The accuracy of this model on the Cornell and Jacquard datasets reaches 98.9% and 96.6%,respectively.
2.The IoU item in the loss function is improved by using an hourglass-shaped predicted grasp box instead of a rectangular one when IoU is calculated,which will reduce the influence of the central area in the predicted grasp boxes and create good correspondence between high IoU values and grasping success rates.
3.We deploy the proposed AE-GDN in a robotic arm grasp system with an antipodal gripper,and apply it to grasp 25 commonly used tools and the necessities with considerable shape diversity and complexity.Real-time grasping can be achieved with a fairly high success rate.The proposed AE-GDN algorithm is open-sourced in our GitHub repository at https://github.com/robvincen/robot_gradet.
2 Related works
Robot grasp detection methods based on deep learning can be divided roughly into two categories according to the fundamental mechanism: object detection (OD) and heatmap matching (HM).ODbased grasp detection algorithms can be divided into two-and one-stage methods.The two-stage method includes a region generation network and a grasp box regressor.First,the regions of interest(RoIs)in the feature map are obtained through the backbone,and the grasp boxes are predicted in the second stage.The one-stage method obtains the grasp boxes by directly regressing the features extracted by the backbone.HM-based grasp detection algorithms output a pixel-level grasp configuration instead of the multiple discrete grasp probabilities that are outputted by OD-based methods,and different preprocessing methods need to be executed according to various output formats.
2.1 Methods based on object detection
2.1.1 Two-stage methods
Lenz et al.(2015)proposed a cascaded network based on a sparse autoencoder structure.At first,the potential grasp boxes are exhaustively generated by a simple network to produce a set of rectangular grasp candidates,and in the second stage a deeper network is used to select the best one.Guo et al.(2017)used the network proposed by Zeiler and Fergus (2014)to fuse visual information and tactile information,and discretized the rotation angle for classification.Zhou et al.(2018) proposed an oriented anchor box matching mechanism with ResNet (He et al.,2016)as the backbone.Zhang et al.(2019) extended the method proposed by Zhou et al.(2018),and used an RoI-based method to solve problems when multiple objects to be grasped are stacked together.Dex-Net 2.0,proposed by Mahler et al.(2017),first generates grasp candidates for the depth image,and then chooses the best grasp box by evaluating the grasp quality of the candidate set.Ainetter and Fraundorfer (2021) improved the second stage of the grasp detection network by introducing a semantic segmentation branch and using it to refine the grasp detection boxes.
The two-stage grasp detection method tends to output pretty accurate grasp boxes.However,this is based on sacrificing computational speed,because generating candidate regions in the first stage is timeconsuming and is not suitable for robot grasping tasks with significant real-time requirements.
2.1.2 One-stage methods
One-stage methods directly predict a set of grasp configurations that can be parsed into grasp rectangles in the image.Redmon and Angelova(2015) proposed a regression-based grasp detection method,and AlexNet (Krizhevsky et al.,2012) was adopted as the backbone.This method assumes that each image contains only one grasp object,divides the image into a set of grids,and predicts a grasp configuration for each grid.Kumra and Kanan(2017) proposed a deep convolutional neural network (CNN) to predict robust grasp configurations,demonstrating the potential of multimodal information fusion.A commonly used representation of the grasp configuration includes the grasp rectangle and rotation angle.The rotation angle means the deflection angle of the grasp rectangle relative to the horizontal line.Chu et al.(2018a)discretized the rotation angle into multiple different classes,and used a classification method to predict it.The reason for discretizing the rotation angle is that the angle is a non-Euclidean value (Hara et al.,2017),so the standard regression loss function is not suitable.Although methods using a discretizing mechanism as that used in Chu et al.(2018a) converge more easily during training,their output angles are limited to the preset classification set.Park et al.(2020)used a spatial transformer network(Jaderberg et al.,2015)and ResNet(He et al.,2016)instead of a sliding window mechanism to meet the real-time requirement.
The one-stage grasp detection method does not need to generate RoIs,so it has high inference speed but limited grasp detection accuracy.
2.2 Methods based on heatmap matching
The heatmap matching method outputs pixellevel grasp configurations.Commonly used grasp configuration primitives include the grasp width,rotation angle,object position,and grasp quality score.The heatmap matching method uses the error between the predicted output of these primitives and their corresponding GT values for supervised training.
The GG-CNN proposed by Morrison et al.(2018) is a pioneering heatmap matching grasp detection method.It is a CNN without any fully connected layer,taking only depth information as input,and the numbers of parameters and calculations have been greatly reduced,so real-time performance is guaranteed.Asif et al.(2019) proposed a densely supervised grasp detector with a multi-level CNN structure.This network generates global,regional,and pixel-level grasp configurations,and chooses the best one as the final output.Kumra et al.(2020)proposed a grasp detection network named GRConvNet,which can handle different input modes including RGB,RGB-D,and depth.Based on the GG-CNN of Morrison et al.(2018),GR-ConvNet adds multiple ResBlocks (He et al.,2016) to connect the encoder and decoder,which can provide better mapping capabilities from input to grasp configuration.DD-Net (Wang Y et al.,2021) defines the grasp configuration as a pair of fingertips,and presents a specialized loss function to supervise the training process.
The grasp detection method based on heatmap matching can achieve good balance among robustness,inference speed,detection accuracy,etc.,and has aroused extensive research enthusiasm in the robot grasping community in recent years.AEGDN proposed in this paper is a heatmap matching method.It improves the grasp detection performance mainly through modifications in three aspects: backbone,network architecture,and IoU loss.AE-GDN can achieve fairly high grasp detection accuracy and real-time execution with inference time between 23 and 26 ms.
3 Problem formulation
To better understand the grasp detection algorithm and its role in the overall practical robot grasping task,like other grasp detection papers,we provide a simple definition of the robot grasping problem.In this study,the robot grasping problem is defined as a planar grasping problem,and the image captured by the camera is used to predict the grasp configurations.Then the grasp configurations are converted into grasp commands executed by the robotic arm.
First,the grasp detection algorithm is used to detect the pixel-level grasp configuration,which is noted asG.In this study,Gis defined as follows:
whereW,Θ,andQrepresent three output images with the same size as the input image.Each pixel in these images can be regarded as the width,rotation angle,and grasp quality score of a grasp rectangle candidate.
Second,an argmax operation is performed onQofGto obtain the pixel coordinates of the highest grasp quality score,and then the coordinates are used as the index to obtain the width,rotation angle,and grasp quality score of the grasp rectangle in the pixel coordinate systemGp.In this study,Gpis defined as follows:
wherepdenotes the pixel coordinates (u,v) of the grasp center point,wpis the width of the pixel-level grasp rectangle,θris the deflection angle relative to the horizontal line of the image in the range of,andqis the pixel-level grasp quality score in the range of[0,1].
Third,Gpis converted into the camera coordinate system through the camera’s internal parameters and the depth information captured by the stereo camera,which is noted asGc.In this study,Gcis defined as follows:
wherePdenotes the coordinates (x,y,z) of the grasp center point in the camera coordinate system,wcis the width of the grasp in the camera coordinate system (i.e.,the difference of the opening and closing degrees of the gripper),θris the same as that in Eq.(2) because in this study the eye-in-hand robot grasping system is used,andqrepresents the grasp quality score.
Finally,Gcis converted into the robot coordinate system through external parameters of the robot and camera,which is noted asGr.The definition ofGris similar to that ofGc,and will not be given here.The convertion process fromGptoGrcan be represented as follows:
whereRis the rotation matrix from the camera coordinate system to the robot coordinate system,andTis the translation matrix.Similarly,Rin Transcpis the rotation matrix from the pixel coordinate system to the camera coordinate system,andTin Transcpis the translation matrix.
4 Method
We propose an end-to-end grasp detection CNN named AE-GDN as shown in Fig.3,in which Dense-Blocks (Huang et al.,2017) are used to connect the encoder and decoder.Due to the efficiency of Dense-Block,AE-GDN possesses powerful feature modeling capability and high inference speed.Inspired by CBAM (Woo et al.,2018),spatial and channel attention modules are added to the encoder and decoder stages of AE-GDN,respectively.Because the inputs of the spatial and channel attention modules are different,coming from shallow and deep layers of the network,the capability of AE-GDN to extract detailed and semantic information can be enhanced.During the calculation of traditional IoU loss,the central area of the predicted grasp rectangle and the area near the fingertips are treated equally,leading to bad correspondence between high IoUs and high grasp success rates as shown in Fig.1.In this study,new IoU loss based on an hourglass-shaped grasp box is designed to reduce the impact of the central area in the predicted grasp box.

Fig.3 Model architecture
4.1 Model architecture
Fig.3 shows the model architecture of the proposed AE-GDN,which is an encoder-decoder structured pixel-level robot grasp detection network.The output images,which are the grasp quality score image,rotation angle image,and width image,have the same resolution as the input.Specifically,the three output images have the same resolution,so given the pixel with the highest grasp quality,the width and angle can be known.Note that in this study,we follow the approach of GG-CNN (Morrison et al.,2018) to predict the rotation angle.Here,the rotation angle is not directly outputted;instead,sin(2θ)and cos(2θ)are first calculated and then parsed into the rotation angle image.The reason is that theL2loss function cannot be used directly in the non-Euclidean space of the angle value(Hara et al.,2017).
AE-GDN has three encoder and decoder stages.At the bottom of the encoder-decoder structure,some DenseBlocks are used to enhance the feature modeling capability.DenseBlock is an outstanding computer vision feature extractor;it can facilitate model training,strengthen feature propagation,and encourage feature reuse.Importantly,the number of its parameters and the amount of calculations are small due to its narrow layers;it can meet the realtime requirement of robot grasping.According to its output channel number,DenseBlock has many variants,and this study adopts the variant with 24 output channels.As the number of DenseBlocks increases,the performance of the model will increase,but it will also lead to an increase in the inference time and the number of parameters,which is not conducive to the real-time robot grasping.Therefore,after balancing the pros and cons between the grasp detection performance and the inference time,the number of DenseBlocks selected in this study is 18.
In the downsampling path,the output of each encoder stage is inputted into a spatial attention module to enhance the detail information.A 1×1 convolution layer is used for the output of the last DenseBlock to reduce the channel number.In the upsampling path,three channel attention modules are used to enhance the semantic information.The outputs of the spatial and channel attention modules are fused together,and fed into each decoder stage.The output of the last decoder stage is inputted into the grasp prediction layer.The design of the spatial and channel attention modules is inspired by convolutional block attention module (CBAM)(Woo et al.,2018),but the difference is that AEGDN uses different inputs for spatial and channel attention modules,as shown in Fig.4.To make the network pay more attention to the object in the image instead of the background,this study feeds the features of the encoder into the spatial attention module.To make the network pay more attention to the semantic information in the features,this study feeds the features of the decoder into the channel attention module.Because spatial information is more abundant in the shallower layer and semantic information is richer in the deeper layer(Fang et al.,2022),the spatial attention module is used only in the downsampling path and the channel attention module is used only in the upsampling path.
The parameter number of AE-GDN will change slightly according to different input modes.When the input mode is depth,RGB,or RGB-D image,there are 1.373×106,1.378×106,or 1.380×106parameters,respectively.AE-GDN is smaller in size compared with many works such as GR-ConvNet(Kumra et al.,2020) and DD-Net (Wang Y et al.,2021),and its inference time is between 23 and 26 ms on our graphics processing unit (GPU) workstation,which can meet the real-time requirement of the robot grasping task.
4.2 Loss function
The total loss of AE-GDN is defined as follows:
whereLqualityrefers to the grasp quality score loss function in GG-CNN (Morrison et al.,2018),and using the mean square error (MSE) loss function,it is defined as follows:
whereEis the area of the smallest box that contains both the predicted grasp boxPand GT rectangleG.Uis the union of the predicted grasp boxPand GT rectangleG.
Fig.5 shows the examples of GT rectangleGand the predicted grasp boxPfor calculating GIoU.The left part of Fig.5 shows an example whenGandPdo not intersect,and then we have Eq.(9):

Fig.5 Examples of the ground truth (GT) rectangle and the predicted grasp box for calculating the generalized intersection over union (GIoU)
WhenGandPget closer to each other,Ewill get smaller,so GIoU will get larger,which can provide the gradients needed by model convergence.
The right part of Fig.5 shows an example whenGandPhave some intersection,and then we have Eq.(10):
WhenGandPget closer to each other,Iwill get larger andEwill get smaller,so GIoU will get larger,providing converging gradients.Therefore,no matter whetherGandPhave some intersection or not,the model can always benefit from the supervision of the GIoU loss.
As shown in Fig.1,when the traditional predicted grasp rectangle(the red rectangle in Fig.6)is used to calculate IoU,a high IoU value does not correspond to a good grasp configuration,because the center part of the predicted grasp rectangle is not as important as the area around the gripper.We parse the predicted grasp configuration into an hourglass(HG) box (the orange shadow in Fig.6),and use it asPin Eq.(8).Because the maximum IoU of the HG box and GT rectangle is around 0.5,a small change is made to the loss function,which is defined as follows:

Fig.6 The effect of the hourglass box,which drives the grasp detection result to change from the left(collision between the object and gripper despite a high IoU value) to the right during training.References to color refer to the online version of this figure
In summary,the power of AE-GDN comes mainly from two sources.The first source is the delicately designed model architecture,i.e.,the efficient DenseBlock backbone and the spatial and channel attention modules.The number of DenseBlocks is chosen to balance the model accuracy and inference speed.The spatial and channel attention modules take different features from the encoder and decoder as input,which can extract both detailed and semantic information from the input image.The second source is the creative idea of the hourglass-shaped predicted grasp box,which makes the model pay more attention to the area around the fingertips.
5 Experiments
To evaluate the effectiveness of the AE-GDN proposed in this study,grasp detection and robot grasping experiments are carried out.
5.1 Grasp detection
5.1.1 Datasets and metrics
Grasp detection experiments are carried out on the Cornell and Jacquard datasets.
The Cornell dataset(Jiang et al.,2011)contains a total of 885 pairs of RGB and depth images including 240 objects,so an RGB-D image can also be obtained.The resolution of these images is 640×480,and each pair of images is marked with several grasp rectangles.In our work only 5110 graspable configurations in the Cornell dataset are used.
The Jacquard dataset (Depierre et al.,2018)contains a total of 5.4×104different scenes and 1.1×104different objects,which are all simulation models extracted from a large CAD dataset.The labeled graspable rectangles are generated based on successful grasps in the experimental environment.The Jacquard dataset has more than 1.0×106grasp rectangles.
The current mainstream grasp detection evaluation methods follow the criteria proposed by Jiang et al.(2011),which are also adopted in this work to perform fair comparisons with other methods.The evaluation method judges whether a grasp rectangle is valid based on two conditions.One is that IoU between the predicted rectangle and GT rectangle is≥0.25,and the other is that the angle between the predicted rectangle and the GT rectangle is≤30°.
5.1.2 Grasp detection implementation details
The network in this stduy is built using Py-Torch,the operating system is Ubuntu16.04,the hardware device used for network training and inferencing is an Intel Xeon?ES-1660 v3 eight-core processor clocked at 3.00 GHz,and the graphics card is NVIDIA GeForce GTX1080Ti.
The input data mode can be depth image,RGB image,or RGB-D image.Note that the RGB image and the depth image are aligned,so the depth value of each pixel can truly reflect the depth information.The model is trained using the Adam optimizer,the mini-batch size is 32,the initial learning rate is 0.001,the learning rate decays every 15 epochs,and the decay factorαis 0.5.
Both datasets are divided into two sets with a ratio of 9:1 for training and testing.In the Cornell dataset,there are image-wise(IW)splits and objectwise (OW) splits.The former splits the dataset directly and randomly.The latter divides the dataset according to the type of object.That is,objects in training do not appear in testing.
Because the Cornell dataset is small,data augmentation is used to alleviate overfitting.In the inference stage,we choose the maximum value point of the grasping quality score as the grasp center point,so the corresponding grasp width and angle can be obtained from the two other predicted images.
5.1.3 Evaluation and analysis on the Cornell dataset
For the Cornell dataset,Table 1 shows the performance comparison between AE-GDN and stateof-the-art methods with different input modalities.First,when the modality is depth or RGB-D,the grasp detection accuracy of AE-GDN is better than those of other methods.When the RGB-D input modality is used,AE-GDN can achieve the best accuracy,i.e.,98.9% on the IW splits and 97.9%on the OW splits.Furthermore,Table 1 shows that the highest inference speed of AE-GDN is 44.3 frames per second(FPS),generally between 37.9 and 44.3 FPS.This can meet the real-time requirement of the robot grasping task.Although the accuracy of Zhou et al.(2018)is better than that of AE-GDN when RGB input modality is used,their parameter numbers are much larger.It is worth noting that the inference speed of Kumra et al.(2020) in Table 1 is the reported value from the original paper,which is higher than that of AE-GDN.However,the number of parameters and the amount of calculations of Kumra et al.(2020)calculated with the PyThon package thop are 1.82×106and 9.47 GFlops,which are larger than 1.38×106and 9.19 GFlops of AE-GDN (RGB-D input modality),respectively.Therefore,the theoretical inference speed of Kumra et al.(2020)should be lower than that of AE-GDN.The reason why the reported speed of Kumra et al.(2020) is higher might be that their inference hardware platform is more powerful or their deployment optimization is better.The inference speed of Morrison et al.(2018) is higher than ours because the number of network parameters of this method is only about 6×104.Finally,the results in Table 1 also demonstrate the effectiveness of the attention modules and the HG box modules.At first glance,the spatial and channel attention modules used in this work seem complex,which might influence the speed of the network.However,in fact,the added number of parameters and amount of computations caused by the attention modules are≤3×103and≤0.006 GFlops (can be calculated by the PyThon package thop),and have little impact on the inference speed of the entire network.From Table 1,it can also be seen that no matter whether the attention module is added or not,the difference in inference speed is no more than 2 FPS.If it is converted into inference time,the difference is no more than 1.3 ms.
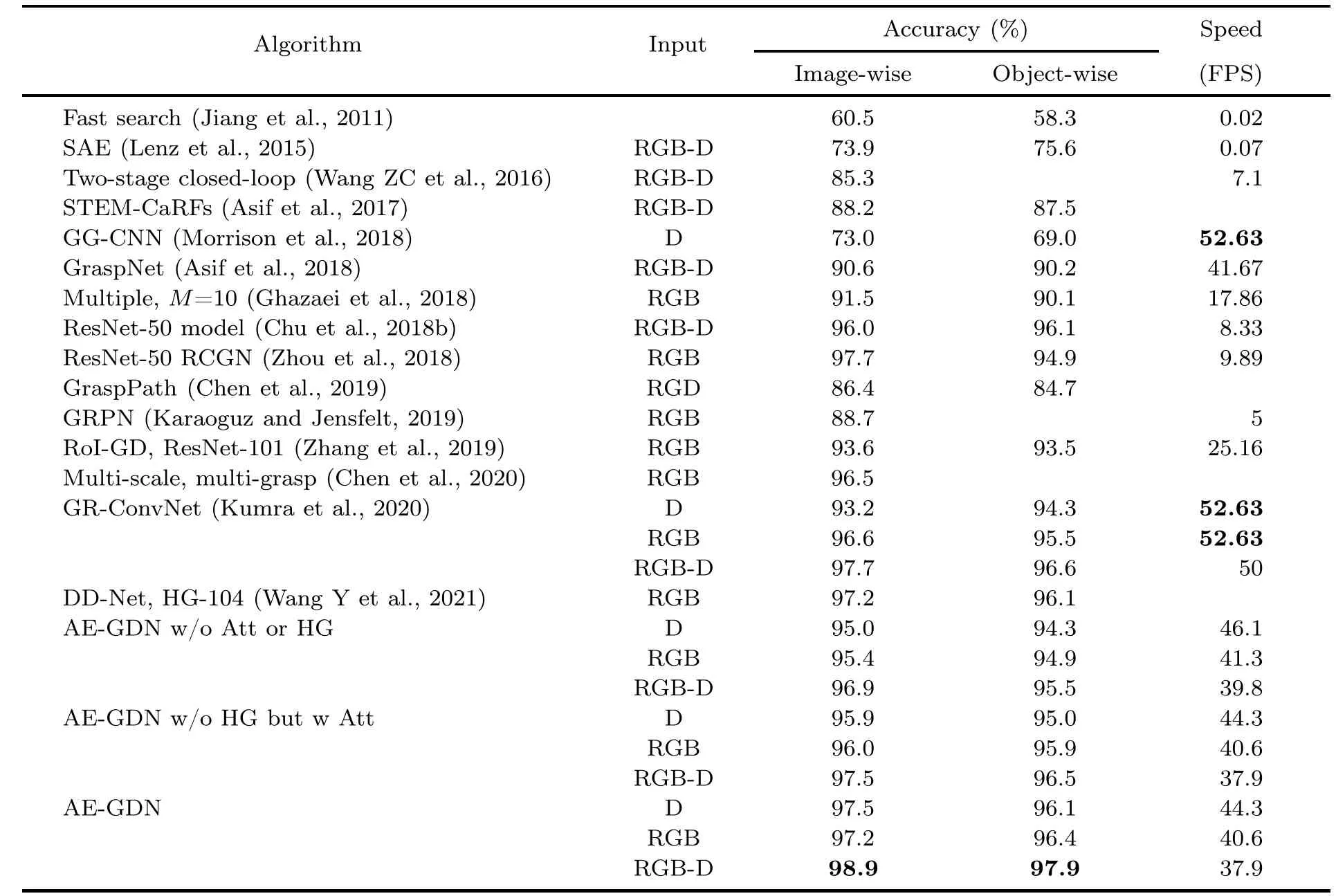
Table 1 Comparison using the Cornell dataset
The accuracy of the model will definitely increase when the number of DenseBlocks increases,as shown in Table 2 and Fig.7.However,more DenseBlocks mean more computation and parameters,and also longer inference time.The accuracy reaches a high level when 18 DenseBlocks are used,and the real-time performance is important for practical robot grasping applications.When the number of DenseBlocks exceeds 18,the accuracy gain is not proportional to the increase of the number of Dense-Blocks,as shown in Fig.7.In this work,AE-GDN uses 18 DenseBlocks to balance the accuracy and inference speed.
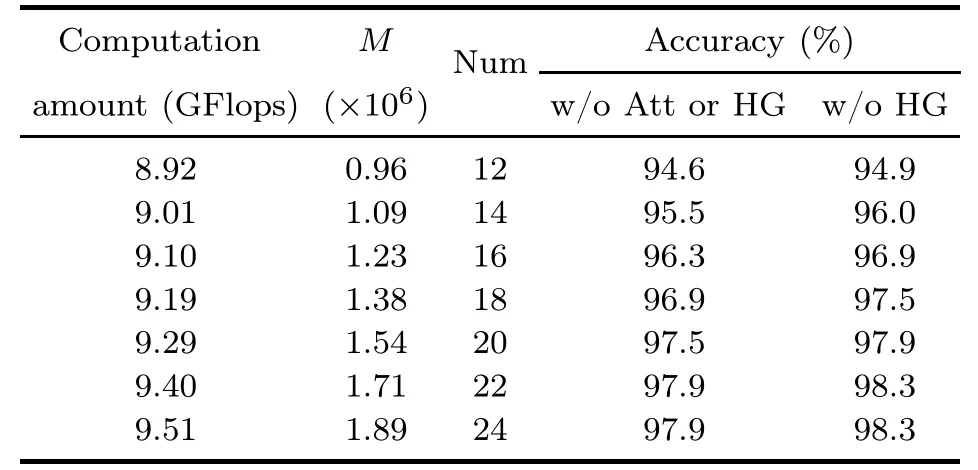
Table 2 Computation amount,parameter number,and image-wise grasp detection accuracy on the Cornell dataset when different numbers of DenseBlocks are used
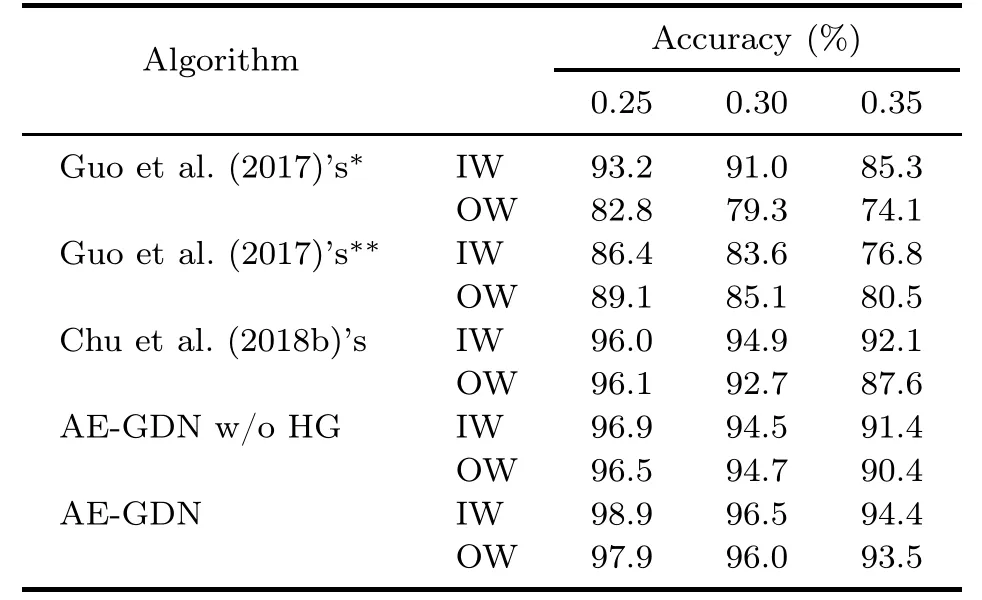
Table 3 Accuracy on the Cornell dataset with different Jaccard indices when the RGB-D input modality is used
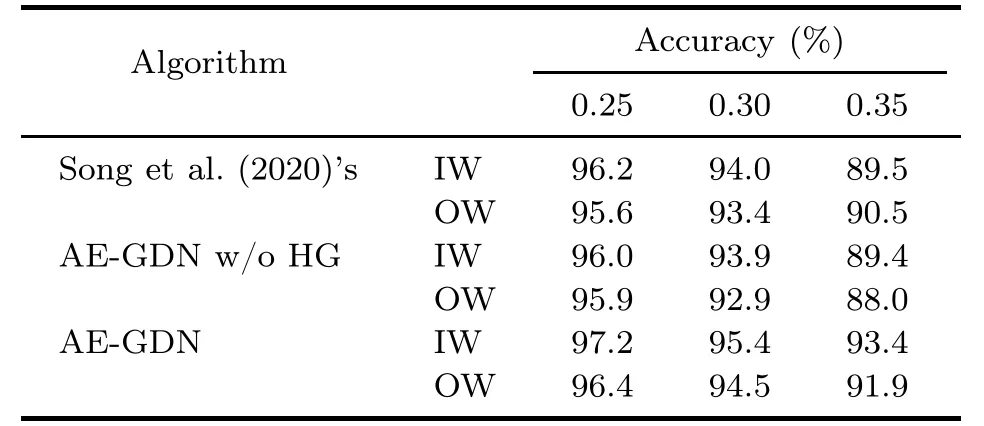
Table 4 Accuracy on the Cornell dataset with different Jaccard indices when the RGB input modality is used
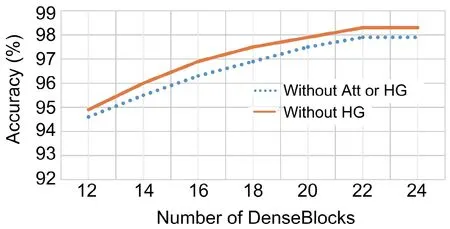
Fig.7 Image-wise grasp detection accuracy on the Cornell dataset when different numbers of Dense-Blocks are used
As described in Section 5.1.1,a predicted grasp rectangle is considered as correct when its IoU value with the GT rectangle is≥0.25.This threshold(0.25) is called the Jaccard index.Obviously,the Jaccard index has a great impact on the performance of the grasp detection algorithm.The HG box mechanism proposed in this work can enhance the robustness of the grasp detection algorithm to the Jaccard index.As shown in Tables 3 and 4,when the Jaccard index becomes larger,the grasp detection accuracy of AE-GDN with HG does not drop significantly.
5.1.4 Evaluation and analysis on the Jacquard dataset
For the Jacquard dataset,Table 5 shows the performance comparison between AE-GDN and stateof-the-art methods with different input modalities.When the input modality is depth or RGB-D,the grasp detection accuracy of AE-GDN is better than those of other methods.When the RGB-D input modality is used,AE-GDN can achieve the best accuracy,i.e.,96.6%.Although the accuracy of Wang Y et al.(2021)’s method is better than that of AE GDN when the RGB input modality is used,its number of parameters is much larger.The results in Table 5 also demonstrate the effectiveness of the HG box mechanism.Similar to the Cornell dataset,the impact of the Jaccard index is tested on the Jacquard dataset,as shown in Table 6;when the Jaccard index becomes larger,the grasp detection accuracy of AE-GDN with HG does not drop significantly.
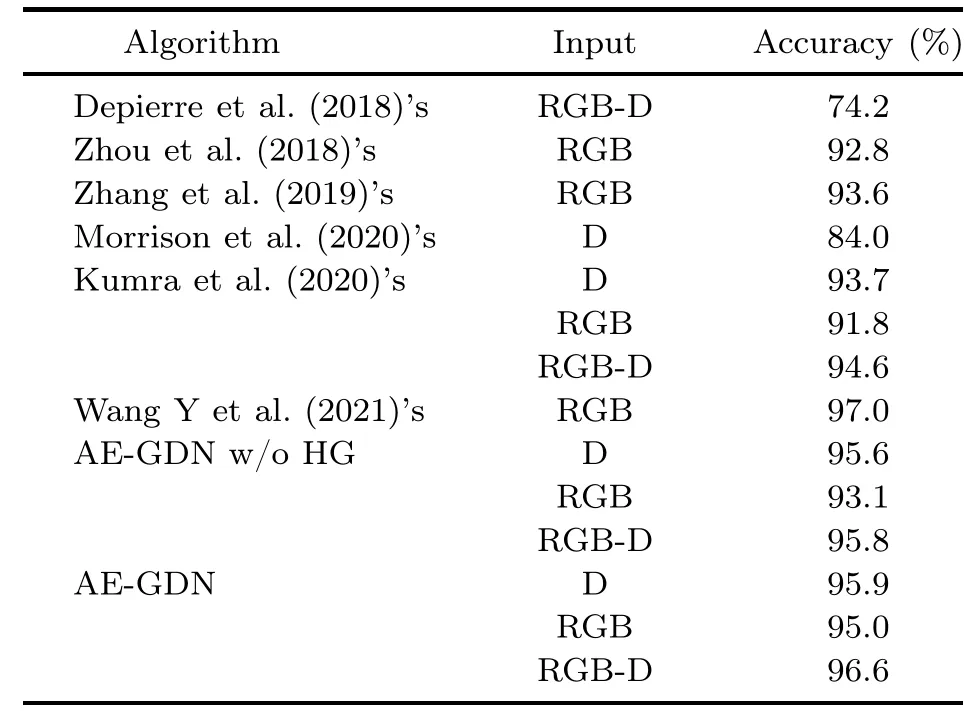
Table 5 Comparison on the Jacquard dataset
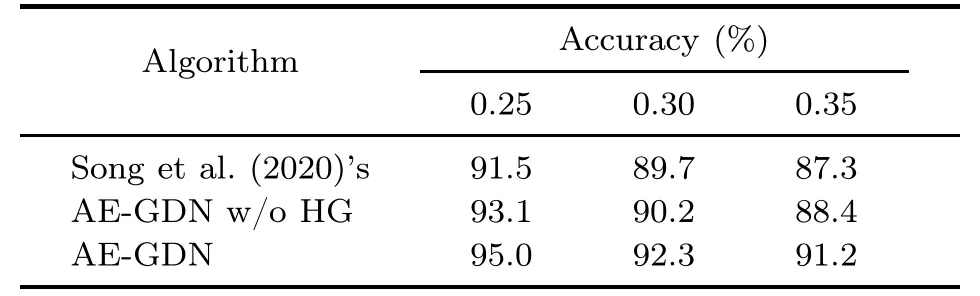
Table 6 Accuracy on the Jacquard dataset using RGB with different Jaccard indices
Some visualization results on the Cornell and Jacquard datasets are given in Fig.8.The column on the right of the two with the same object uses the HG mechanism,which tends to output a more graspable rectangle.

Fig.8 Visualization results on two datasets
5.2 Robot grasp
5.2.1 Grasp objects and metrics
The proposed AE-GDN algorithm is deployed on a practical robotic arm grasp system,which is tested to grasp one of the 25 tools and daily necessities in our laboratory as shown in Fig.9.In the testing process,each object is tested in eight random poses.The evaluation criterion for successful grasping is that according to the grasp configurations detected by AE-GDN,the robotic arm can pick up the object and ensure that the object does not slip off.

Fig.9 Objects for testing the robot grasping system.Each object has eight poses
5.2.2 System setup and implementation details
The robotic arm used in the grasp test is a UR5 collaborative robot,the end effector is a Backyard P80 gripper,and the vision sensor is an Intel RealSense D435i camera that is fixed on the end of the robotic arm.For data and signals that need to be transmitted,we use ROS (Quigley et al.,2009),which can establish communication between various program nodes.The MoveIt_ROS package is used to establish communication with the robotic arm and control the movement.The motion planning algorithm used is ESTkconfigdefault,which is named Expand the Space Tree.
In the practical object grasp test,the position of the object relative to the end effector of the robotic arm needs to be obtained.In this work,the ROS cv_bridge and tf_packages are used to transform the position of the object from the camera coordinate system to the robot coordinate system.The grasping experiment process is to grasp a bunch of objects from a designed area and move them to another.For the same object,multiple postures and positions are tried.The purpose is to verify the generalizability of the grasp detection algorithm to unknown objects and the stability of the robot grasping system.
5.2.3 Evaluation and analysis
We have carried out 200 robot grasping tests,8 times for each of 25 objects,188 of which are successful.Table 7 gives the comparison result of the robot grasping success rate between our approach and mainstream methods,and shows that the method in this work has a high success rate for grasping household objects.The approach proposed by Kumra et al.(2020) has a little higher success rate,because the objects grasped using their approach have lighter weight.Fig.10 gives some visualization results of the practical robot grasping test,and Fig.11 gives an example of the robot grasping process.Table 8 shows the numbers of attempted and successful grasps for different objects.It can be seen that the robot grasping system in this work performs well even for irregularly-shaped objects,but some items are too heavy,and the grasping force of the gripper and the friction of the gripper are inadequate,leading to grasping failures.For example,the plush stick has smooth surfaces and is heavy,and tends to slip during the grasping process.Another example is the wire strippers.The algorithm can detect the correct grasp rectangle on its handle;however,due to the heavy head,the wire strippers tend to tilt during the movement and may drop.

Table 7 Comparison of the success rates for grasping household objects among different approaches
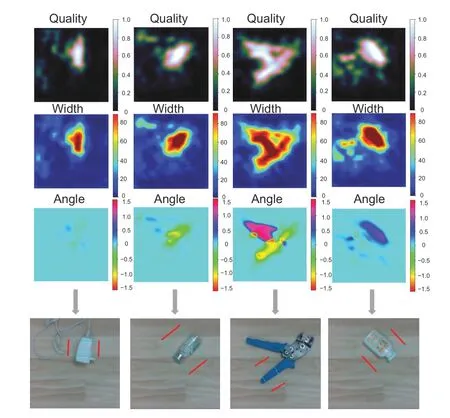
Fig.10 Visualization results in the practical robot grasping test
The robot grasping test is a systematic experiment,and there are many reasons for the 12 grasping failures,such as the object being too large to grasp,the object being too heavy for the end effector,errors in the image acquisition step,low quality of the predicted grasp rectangle,and possible errors in the hand-eye calibration step.Therefore,it is necessary to conduct independent experimental analysis of each of the above possible reasons to improve the success rate of the robot grasping system.
The proposed AE-GDN can also be used in the multi-object scenario.When there are multiple objects in the input image,the output heatmap of grasp quality will have multiple local maxima corresponding to multiple objects.The pixel coordinates of these local maxima can be used as indices to obtain the width and rotation angle of each object.Finally,multiple grasp boxes can be parsed from the combinations of the coordinates,widths,and rotation angles,as shown in Fig.12.After the grasp boxes are obtained,the actual grasping sequence can be arranged according to certain rules.For example,the robot can always grasp the object with the highest grasp quality score or the object closest to the left upper corner of the image until the last object is grasped.Fig.13 gives a multi-object grasping process example.It is worth noting that if the distances between multiple objects are relatively small,although AE-GDN can output correct grasp boxes,the robot may fail to grasp some objects because the algorithm calculates the grasp box of each object independently and does not consider the collision between the grasp box and other objects,as shown in Fig.14.Fig.15 gives an example of a collision between the gripper and a non-target object in a multi-object scene when the distance between objects is relatively small.In addition,AE-GDN does not give the categories of multiple objects,so sequential grasping according to certain category order cannot be realized.Finally,when occlusion occurs,the overlapped objects may be treated as a single object,so AE-GDN may not output enough grasp boxes for all objects,as shown in Fig.16.
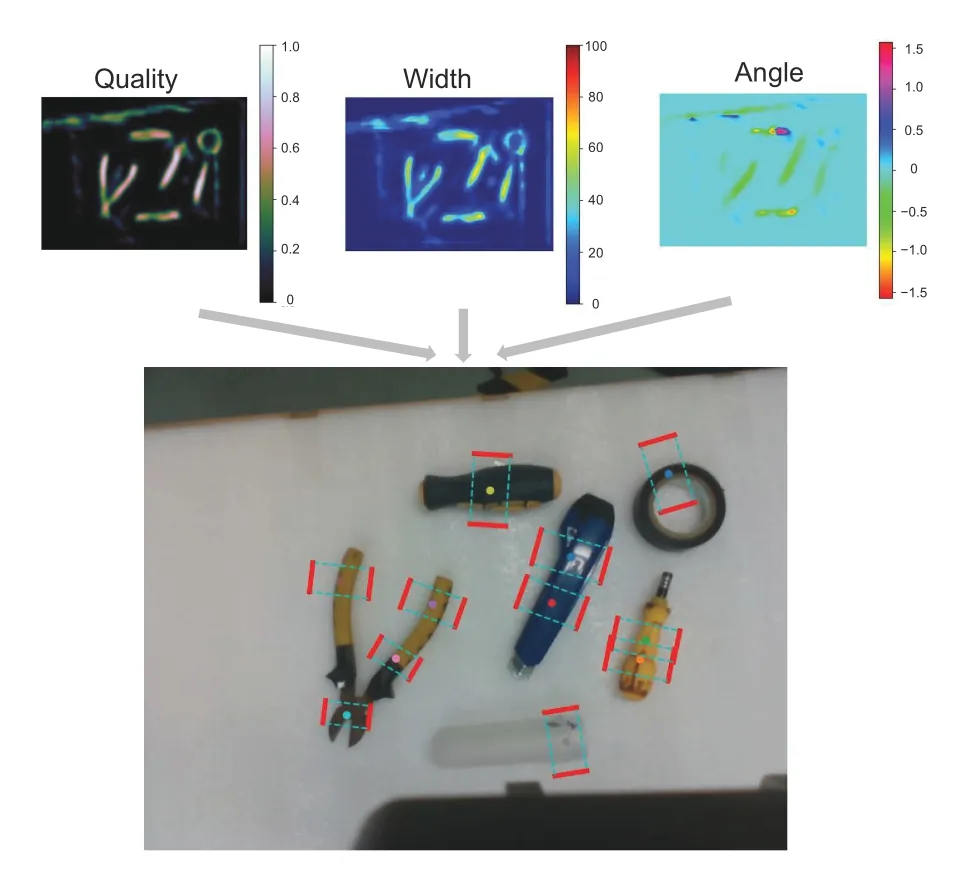
Fig.12 Visualization results of grasp detection in a multi-object scenario

Fig.13 A multi-object grasp process example.The grasp process is from left to right,and then from top to bottom
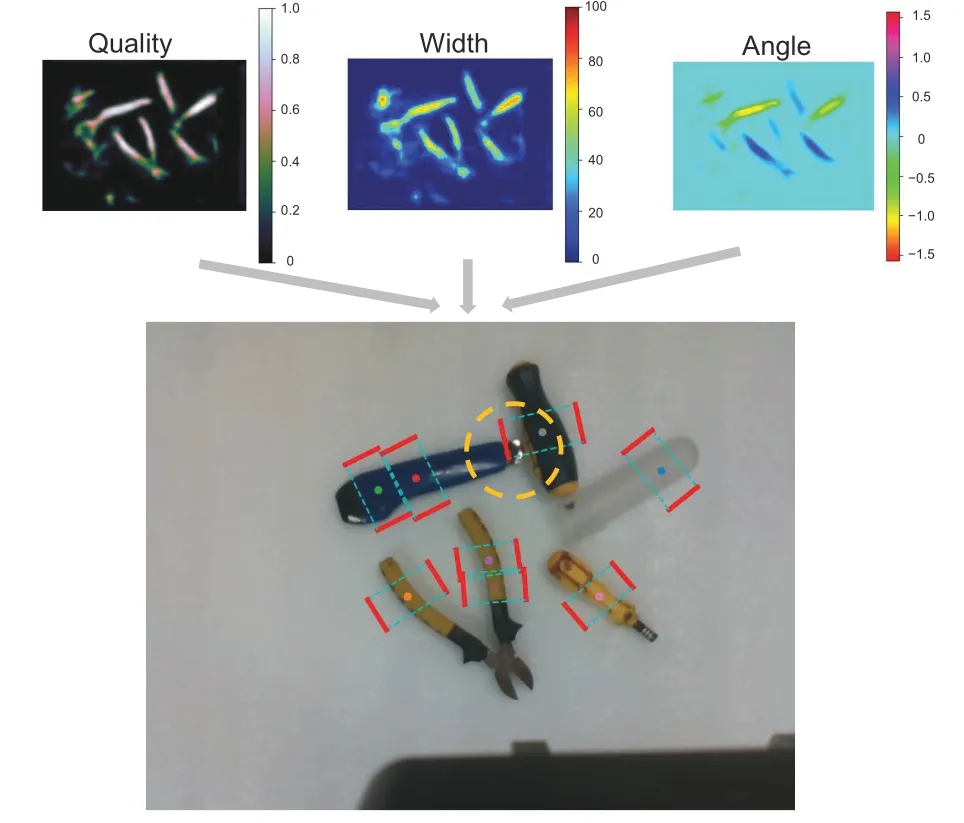
Fig.14 Example of a collision between the predicted grasp box and another object

Fig.15 Example of a collision between the gripper and a non-target object in a multi-object scenario when the distance between objects is relatively small
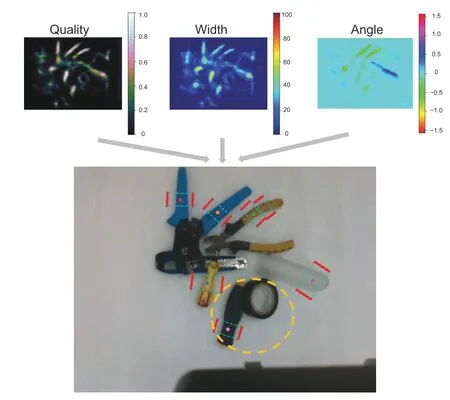
Fig.16 Example of the algorithm not outputting enough grasp boxes for all objects
Robots also have significant requirements for grippers to achieve grasping.Liu et al.(2023) used a soft gripper that can handle various objects of different shapes.In the future,research can be focused on grippers.
6 Conclusions
This paper proposes an efficient pixel-level grasp detection network AE-GDN based on an attention mechanism and an hourglass box matching mechanism.The attention mechanism can enhance both the detailed and semantic information.The hourglass box matching mechanism creates good correspondence between high IoUs and high-quality grasp rectangles.The accuracy of AE-GDN on the Cornell and Jacquard datasets has reached 98.9%and 96.6%,respectively.The inference speed of the proposed AE-GDN can meet the real-time requirement of robot grasping tasks.The proposed AEGDN is also deployed on a practical robot grasping system and performs grasping tasks well.
Contributors
Xiaofei QIN and Wenkai HU proposed the design.Xiaofei QIN and Chen XIAO conducted the experiments.Xiaofei QIN and Changxiang HE analyzed the results.Wenkai HU drafted the paper.Xiaofei QIN,Songwen PEI,and Xuedian ZHANG helped organize the paper.All authors revised and finalized the paper.
Compliance with ethics guidelines
Xiaofei QIN,Wenkai HU,Chen XIAO,Changxiang HE,Songwen PEI,and Xuedian ZHANG declare that they have no conflict of interest.
Data availabilityThe data that support the findings of this study are openly available in the repository at https://github.com/robvincen/robot_gradet.
 Frontiers of Information Technology & Electronic Engineering2023年10期
Frontiers of Information Technology & Electronic Engineering2023年10期
- Frontiers of Information Technology & Electronic Engineering的其它文章
- Correspondence:A low-profile dual-polarization programmable dual-beam scanning antenna array*#
- Correspondence:Uncertainty-aware complementary label queries for active learning?
- Path guided motion synthesis for Drosophila larvae*#
- Wideband and high-gain BeiDou antenna with a sequential feed network for satellite tracking
- Synchronization transition of a modular neural network containing subnetworks of different scales*#
- RFPose-OT:RF-based 3D human pose estimation via optimal transport theory?