
Visuals to Text: A Comprehensive Review on Automatic Image Captioning
2022-08-13 02:08:16YueMingNannanHuChunxiaoFanFanFengJiangwanZhouandHuiYuSenior
Yue Ming,, Nannan Hu, Chunxiao Fan,, Fan Feng,Jiangwan Zhou, and Hui Yu, Senior
Abstract—Image captioning refers to automatic generation of descriptive texts according to the visual content of images. It is a technique integrating multiple disciplines including the computer vision (CV), natural language processing (NLP) and artificial intelligence. In recent years, substantial research efforts have been devoted to generate image caption with impressive progress. To summarize the recent advances in image captioning, we present a comprehensive review on image captioning, covering both traditional methods and recent deep learning-based techniques.Specifically, we first briefly review the early traditional works based on the retrieval and template. Then deep learning-based image captioning researches are focused, which is categorized into the encoder-decoder framework, attention mechanism and training strategies on the basis of model structures and training manners for a detailed introduction. After that, we summarize the publicly available datasets, evaluation metrics and those proposed for specific requirements, and then compare the state of the art methods on the MS COCO dataset. Finally, we provide some discussions on open challenges and future research directions.
I. INTRODUCTION
GIVEN an image, it is natural for humans to quickly understand and give textual description of it while it is not an easy task for machines. The technique for machines to automatically generate textual description of images is called image captioning, which has a wide range of practical applications. Several Android applications have been developed based on the image captioning models [1] to help the visually impaired to retrieve information, to navigate routes, and even to get the sense of their environment.Advanced captioning models are also imbedded in the intelligent robot system to help the robot gain better visual understanding. In brief, image captioning enhances the machine’s ability of multi-modal information understanding and is widely used in different areas such as image analysis and retrieval [2]–[4], human-robot interactions [5], intelligence education [6] and intelligent blind guidance [7].
The goal of the image captioning is to generate textual description for the visual content of an image, which needs to be linguistically comprehensible, syntactically correct and semantically corresponding to the image content. It integrates techniques from multiple fields focusing on mapping the semantics of visuals to texts. This needs not only to detect and identify objects in the image but also have a deep understanding of the semantic content of images including the scene location, object properties and their interactions. Determining the existence, properties, and relationships of objects in an image is not a simple task. To describe the information in a grammatically correct sentence makes the task more difficult.Even, cross modal information communication relies heavily on natural language description, whether it is written or spoken.
The evolution of automatic image captioning is shown in Fig. 1. In the beginning, image captioning attempts to generate simple sentences for images taken under specific scenes [8],[9], for example, to generate a brief description of human activities in a fixed office environment. Apparently, such methods are severely restricted by the scene where the image is taken, far from describing images from our life. Subsequent studies are dedicated to generate descriptions for images taken from various environmental scenes [10]–[12], and early works mainly follow two traditional approaches based on retrieval and template. Retrieval-based methods retrieve sentences from the prepared image-caption database for given images[13]–[15], and template-based methods fill semantic words or phrases detected from visual features into the given template[16]–[18]. The former relies on existing annotations in the training set, while the latter relies on predesigned language structures. However, both types of methods are not flexible enough.
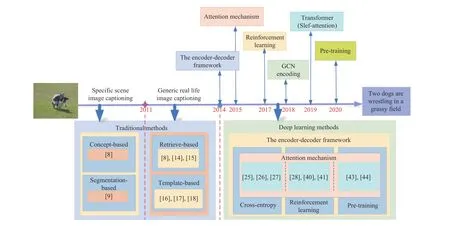
Fig. 1. The evolution of image captioning. According to the scenario, image captioning can be divided into two stages. Here, we mainly focus on generating caption for generic real life image after 2011. Before 2014, it relies on traditional methods based on retrieval and template. After 2014, various variations based on deep learning technologies have become benchmark approaches, and have got state of the art results.
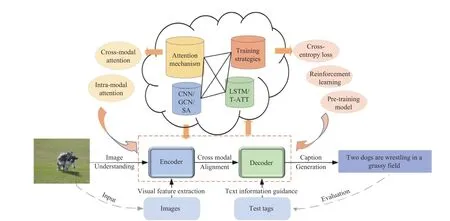
Fig. 2. Overview of the deep learning-based image captioning and a simple taxonomy of the most relevant approaches. The encoder-decoder framework is the backbone of the deep learning captioning models. Better visual coding, language decoding technologies, the introduction of various innovative attention mechanisms and training strategies all bring a positive impact on captioning insofar.
Benefited from recent advances in deep neural networks[19]–[24], deep learning provide effective solutions to visual and language cross-modal modeling, which are also used to boost existing systems. Image captioning based on deep learning has become the focus of research [25]–[30]. From the first work [31] adopting a convolutional neural network(CNN) extract visual representation and feeding it in recurrent neural networks (RNNs) to obtain a sequence, methods have been enriched with the object region features [29], [32]–[34],semantic relation features [35]–[37], attention mechanisms[25], [38], [39], reinforcement learning strategies [28], [40],[41], up to the breakthroughs of self-attention to Transformer[30], [42] and vision-and-language pre-training approaches[43], [44], as shown in Fig. 2. These efforts aim to find the most effective pipeline to create connections between visual semantics and textual elements, and map the visual content of an image into a sequence of words while maintaining its understandability.

Fig. 3. The framework of image captioning model based on retrieval. Preparing a corpus with a large number of image-caption pairs. Retrieval models search for visually similar images to the input image in the query corpus through similarity comparison, then select the best annotation from the corresponding candidates as the output caption.
In this paper, we provide an overview of the image captioning developed in the last ten years. We review the work of the main track image captioning methods, especially those focusing on images taken from real life. Moreover, we mainly focus on deep learning-based methods, and develop a taxonomy of the encoder-decoder framework, attention mechanism and training strategies according to model structures and training manners. Then, we summarize the datasets used in image captioning, from domain-generic to domain-specific benchmarks, as well as the standard and nonstandard metrics. To conclude, we give a discussion of open challenges and suggest future directions.
The organization of the rest of this paper is as follows. In Section II, we review retrieve-based and template-based approaches respectively. In Section III, the deep neural networks are introduced in particular. In this section, we divide the deep neural network-based image caption methods into several subclasses, and discuss classic methods in each subclass respectively. The results of most advanced methods are compared on the benchmark dataset in Section IV. After that,we look into the future work of the image captioning in Section V. In Section VI, we give a conclusion.
II. TRADITIONAL METHODS FOR IMAGE CAPTIONING
In the early days of computer vision (CV), the computer is used to imitate the human visual system and to tell what it was watching. Subsequently, further efforts are made to learn more about the human visual cognition ability, so computers can describe what they see in a simple natural language. The task of image captioning appears, early researchers mainly leverage retrieval-based and template-based methods to enable a computer with the visual learning ability to generate a fluent and understandable sentence for the given image.
A. Retrieval-Based Image Captioning
The main idea of the retrieval-based image captioning is to store a large number of image-caption pairs in a corpus. It first searches out images similar to the input image in the query corpus through similarity comparison. The best annotation caption from the corresponding candidates of retrieved images is selected as the caption of given image. The flow chart is shown in Fig. 31We use the Flick8k dataset as the query corpus in this demo.. Captions generated by these methods can be a sentence that already exists in the corpus, or a sentence composed of retrieved sentences.
In the beginning, assuming that there is always a similar image in the database for the given image, the computer can directly use annotation of the retrieved image as the description of the given image [45]–[49]. Farhadiet al. [45] use the nearest neighbor rule to select the candidate image. It then matches corresponding sentences with the Tree-F1 rule to output the closest sentence. Tree-F1 is a measure that reflects two important interacting components, accuracy and specificity. Ordonezet al. [46] find the most similar matching image by calculating the global similarity between the given image and the image in the database, and transfer the caption of the matched image. Socheret al. [47] focus on actions and subjects based on the word order and syntactic details to retrieve the images described by these sentences. Those methods do not consider the effect of noise. Subsequently, to reduce the impact of visual estimation noise, Mason and Charniak [48] propose a nonparametric density estimation technique, which estimates the word probability density from annotations of the retrieved image, and select the sentence with the highest probability for the given image. And Sunet al. [49] filter text terms based on visual discrimination,group them into concepts according visual and semantic similarities, and then use bi-directional retrieval to output caption.
The above assumption is difficult to meet in practical application. Therefore, in other retrieval-based image captioning methods, a new output sentence is formed by simple processing of retrieved sentences [13], [14], [50], [51]. The typical operation is that extracting a list of expressive phrases from existing annotations according to image similarity, then generating new sentences for the given image by combining relevant phrases elements selectively [13], [50]. Differently from the above method, Hodoshet al. [14] propose a rankingbased method to establish a joint expression space by constructing sequence cores and capturing the core of semantic similarity. Devlinet al. [51] first find a set of k-nearest neighbor (k-NN) images in the training dataset, and then return the consensus caption from the set of candidate captions describing the set of k-NN images.
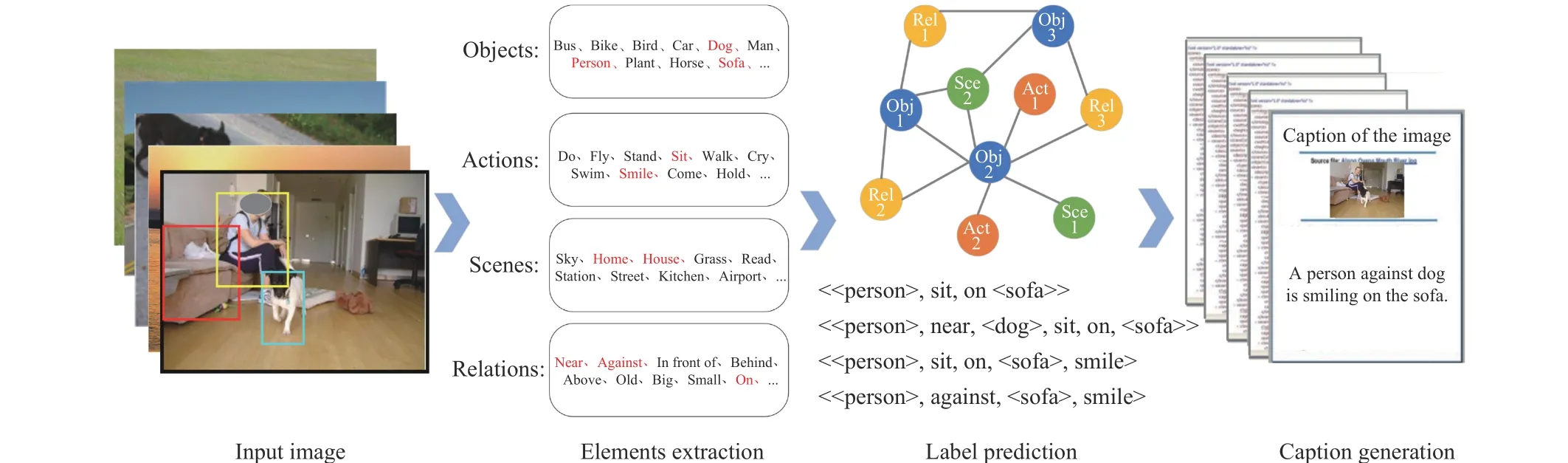
Fig. 4. The framework of image captioning model based on template. The template-based methods are based on a predefined syntax. For a given image, it extracts relevant elements such as objects and actions, predicts their language labels in various ways, then fills them in the predefined template to generate caption.
In essence, the retrieval-based methods generate the description of the given image by choosing the most semantically similar sentences or phrases from the database. The generated captions are usually syntactically correct, fluent in expressing, and close to natural language. However, there are also obvious disadvantages, such as over-reliance on annotations database, which lead to the generated sentences keeping the same syntax expression and expression style as it. It also restricts the image caption to existing sentences or phrases that cannot accommodate new objects or scenes. In some cases, the generated captions may even have nothing to do with the given image.
B. Template-Based Image Captioning
The template-based image captioning can be regarded as a process of syntactic and semantic constraints. Typically, it is a data-driven model, which predefines syntax rules. It detects and extracts related elements such as objects, actions, scenes,relationships and transfers them in semantic representation to predict language labels, then fills the labels in the predefined template to generate captions [15], [45], [52], [53]. The flow path is shown in Fig. 4. The template-based methods can ensure that the grammar of the sentences is correct.
Most of the early template-based captioning techniques extract a single word from the given image [17], [45], [54].The predicted words, such as subjects, predicates, and prepositions, are then linked to generate descriptions. On the first try, Farhadiet al. [45] use support vector machine (SVM) to detect three elements (objects, actions and scenes) as a single semantic word to describe the image. Yanget al. [17] predict the optimal quadruplet (Nouns-Verbs-Scenes-Prepositions)via the hidden Markov model (HMM) [55] to fill the template. Krishnamoorthyet al. [54] use the Subject-Verb-Object(SVO) model to combine the output of the most advanced object and action detector with real world knowledge, to gain the best (subject, action, object). Kulkarniet al. [15] propose to use conditional random fields (CRF) to extract closest words which can be used to describe the image from a large visual annotations database. Xuet al. [52] introduce a dependency-tree structure to embed sentences into a continuous vector space. These methods can preserve the visually grounded meaning and word order.
A phrase carries a larger chunk of information than a single word. Phrase-based sentences tend to be more descriptive than word-based. In template-based image captioning, researchers also try to use phrases to fill templates for generating more descriptive sentences [10], [53], [56]. Liet al. [10] extract phrase-level semantic of objects, attributes and spatial relations based on web-scale n-gram data. Lebretet al. [53]train a purely bilinear model to infer phrases for producing relevant descriptions. Ushikuet al. [56] extract continuous words from the training sentences as phrases, then map image features and these phrases into the same shared subspace for phrases selection. Besides descriptive, phrase-based templates have a great improvement on the syntax.
The template-based captioning models can produce syntactically correct sentences. The descriptions are generally more consistent with the image content than the retrieve-based models. Nonetheless, they are highly dependent on the predefined template. Generally, the template is fixed, the length of generated captions is immutable, and the description content is relatively simple. In addition, the method needs to annotate a lot of objects, attributes and relationships of the image,which make it deal with large-scale data stiffly, and cannot be applicable to images of all fields.
III. DEEP LEARNING METHODS FOR IMAGE CAPTIONING
Recently, deep learning has made great progress in CV and natural language processing (NLP) [4], [43], [57], and they have been widely used in the image captioning. Deep learning can directly map images to texts according to a large dataset,and generate accurate description sentences. Deep learningbased image captioning can also be understood as a probability distribution problem. Given an imageI, and its corresponding annotations marked asS,S=(S1,S2,...,Sn) ,Sirepresents thei-th word of the sentence. Automatic image captioning can be decomposed into two sub-tasks [26]. The first one is to train the cross-modal semantic transfer model,defined asθ. For the given image, the probability of converting it to a text sequenceScan be expressed as
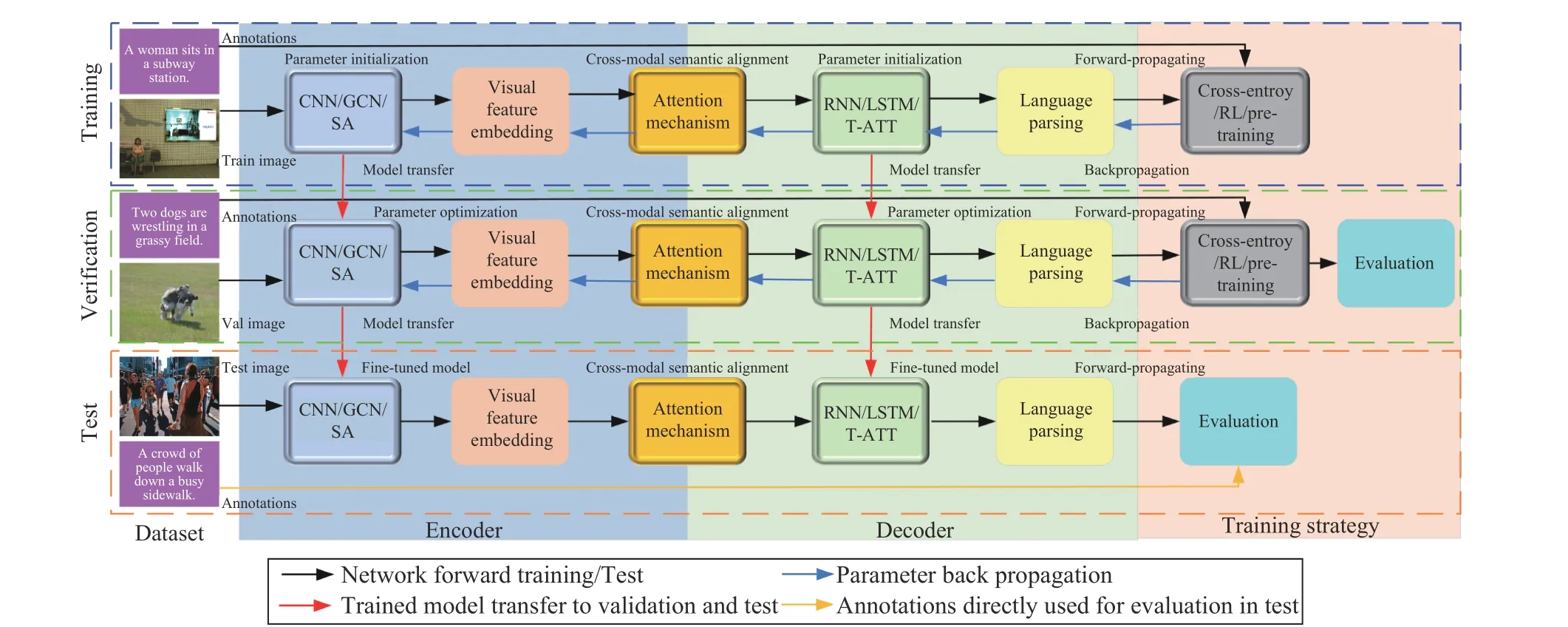
Fig. 5. The flowchart of deep learning methods for image captioning. The trained model is passed to validation and then to test, parameter optimization and fine-tune of the model improves the results gradually, and it is a parameter sharing process.

Since each position has an entire vocabulary of words as candidates, the size of the word search increases exponentially with the length of the sequence. It is not feasible to compute the probabilities of all sequences and then select the sequence with the highest probability. In practice, the beam search is needed to reduce the search space. The detailed training,verification and testing procedures are shown in Fig. 5.
Benefiting from the encoder-decoder framework, deep learning-based methods work in a simple end-to-end manner training as Fig. 2, while they focus on different priorities. In this section, we review such models, divide them into several subcategories based on the encoder-decoder framework,attention mechanism, and training strategy, and then introduce and discuss each subcategory separately. The overall technical diagram is shown in Fig. 6.
A. The Encoder-Decoder Framework
The encoder-decoder framework is the basis of the deep learning captioning models. Vinyalset al. [26] first propose the neural image caption (NIC) generator, a CNN model to generate captions, which is the first work to introduce the encoder-decoder framework into image captioning. The NIC represents the image captioning as a translation problem,where images are regarded as the input and sentences as the output. It serves as the basis for subsequent improvements and a baseline model for performance comparison between models. Generally, CNN with convolution layer, pooling layer and full connection layer is used as the encoder to obtain image features represented as fixed length vectors through matrix transformation. RNN/long short-term memory (LSTM)is used as a decoder to decode visual features to iteratively generate descriptive text sequences. To generate a more human-like sentence, researchers have made many innovative improvements based on the basic framework. In this part, we will summarize these developmental works from the perspective of visual encoding and language decoding respectively.
1) Visual Encoding:The first challenge is that the encoder can learn and provide an effective representation of the visual content. The current visual representation learning methods can be divided into three categories: convolutional representation learning (global or region image feature) as shown in Figs. 7 and 8, graph representation learning (visual relationships) as shown in Fig. 9, and attention representation learning(intra-modal interaction). Here, we mainly share the related work of the three categories of visual representation learning.More details of the attention mechanism will be introduced in the next part.
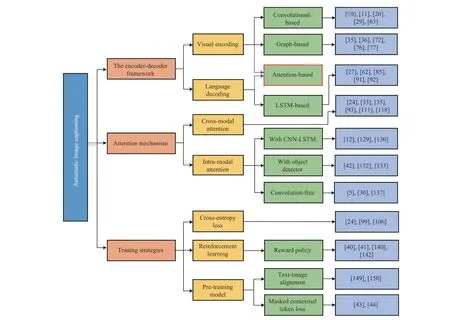
Fig. 6. The overall technical diagram of deep learning-based image captioning. Notice that the self-attention mechanism is can also be used for visual encoding and language decoding. We summarize the attention mechanism in detail in Section III-B.

Fig. 7. Comparison of global grid features and visual region features.Global grid features correspond to a uniform grid of equally-sized image regions (left). Region features correspond to objects and other salient image regions (right).
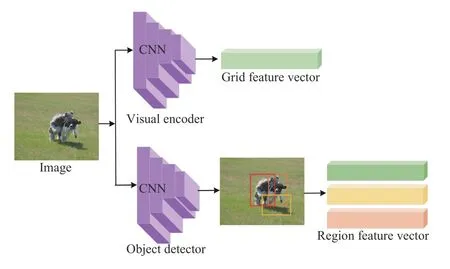
Fig. 8. Two main ways for CNN to encode visual features. For the upper one, the global grid features of image are embedded in a feature vector; for the bottom one, fine-grained features of salient objects or regions are embedded in different region vectors.
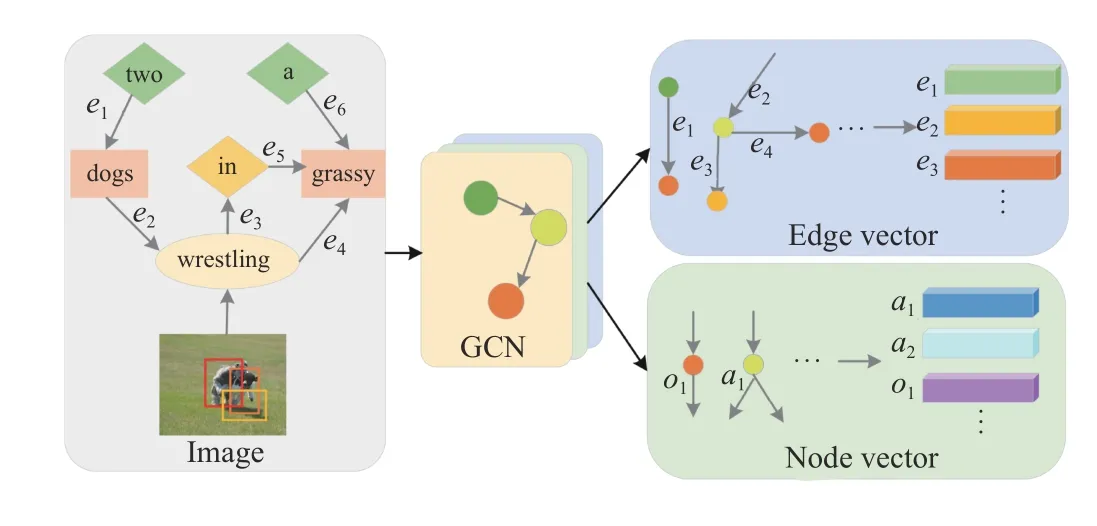
Fig. 9. The framework of graph representation Learning. ei is a set of directed edges that represent relationships between objects, and ai, oi are nodes, which represent attributes and objects, respectively.
a) Convolutional representation learning:Global grid convolutional features are employed in a large variety of image captioning models [12], [58]–[60]. In the NIC [26], the last fully connected layer of GoogleNet is activated to extract high-level and fixed-size representations of visual features,which are then used as a conditional element of the LSTM module to generate a sentence. Differently from NIC, Xuet al. [25] use the output of underlying convolutional layers instead of the final fully connected layer output as the image feature vector. Other methods [11], [12], [61] directly extract activation information from the last pooling layer of ResNet-101/152 pre-trained by ImageNet as image features, which can improve the generalization of the model. For better encoding visual contents, improved CNN models have been widely used. Donahueet al. [62] add a long-term recurrent convolutional networks (LRCN) module after the first two fully connected layers to handle the variable-length visual input. Wuet al. [58] and Zhanget al. [63] obtain global grid features through pre-trained CNN, while learning explicit representation of high-level attributes to guide more accurate captions. Maoet al. [64] connect a multimodal component after the feature layer to merge the visual and language information, which can strengthen the visual-language association. The global grid representations cover all the content of a given image in a uniform division. However, the uniformly fragmented embedding treats all significant and non-significant objects and regions equally, which makes it difficult to generate specific and accurate description.
To have a deeper understanding of the images through fine grained analysis and even multiple steps of reasoning,encoding visual features of significant regions has become a mainstream direction. Karpathy and Fei-Fei [32], and Fanget al. [65] use sub-region of images rather than the full images to reason sentences. Andersonet al. [29], [66] leverage the Faster RCNN [67] to obtain object regions and other salient image regions. Subsequently, based on the Faster RCNN detector, more and more approaches are proposed to encode salient visual regions to obtain high-level semantic information. Dattaet al. [68] learn the potential correspondences between regions-of-interest (RoIs) and phrases in captions,and use matched RoIs as the discriminative condition. To learn the knowledge from external unpaired images and texts,Chenet al. [69] extract regional features from images and classify them using the multiple instance learning (MIL). Kimet al. [70] encode the region features of union, subject and object through a region proposal network (RPN) [67] in dense relational image captioning. Yanget al. [71] use an object’s spatial coherence integration method to concatenate raw visual features of every two overlapping objects. These regional feature encoding methods successfully solve the problem of fine-grained information learning in visual feature encoding.
Besides learning visual representation in terms of global grid or salient region features, these convolutional methods also attempt to detect semantic concepts from image regions,and then encode them into high-level representations. Although great progress has been made, most of approaches only deal with entity regions alone without considering interactions between different regions. This makes it deficient in acquiring the topological structure and paired relationships.
b) Graph representation learning:To further improve the visual relationship and entity structure encoding, many researchers use scene graph to extract high-level semantics and visual relationships, and then utilize the graph convolutional network (GCN) [72], [73] to learn graph representations.Scene graph represents an abstraction of salient objects and their complex relationships, which provides rich structured semantic information of an image. Specifically, it extracts the high-level semantic such as objects, attributes and relationships from region features, and build semantic graph with directed edge to produce relation-aware region-level representations, as shown in Fig. 9.
To prove the relationships between objects are beneficial for representing and describing an image, Yaoet al. [35] propose a GCN-LSTM architecture to obtain visual representations from scene graphs built on spatial and semantic connections for the first time. Yanget al. [74] build a scene graph autoencoder (SGAE) to use the directed scene graph to represent the complex structural layout of both images and sentences.The idea has also been applied in other graph embedding works [36], [37], [75], [76]. Moreover, many graph-based approaches aim to improve the applications of scene graph features [77], [78]. Zhonget al. [79] decompose a scene graph into a set of sub-graphs, and capture semantic elements from each sub-graph to interpret different image contents. Chenet al. [80] use a directed abstract scene graphs without any concrete semantic labels to encode user intention in finegrained and control the diversity of captions. Zhanget al. [81]exploit the semantic coherency between the visual and language modalities to align the visual scene graph to the language graph, and the alignment consensus guides the model to capture both the correct linguistic characteristics and visual relevance. Tripathiet al. [82] close the semantic gap between visual graph and caption graph by leveraging the spatial location of objects and additional human-objectinteraction labels. This obtains a competitive image captioning performance only relying on the scene graph labels.
Although state-of-the-art performance has been achieved based on graph embedding, the scene graph generated by black box generator also causes some challenges for image captioning. One is that generating high-quality descriptions lies more on the captioning models rather than on the scene graph parser [83]. The other is that most scene graph captioning models are still too noisy in generating sentences [84].Constructing a specific spatial relationship scene graph based on the application scene and conditions is correct direction for researches on image captioning. The gap and alignment of semantic between the visual scene graph and the text scene graph also attract more and more attention.
c) Attention representation learning:Many of the latest advanced captioning models gradually replace the traditional CNN-LSTM architecture with a Transformer model based on the self-attention (SA) mechanism. These models take the image captioning task from a sequence-to-sequence prediction perspective. They directly encode images into attention features to model global visual context in each encoder layer,and the process is totally convolution-free. More details about this attention-based visual representation learning can be seen in the Intra-Modal Attention of Section III-B.
As said above, the purpose of improving visual encoding is to extract more useful discriminant information from images.Replacing global grid features activated by CNN with regional features can introduce fine-grained semantic and other highlevel features. Graph representation learning can embed explicit, structural relationships between detected objects,which can guide for more interactive descriptions. Attentionbased visual representation can mine more internal interaction between visual elements. These methods significantly improve the description effect of images, which also enhance the descriptive, diversity and accuracy of generated sentences.However, there are some inherent drawbacks. For example, it is difficult to effectively explain semantic reliability for some scenarios.
2) Language Decoding:Decoder aims to predict the probability of a given sequence of words occurred in the sentence. It deals with the text generation as a stochastic process. LSTM is the most widely used decoder in existing image captioning models [26], [85]. Both the image features and the word embedding vectors are projected to the decoder, and the image features is only input at the first step to inform the LSTM about the image contents. The next word is generated based on the current time step and the previous hidden states. Then the beam search is used to iteratively consider thekbest sentence sets up to timetfor generating sentence candidates of sizet+1, only thekbest sentences among them are reserved during continuous updating, and the best approximate values are as (4). Since the representation of images is the only input for LSTM in the initial stage, it is difficult to contribute to posterior words. It is also prone to the problem of vanishing gradient, which makes the words created in the first place useless for later states. Therefore, the LSTM decoder still faces challenges in generating long sentences. In recent years, there are some improvements with the adoption of attention mechanism. Benefiting from the Transformer model as well as the attention representation learning,Transformer decoder, which only consists of two attention layers, shows its unique advantages in sequence prediction.The details are described in the Intra-modal Attention of Section III-B. Here we focus only on the LSTM-based methods.
To enhance the contribution of image information to posteriori words generation, the first idea is to introduce visual sentinel into the decoder for estimating the probability distribution of the next word based on the previous word and the content of the image [86]–[89]. Jiaet al. [90] and Donahueet al. [62] put visual semantic information as an extra input to each unit of the LSTM block, which considers visual information in every time step. Maoet al. [85], [91] input the global features of the given image and the corresponding sentence. Luet al. [27] use an additional “visual sentinel”vector instead of a single hidden state of the LSTM. These methods are mainly based on unidirectional and shallow LSTMs shown in the left part of Fig. 10. However, its capacity of long sequence learning is limited.
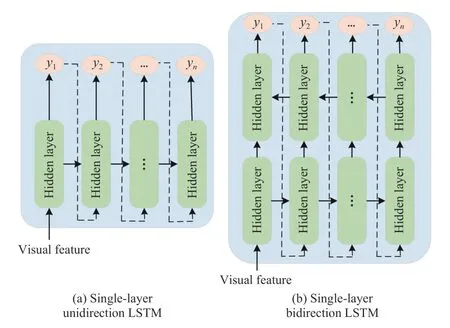
Fig. 10. The singe-layer LSTM strategy for language modeling. (a) Unidirection single-layer LSTM model; (b) Bidirection single-layer LSTM model, which conditioned on the visual feature.
To make better use of both history and future contexts, more directional and deep LSTM variants are proposed to enrich the text decoding. Wanget al. [92] use an end-to-end bidirectional LSTM model to learn both forward and reverse contexts for modeling long-term visual language interaction. Zhenget al. [93] also use a bidirectional LSTMs structure to obtain the global context information. The forward and backward LSTMs simultaneously construct the sentence in a complementary manner. Furthermore, two-stage [33], [94]–[97] and triple-stream [98]–[100] LSTM variants are proposed to explore more visual context and semantic information. Wuet al. [33] decode the text through a GridLSTM and a depth LSTM. The GridLSTM obtains visual features selectively for recalling image content while generating each single word.Deep LSTMs use selected visual features as a potential memory to ensure the caption does not deviate from the original image content. Guet al. [98] design a coarse-to-fine framework with three stacked LSTMs. Attention weights and hidden vectors produced by the preceding stage are used as inputs of the current stage, and they are taken as the disambiguating cues to the subsequent stage as well. Similarly, Kimet al. [99] provide the triplet (topic, object and union) features detected from the region features to three LSTM branches separately. The three branches work collaboratively to predict a related word and its part-of-speech class, leading to relationship-based image understanding. Figs. 11 and 12 show some examples of deep LSTM variants. As can be seen from the figures, the preliminary description is generated in the first layer and then paraphrased into a more diverse and descriptive sentence in the deep layer.
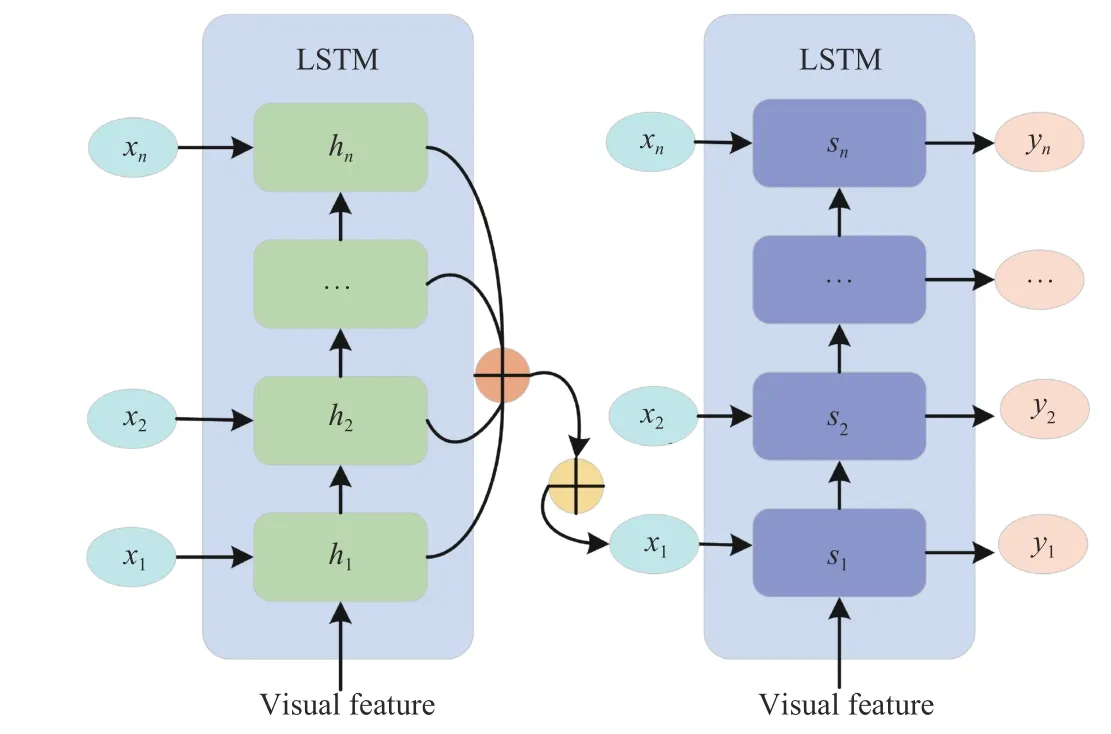
Fig. 11. The two-layer LSTM strategy for language modeling.
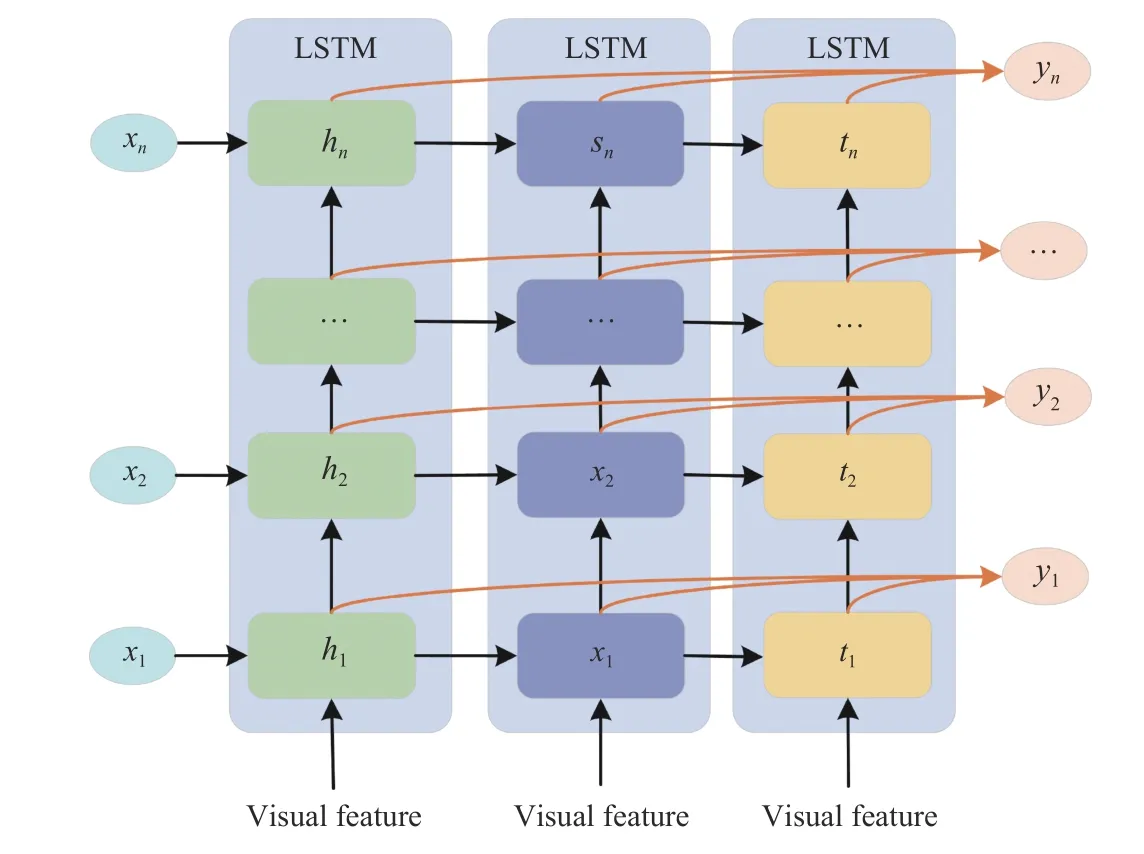
Fig. 12. The triple-stream LSTM strategy for language modeling.
Recurrent models based on LSTM have been the standard decoder in image captioning for many years. The decoder usually trains the complex dynamics of input sequences in a time range. It can remember or use information in the input sequences using internal memory units. The main shortcoming of LSTM decoding is that the LSTM is struggle to maintain long-term dependencies. Above works show that the improvement of the decoder mainly focuses on enriching the information in both the visuals and words when generating the description. These improvements are mainly based on generating captions through autoregressive decoding. Each word is generated in the order of the previously generated words, which may result in issues such as error accumulation,captioning latency, improper semantics and lack of diversity.B. Attention Mechanism
Early captioning models generate sentences considering the scene as a whole rather than the spatial regions relevant to the parts of the words. For understanding and reasoning images more fine-grained, visual attention have been broadly used to interpret related visual information dynamically, and to ground generated words on corresponding image regions. By integrating attention mechanisms into the encoder-decoder framework, the information of the source domain and target domain is aligned to generate a dynamic attention on each part of the input image when generating descriptive words. In this subsection, we summarize the application of different attention mechanisms and methods in terms of the basic framework of image captioning introduced above and discuss how to improve its effect.
1) Cross-Modal Attention:Xuet al. [25] use a dynamic and time-varying visual representation to replace the static global vector and improve the alignment between words and visual content. One drawback of the model is that it utilizes features from the lower CNN layer which may fail to capture highlevel semantic information. To alleviate this issue, more relevant attention improvements have been proposed.
The global-local attention [101], [102] integrates local representation at the object level with global representation at the image level. Semantic attention [38], [103]–[106] integrates semantics to form a feedback connecting the top-down and bottom-up computation, which can focus on the key and various aspects of the image synchronously. Spatial and channel-wise attention [107]–[109] is also used to select semantic attributes on the demand of the sentence context.Adaptive attention [27], [110]–[113] with an additional visual sentinel, decides when to rely on visual signals (for visual words) and when to just rely on the language model (for nonvisual words). Context attention [36], [114], [115] focuses on different locations of the input image according to contextual regions, and the current generation state. Specific visual objects, implicit visual relationships and visuals that have been previously interpreted can be taken into account.Memory-enhanced attention [116]–[118] keeps all the information of previously generated words in a memory storage.Hierarchical attention [119]–[122] is able to learn different concepts at different layers. Low-level concepts are merged into the high-level ones, and low-level features are passed to the top to predict words as well. Deliberate attention [123] is proposed to relieve the exposure bias. Generally, the first attention layer provides the hidden states and visual attention for generating a preliminary caption, while the second deliberates residual-based attention makes refinement. Visual relationship attention [71], [124], [125] extends the attention mechanism from region to relationship via contextualized embedding for individual regions. It is a parallel attention,which can both extract adjacent relationships and capture the feature of adjacent spatial layouts. Recurrent attention [126],[127] introduces continual learning into image captioning, and it considers the transient nature of vocabularies in continual image captioning, especially for disjoint vocabularies.
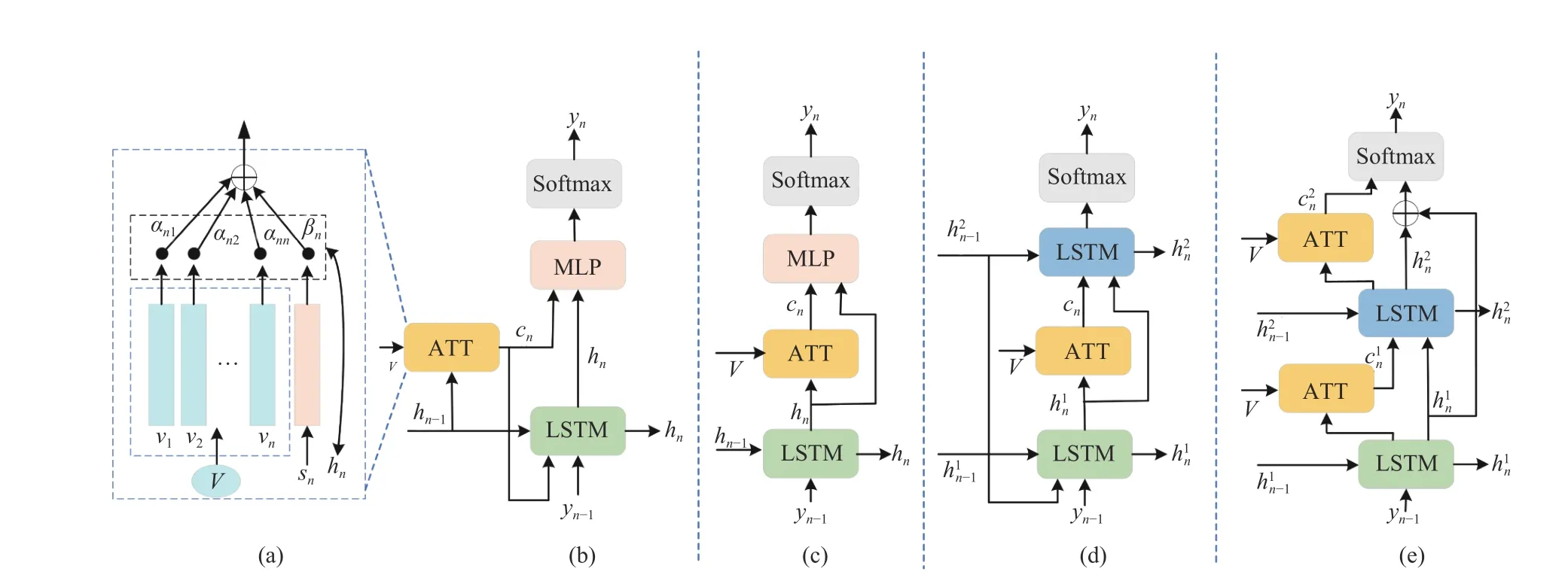
Fig. 13. The common structure of cross-modal attention used for image captioning. (a) The framework of attention mechanism proposed in the Show, Attend and Tell model [25], which be widely used in cross-modal attention for image captioning; (b) The attention used in single-layer LSTM; (c) The attention used as a visual sentinel in single-layer LSTM; (d) An attention layer used in two-layer LSTM; (e) Two-layer LSTM with dual attention. .
The cross-modal attention mechanism is designed to discover the region-level, semantic-level, visual context, and even higher-level visual relationships alignment between visual information and linguistic features. The application of these cross-modal attention mechanisms is demonstrated in Fig. 13.Inspired by the application of self-attention in machine translation, self-attention models have been used in image captioning to explore the interaction of intra-modal information.
2) Intra-Modal Attention:Differently from above crossmodal attention integrated with the CNN-LSTM framework,intra-modal attention interaction methods are mainly based on the self-attention (SA) proposed in Transformer [128].Transformer is an encoder-decoder framework consisting only of multihead self-attention mechanisms, which has a stronger capability of long sequence features capture and parallel computation compared with the CNN/RNN model. The selfattention mechanism reduces dependence on external information and can capture the internal interaction of features.
The development of intra-modal interaction learning can be divided into three stages. In the first stage, transformer encoder or decoder works with the traditional CNN-LSTM framework [12], [129]–[131], as shown in Fig. 14. Based on CNN encoder, Zhuet al. [131] use the Transformer decoder with stacked self attention to replace the LSTM decoder, which can solve the inherent cross-time sequence problem in the LSTM decoder. The new decoder can memorize dependencies between the sequences, and is trained in parallel. On the contrary, Banziet al. [130] build an encoder, which combines a self-attention mechanism with contrastive feature construction. The self-attention encoder aggregates visual information of each image group, captures the difference information between them, and finally generates context-aware captions.
Furthermore, the whole Transformer structure is used with object detected features and to guide the caption decoding[42], [132], [133], as shown in Fig. 15. Yuet al. [42] extend Transformer to a multimodal Transformer to model the intramodal interactions. Object relation Transformer (ORT) [132]and Geometry-aware self-attention (G-SAN) [133] introduce geometric attention into standard self-attention, which can explicitly and efficiently consider the relations of geometry and spatial between objects. Entangled attention (ETA) [134]implements the multi-head attention in an entangled manner to leverage the complementary nature of visual and semantic information in attention operations. Meshed-memory Transformer (M2-T) [135] learns multi-level representation of the region relationships according to the prior knowledge. Duallevel collaborative Transformer (DLCT) [136] uses a dualway self-attention to explore the intrinsic properties of these two features taking geometric information into account.Although these models can obtain competitive captions, they are completed based on CNN image preprocessing, without overcoming the limitations of CNN in global context modeling.
Moreover, the model is used totally convolution-free. Liuet al. [30] consider a sequence-to-sequence prediction perspective, and propose a caption Transformer that takes the sequentialized raw images as input, just as shown in Fig. 16. It can model global context at every encoder layer from the beginning, completely eliminating convolution and recurrent.The intra-modal interaction between image patches in the encoder and the “words-to-patches” cross-modal attention in the decoder are all effectively utilized. The same idea is further effectively verified in other works [5], [137].
Based on the Transformer [128], the self-attention mechanism improves the main disadvantage of recurrent models that it is hard to maintain long-term dependencies between the generated words. It has been established as an effective method for modeling the relations between image regions,caption words and the state of language prediction model. The intra-modal interaction of visual, text, and the cross-modal semantic alignment between visual and text are all successfully explored and leveraged.
C. Training Strategies
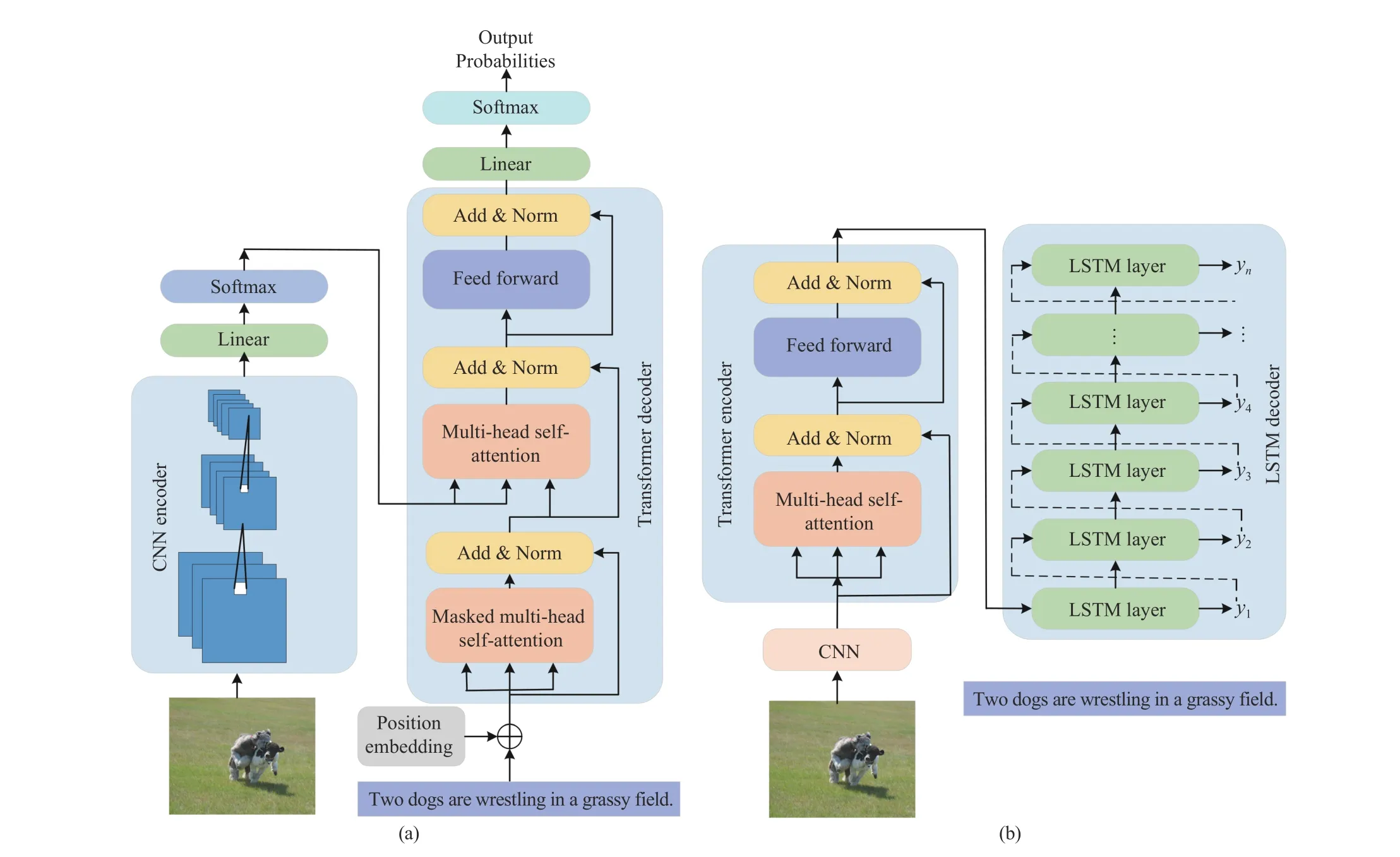
Fig. 14. The common structure of intra-modal attention used for image captioning in the first stage, the Transformer model works with the traditional CNNLSTM framework. (a) is the framework of CNN-Transformer decoder, and (b) is the framework of Transformer encoder-LSTM.
The image captioning model usually generates a caption word by word sequentially, according to the words generated in the previous step and the visual features. In fact, exporting each word is a sampling process. At each step, the output word is sampled from a learned distribution over the annotation vocabulary. The beam search algorithm is the most effective sampling strategy in image captioning. It selects the sequence with the highest probability at each step as candidates and finally outputs the one with the highest probability, rather than output the word in each step. The beam search is often used with different training strategies. In this section, we elaborate on the existing training strategies,which are classified into cross-entropy loss, reinforcement learning, and pre-training model.

wherePis the probability distribution calculated from the language model, and V is the representation of visual features.Hence, in each time step of the training, the possibility of the negative log-likelihood of the current word can be minimized based on previous annotation words. The cross-entropy loss operates at the word level and optimizes the probability of each word in the ground-truth sequence, but not taking the longer range dependencies between generated words into account.
Most deep learning methods of image captioning are trained setting with the cross-entropy loss. Previous models, such as NIC [26], Show, Attend and Tell [25], Semantic Attention[114], SCA-CNN [107], Adaptive Attention [27], rely only on the loss for training. These traditional training settings with cross entropy suffer from the problem of exposure bias. This enables the model to generate safer descriptions of the given image. When two images are similar in scene but not in detail,the model tends to generate a rough description. However, this causes the specific details of the image to be ignored. To tackle this problem, deep reinforcement learning strategies have been proposed to alleviate the exposure bias problem during cross-entropy training.
2) Reinforcement Learning:The reinforcement learning(RL) [138] paradigm is designed to overcome the limitations of word-level training of the cross-entropy with a sequencelevel training. It also leverages the beam search and greedy decoding to calculate the loss gradient as follows:

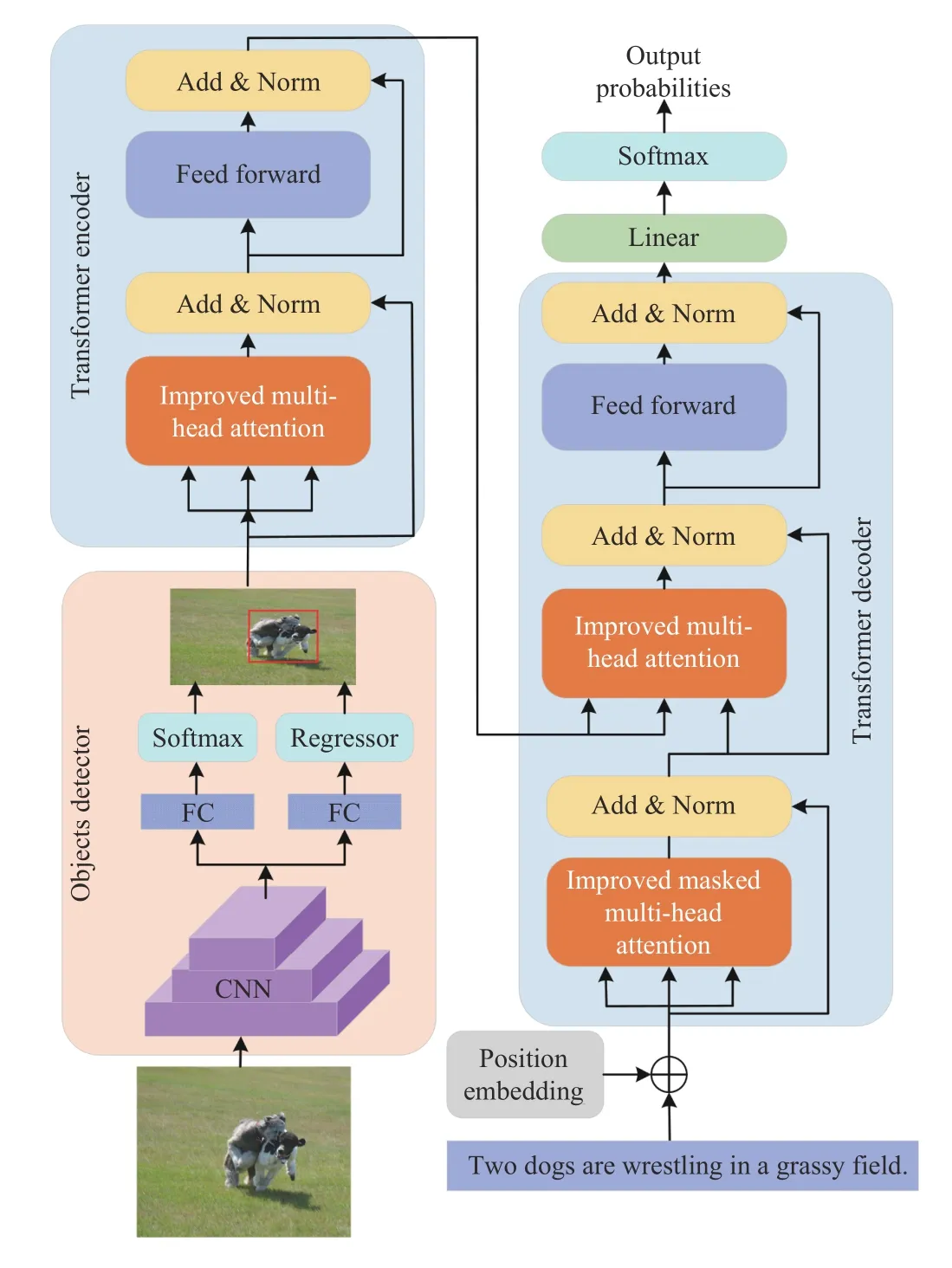
Fig. 15. The framework of intra-modal attention used with object detected features.
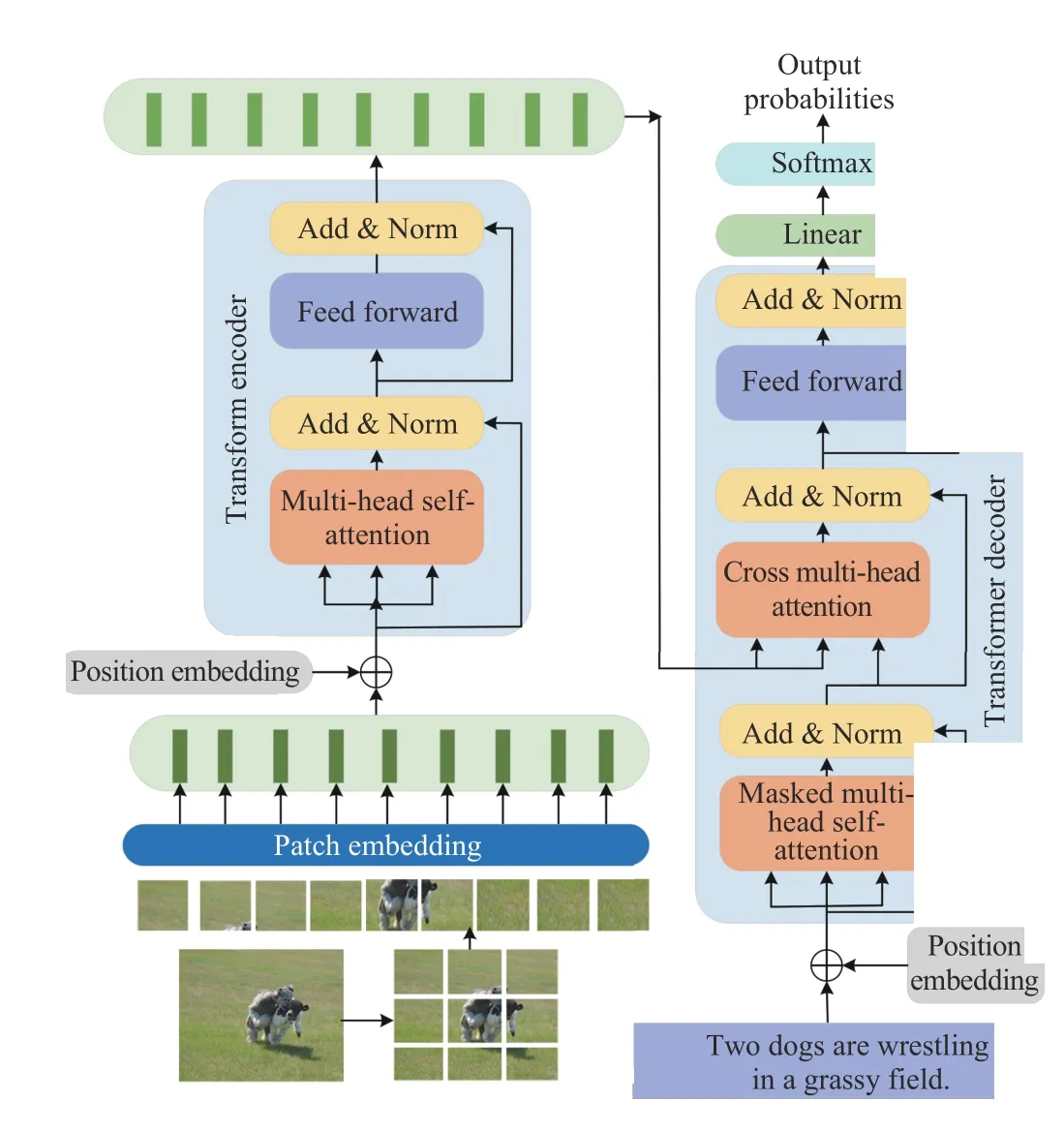
Fig. 16. The overall of convolution-free intra-modal attention model.

Many works [40], [139], [140] harness the RL strategy and explore different sequence-level metrics as rewards. Ranzatoet al. [141] first introduce the reinforcement learning algorithm into RNN for a sequence level training, which usually adopts BLEU and recall oriented understudy for gisting evaluation (ROUGE) as reward signals. CIDEr [142]and semantic propositional image caption evaluation (SPICE)[143] are also used as reward. Liuet al. [144] propose a policy gradient to directly optimize a linear combination of the SPICE and CIDEr metrics. Rennieet al. [28] build a selfcritical sequence training strategy. This makes it the most widely used RL-based strategy [135], [145], [146]. Furthermore, Chenet al. [147] and Yanet al. [122] use conditional generative adversarial nets to enhance any existing RL-based image captioning frameworks. Seoet al. [41] leverage a policy gradient approach to maximize the human ratings as rewards. Shiet al. [148] further imitate the attention preference of humans and fine-tune the attention directly with language evaluation rewards through an RL strategy.
In fact, the random strategies are difficult to improve in an acceptable amount of time. Therefore, common image captioning models require pre-training using cross-entropy or masked language models, and then fine-tune by reinforcement learning strategies with sequence-level metrics as rewards.
3) Pre-Training Model:Visual-language pre-training models trained on massive image-text pairs, are also proposed to fine-tune visual to language understand tasks [44].
In application, there are two objectives for the pre-training models. First and foremost, the pre-training models focus on the text-image alignment. Zhouet al. [149] present a unified visual-language pre-training model to concatenate salient objects and corresponding region features, and align them at the word-region level. Liet al. [150] propose a simplified alignment learning method by using object tags of images as anchor points. However, the method fails to generate novel object captions as it uses image-caption pairs for pre-training.Further, Huet al. [151] break the dependency and pre-train visual-text alignments based on image-tag pairs, improving novel object captioning and the general image captioning. The other most common pre-training objectives are the masked contextual token loss. When training the BERT [43]architecture, tokens of each modality (visual and textual) are randomly masked. Notably, some works completely avoid the combination with the cross-entropy loss. As verified by above models, the pre-training can significantly accelerate the learning speed of image captions and improve the performance of the model.
IV. DATASETS AND EVALUATION
We mainly introduce the commonly used public datasets and evaluation metrics for image captioning models.
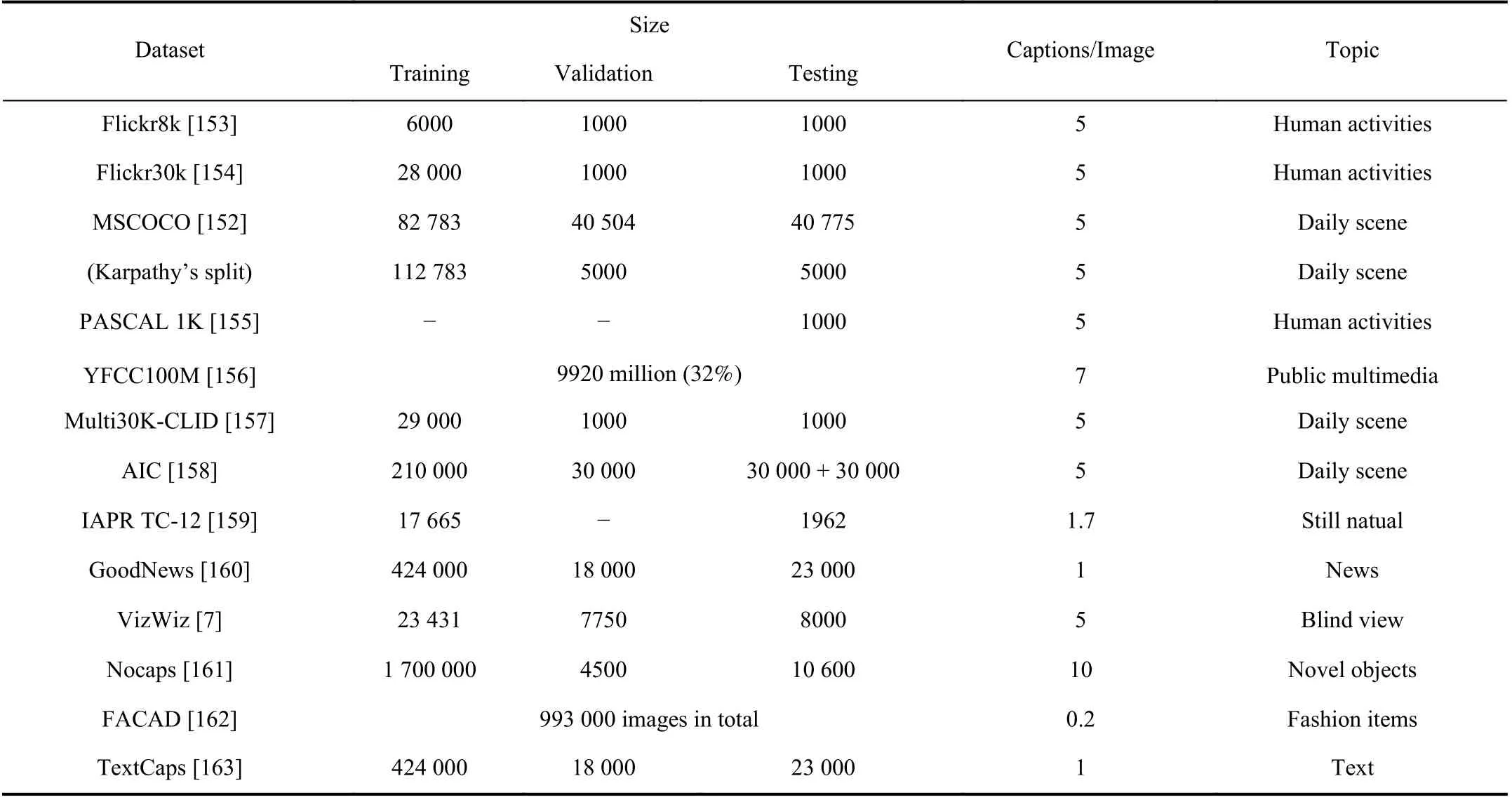
TABLE I SUMMARY OF THE NUMBER OF IMAGES USED FOR TRANING/VALIDATION/TESTING IN EACH DATASET. THE NUMBER OF CAPTION LABELS FOR EACH IMAGE AND THE TOPIC OF THE DATASET ARE ALSO DEMONSTRATED
A. Datasets
An effective dataset can make an algorithm more efficient.A summary of some public datasets is given in Table I, and some sample image-annotation pairs are shown in Fig. 17,along with captions generated by some typical methods for three benchmark datasets.
1) Benchmark Datasets:MS COCO2https://cocodataset.org/is the most widely used large-scale dataset in image captioning [152], which mainly consists of complex scene images from Yahoo’s photo album site Flickr. It includes 82 783 train images, 40 504 validation images, 40 775 test images, and each image is associated with 5 annotations. Since the description of the test set is not publicly available, Karpathyet al. [32] re-divide the train set and the validation set into training/validation/test set in practical applications, in which 5000 images are used for validation, 5000 images for testing, and the rest for training.The dataset has also a large official test set version including 40 775 test images paired with 40 private captions each, and a public evaluation server3https://competitions.codalab.org/competitions/3221to measure the performance.
Flickr8k/Flickr30k are all come from Yahoo’s photo album site Flickr, and are annotated through crowdsourcing services provided by Amazon Mechanical Turk. Flickr8k4https://forms.illinois.edu/sec/1713398[153]contains 8092 images, where 6092 are used for training, 1000 for verification, and the rest 1000 for testing. Each image is annotated with 5 different sentences with an average length of 11.8 words. The dataset is small and suitable for beginners.
Flickr30k5http://shannon.cs.illinois.edu/DenotationGraph/[154] is an extension of the Flickr8k dataset. It contains 31 783 images, and each image is associated with 5 manual sentence labels. In this dataset, 94.2% of the images are human, 1 2% with animals, 6 9.9% with clothing, 28% with limb movements, and 1 8.1% with cars and other tools.
2) Early Datasets:PASCAL 1K [155] is extended from object detection to image captioning. It contains 20 categories,each of which has a random sample of 50 images paired with 5 private captions each. All images are collected from the flickr photo-sharing website. YFCC100M [156] contains 99.2 million images from Yahoo Flickr, and 3 2% of the images are associated with captions, averaging 7 sentences per image and 22.52 words per sentence. Multi30K-CLID [157] extends the Flickr30K [154] to a multilingual description dataset, which has 29 000 training images, 1014 verification images, and 1000 test images. Description languages include English,German, French and Czech. Each language provides 5 annotations per image. IAPR TC-126https://www.imageclef.org/photodata[159] consists of around 20 000 images taken from locations around the world, and the majority of the images are provided by Viventura. Each image is provided with about 1.7 sentences annotations on average.The dataset provides 17 665 images for training. Visual Genome7http://visualgenome.org/[164] totally has 108 077 images from the intersection of MS COCO [152] and YFCC [156], with 5.4 million region descriptions, 3.8 million object instances, 2.8 million attributes, and 2.3 million relationships. Each image contains an average of 35 objects, 26 attributes, and 21 pairwise relationships between objects. It is often used for model pretraining in the study of image description based on relational learning.

Fig. 17. Qualitative examples from some typical image captioning datasets. MS COCO and Flickr8k/30k are the most popular benchmarks in image captioning. The images used in the MS COCO, Flickr8k and Flickr30k datasets are all collected from Yahoo’s photo album site Flickr. AIC is used for Chinese captioning, which focuses on the scenes of human activities. The images used in the AIC dataset are collected from Internet search engines. Nocaps is used for novel object captioning.
3) Specific Datasets:Moreover, several novel datasets are built for special requirements of the image captioning.GoodNews8https://github.com/furkanbiten/GoodNews[160] is the largest news caption dataset, which contains news articles captured from 2010 to 2018. It gathers 466 000 images, each with only single manual caption,headlines and text articles. It splits into three sets with 424 000 for training, 18 000 for validation and 23 000 for testing randomly. AIC9https://challenger.ai/[158] is the first Chinese language caption dataset. All images of the dataset are collected using Internet search engines. It contains more than 200 scenes and 150 types of actions, with 210 000 images for training, 30 000 images for verification and 60 000 images for testing. Each image provides 5 Chinese language annotations. VizWiz10https://vizwiz.org/[7]is built for image captioning services that blind rely on. It consists of 31 981 images taken from blind people, and each paired with 5 captions. It is used roughly with a70%/10%/20%split for the train/val/test respectively. Nocaps11https://nocaps.org/[161],the first large-scale benchmark. The benchmark consists of 166 100 hand-marked captions describing 15 100 images from the Open Images V4 [165] validation and test sets. There are three subsets of in-domain, near-domain and out-of-domain for the validation and testing split, which correspond to varied“nearness” to COCO respectively. FACAD [162] is a novel fashion dataset. It has over 993k diverse fashion images of all seasons, ages, categories, angles of human body, all images are collected from Google Chrome. And 130k descriptions with average length of 21 words are pre-processed for future research. TextCaps [163] is collected to comprehend text in the context of an image, which contains 28k images from Open Images v3 dataset with 145k captions.
B. Evaluation Metrics
Image captioning is inspired by the neural machine translation, and its early evaluation metrics come from machine translation and text summarization. It also forms unique evaluation criteria in the process of development.
1) Standard Metrics:BLEU [166] is used to analyze the cooccurrence ofn-grams between the candidate and reference.n-gram is usually used to reflect the precision of the generated descriptions. It compares a text segment with a set of references to compute a score, which correlates with human’s judgment of quality. Given an imageI, the generated caption can be denoted asci∈C, whereCis the set of allci. The BLEU scoring process can be represented as
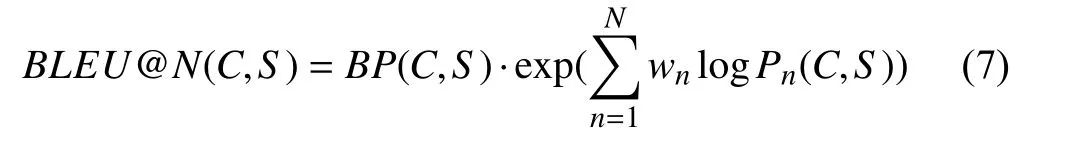

Semantic propositional image caption evaluation(METEOR) [167] is calculated based on the weighted harmonic average of single-word recall and precision, which can offset the shortcomings of BLEU. It also adds a wordnetbased synonymordlista to address issues of synonym matching. The METEOR dataset aims to gain a harmonic average of the accuracy and recall between the best selected caption and the reference caption



All above standard metrics can be computed with the publicly released source code12https://github.com/tylin/coco-caption.
2) Metrics for Diversity:The diversity of the generated sentences is compared using the metrics calculated in competing methods. Uniqueness [169] is the percentage of the distinct captions generated by sampling from the latent space.Novel sentences [169] are those generated sentences which do not appear in the training annotations. m-Bleu-4 [170]computes the average of Bleu-4 for each diverse caption with respect to the remaining diverse captions per image. It can predict whether it is overlapped between different subtitles.The lower the score, the greater the diversity. n-gram diversity(Div-n) [170] measures the ratio of distinctn-grams per caption to the total number of words generated per set of diverse captions. self-CIDEr [171], [172] is derived from using CIDEr similarity for latent semantic analysis and kernelization. It forms a pairwise similarity matrix, and uses the singular values of the matrix to measure the diversity of sentences. It is interpretable, and the more topics extracted,the more diverse for the captions. In practice, it needs to be used with other metrics for the syntactic correctness and the relevance to the image.
3) Metrics Based on Learning:The open-ended nature of image captioning makes it a challenging area for evaluation.Recently, many evaluation strategies based on learning are investigated, they aim to evaluate how human-like a caption is. Text-to-image grounding evaluation (TIGEr) [173]converts the reference and candidate sentences into grounding score vectors. Fidelity and adequacy ensured image caption evaluation (FAIFr) [174] leverages the scene graph as a bridge to represent both images and captions. TBERT-S [175]exploits pre-trained BERT embeddings [43] to represent and matches the tokens in the reference and candidate sentences via cosine similarity. ViLBERTScore [176] further reflects image context while utilizing the advantages of BERT-S. The ViLBERT is used to generate conditional image embedding in the generated and reference text. Then the embedding of each sentence pair is compared to acquire the similarity score.CIDErBtw [177] aims to improve the clarity of image captioning through similar image sets. It is used to assess how different a caption is from similar images. Contrastive language image pre-training score (CLIP-S) [178] is a crossmodal retrieval model inspired by CLIP [179]. SeMantic and linguistic UndeRstanding fusion (SMURF) [180] introduces“typicality” into evaluation, a new formulation rooted in the information theory. It is particularly suitable for problems which lack of definite ground truth. It evaluates fluency through style and grammar. Unreferenced metric for image captioning (UMIC) [181] is also a metric without a reference caption. Based on visual-linguistic BERT, UMIC is trained to recognize negative words through contrast learning.
C. Experimental Evaluation
In this section, we present a brief analysis of the application of datasets and metrics. And we also elaborate strengths and weaknesses of several classic captioning models.
Firstly, we review the application of datasets and metrics in image captioning. As shown in Table II, at the beginning of the study, the verification of image captioning is mainly completed based on Flickr 8K/30K. Both datasets are deficient in the number and scenes of images, which further restricts the performance improvement of captioning models.MS COCO is a large-scale dataset with complex scene images, which is more suitable for the task. Therefore, in recent studies, MS COCO has been used as a benchmark caption dataset in image captioning, except for some researches for special requirements. Initially, the metrics of image captioning are referenced from the NLP tasks, for example BLEU is a standard metric for neural machine translation, and R@K is usually used for recommender systems or ranking tasks.Subsequently, CIDEr and SPICE metrics are gradually proposed to evaluate the captions specifically. Finally, the standard metric set including BLEU, METEOR, ROUGE,CIDEr and SPICE has been established for image captioning systems.
We analyze the performance of representative approaches in terms of different evaluation metrics presented in Section IVB based on MS COCO. The results displayed in Table III are obtained either from caption files provided by the original authors or other implementation. The table contains all constituent ways of the encoder-decoder model mentioned in Sections III-A and III-B. In addition to language accuracy evaluation, the learning-based metrics can also reflect the benefit of vision-and-language pre-training. As illustrated in Table III, for convolutional representation learning, compared with grid features obtained from CNN (NIC [26] and Xuet al.[25]), all standard metrics have a substantial improvement with the introduction of CNN region-based visual encodings in SCST [28] and Up-Down [29]. This illustrates that the region-based feature representation favors the better visual understanding than coarse global information expressed by grid feature. Further improvement trend also occurs in GCN encoding (SGAE [74]), complete (CPTR [30]), and incomplete (ORT [132], M2-T [135]) self-attention encoding.More abundant visual relationships contribute significantly to understand the visual information and transfer it into text.
Furthermore, in Table IV, we summarize the performance of the widely accepted methods according to the taxonomies proposed in Sections III-A?III-C. We report their accuracy score in terms of standard evaluation metrics on the MS COCO Karpathy split test set. And their applications of visual encoding and language decoding ways, attention mechanismand training strategies are exhibited as well. As shown in Table IV, methods are clustered based primarily on the dates they are proposed. It can be seen that the performance of image captioning models has made impressive progress in recent years. For the standard metrics, the BLEU-4 score is calculated from an average of 24.6 for the global CNN features (NIC [26]) to an average of 38.2 and 38.4 for those exploiting the self-attention encoding (X-LAN [129]) and graph encoding (CGVRG [201]) based on the cross-entropy loss, while the same positive trend is noticed in the reinforcement learning training. The CIDEr score is absent in early grid feature models, it is calculated from an average of114.0 for region features to an average of 135.6 for the application of the self-attention mechanism with the peak at 140.4 for vision-and-language pre-training based on the reinforcement learning training strategy. In addition, we can reach the following conclusion that the more fine-grained and structured visual semantic information and diverse mutual relationship are mined, the better caption is generated. Since the performance of NIC [26] (coarse grid features) is much lower than that of Up-Down [29] (fine-grained visual region features), and the performance of Up-Down [29] is much lower than GCN-LSTM [35] (structured visual information and relationships) and ETA [134] (visual internal relationships). Moreover, the collected results from different training strategies show that the reinforcement learning strategy can be a valid alternative to the cross-entropy loss. Finally, the latest pre-training model VinVL [44] obtains peak scores in all standard metrics.
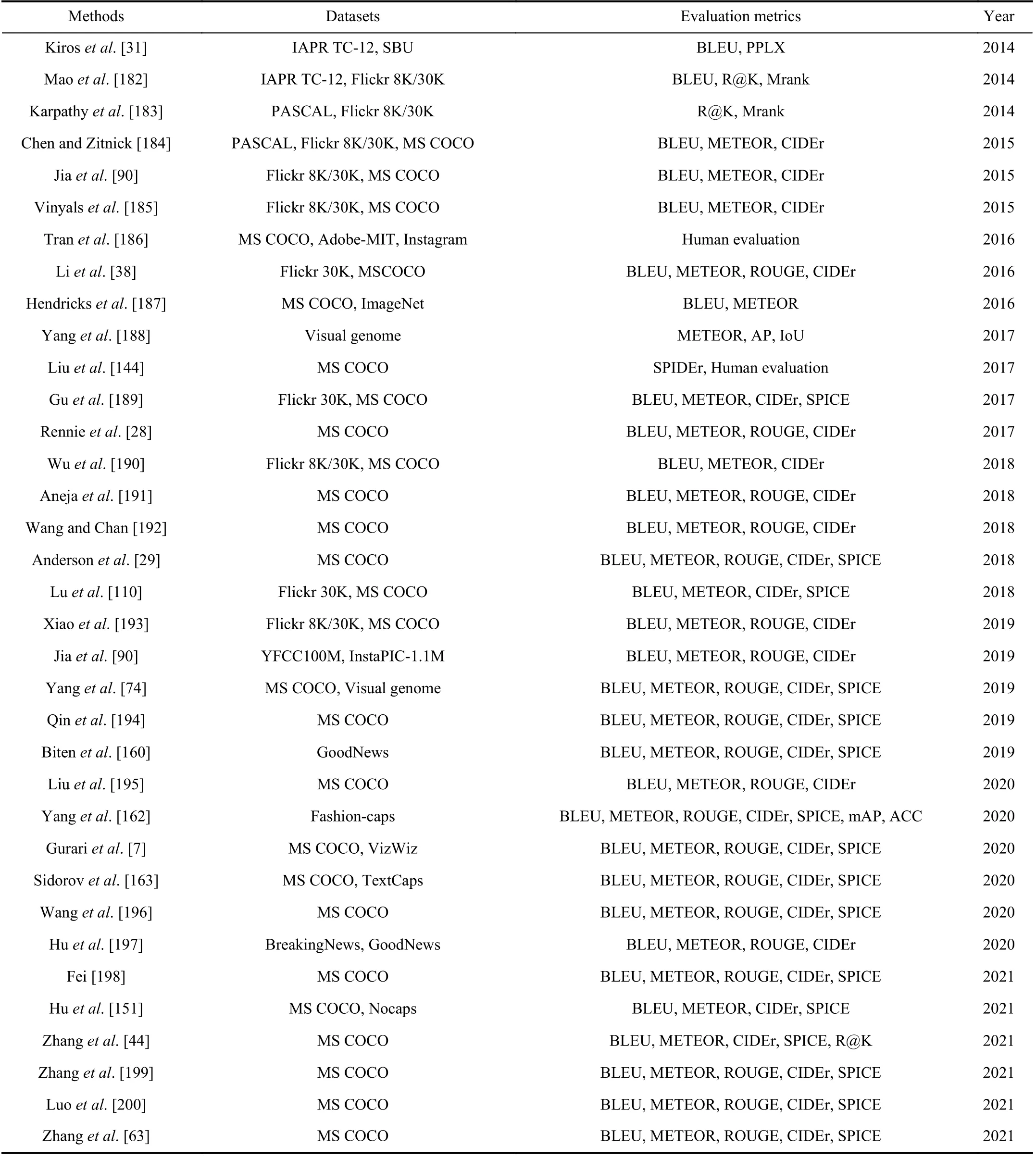
TABLE II AN OVERVIEW OF METHODS, DATASETS, AND EVALUATION METRICS. THE MS COCO IS THE MOST COMMONLY USED DATASET, WHILE THE FIVE STANDARD METRICS ARE MOST COMMONLY USED TO EVALUATE THE PERFORMANCE OF GENERATED CAPTIONS
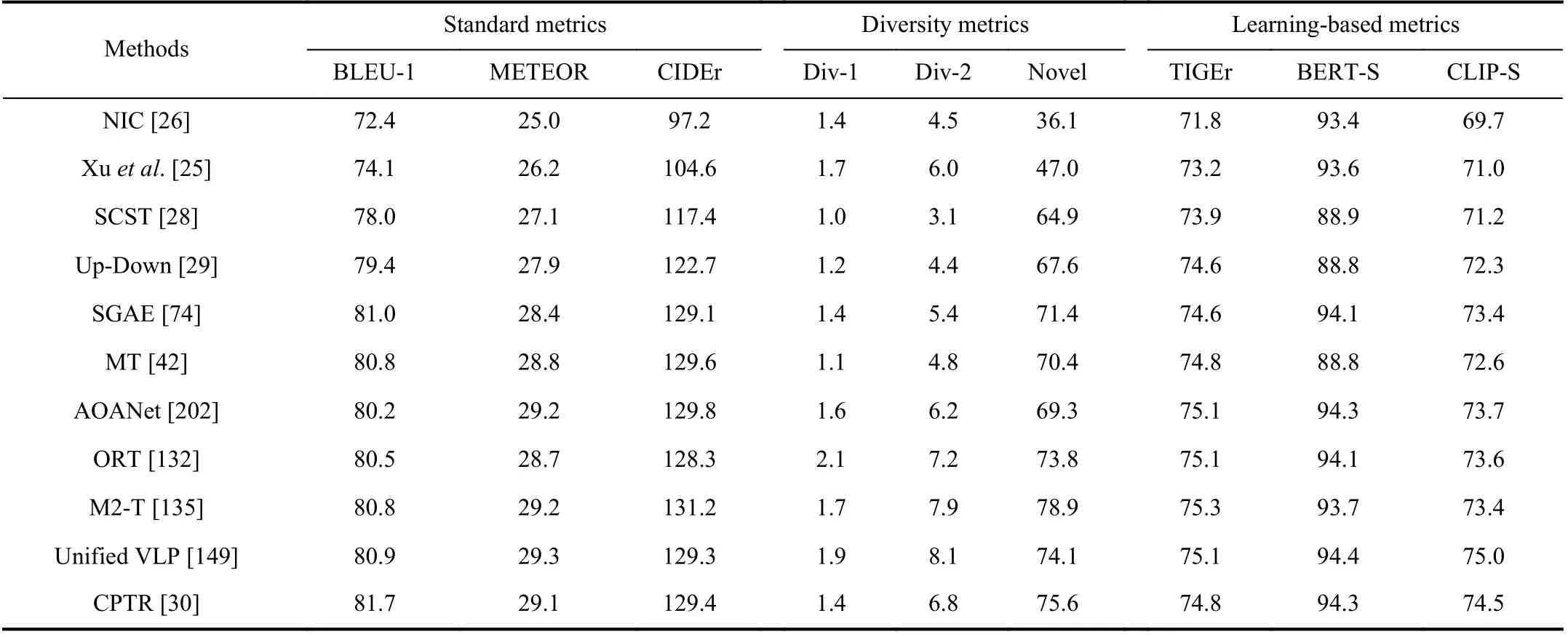
TABLE III PERFORMANCE ANALYSIS OF REPRESENTATIVE IMAGE CAPTIONING APPROACHES IN TERMS OF DIFFERENT EVALUATION METRICS. THE?MARKER INDICATES UNOFFICIAL IMPLEMENTATIONS. ALL RESULTS COME FROM THE MS COCO DATASET
Moreover, in Fig. 18, we display five examples of image captioning results obtained from some popular approaches based on the visual representation mode, training strategy and attention mechanism mentioned in Sections III-A, Section III-B,and Section III-C, respectively. The generated captions come from the NIC [26] model with global grid features, STCT [28]with the RL training strategy, Up-Down [29] with visual region features, VRG [201] with graph representation, and Transformer with self-attention, coupled with the corresponding ground truth sentence. Compared with ground truth, we highlight the novel descriptions of new objects (in green),attributes (in blue) and relations (in orange), which provides intuitive visual illustration for different kinds of image caption methods. In particular, there are also some error descriptions of the given image highlighted in red. It is obvious from these highlighted words that VRG and Transformer models can generate better captions with detailed attributes and relationships, such as “blue and white”, “with”, and “on the tail” in the first image of Fig. 18. More examples can be found in other images. The result is consistent with the previous quantitative analysis, more fine-grained and structured visual information and diverse visual relationship contribute to the better captions. There are also several obvious errors marked in red, such as “a market” in the second image and “dog” in the fifth image. This indicates that there are still significant challenges in visual content understanding and cross-modal semantic alignment.
V. DISCUSSIONS AND FUTURE RESEARCH DIRECTIONS
Automatic image captioning has attracted increasing attention in recent years. It has made significant progress due to the development of the encoder-decoder framework, attention mechanism, and different training strategies. However, there is still room for further improvement.
A. Flexible Captioning
Current captioning approaches usually describe images using black-box architectures, which can interpret the image either briefly or in detail. However, its performance is still not clearly explainable and lacks descriptive flexibility, which creates a gap between human and machine intelligence. Since an image can be described in various ways according to the goal and the context backgrounds, a higher degree of flexibility is needed for captioning complex scenarios. Although some progress has been made in controllable captioning [210],[211] and editable captioning [212], its length and diversity are still restricted to the annotation. More fine-grained visual information, more potential visual relationships and more common-sense language priors will contribute to improve the flexibility of sentences. The flexible captioning is one of the topics worth further investigating in the future.
B. Unpaired Captioning
Most of existing image captioning models seriously rely onpaired image-caption datasets. How to learn a captioning model with unpaired dataset is a challenging and essential task. Only a small number of attempts have been made in unpaired image captioning, such as novel object captioning[151], [161] and dense captioning [213], [214]. Due to the significantly different characteristics of the two modalities,unpaired image-to-sentence translation is more challenging and far from mature. Unsupervised learning techniques can reduce the dependence of models on large datasets. And it is an effective scheme to solve the unpaired image captioning problem. Besides, language pivoting is another worthy endeavor, which captures the characteristics from the pivot language and aligns it to the target language.
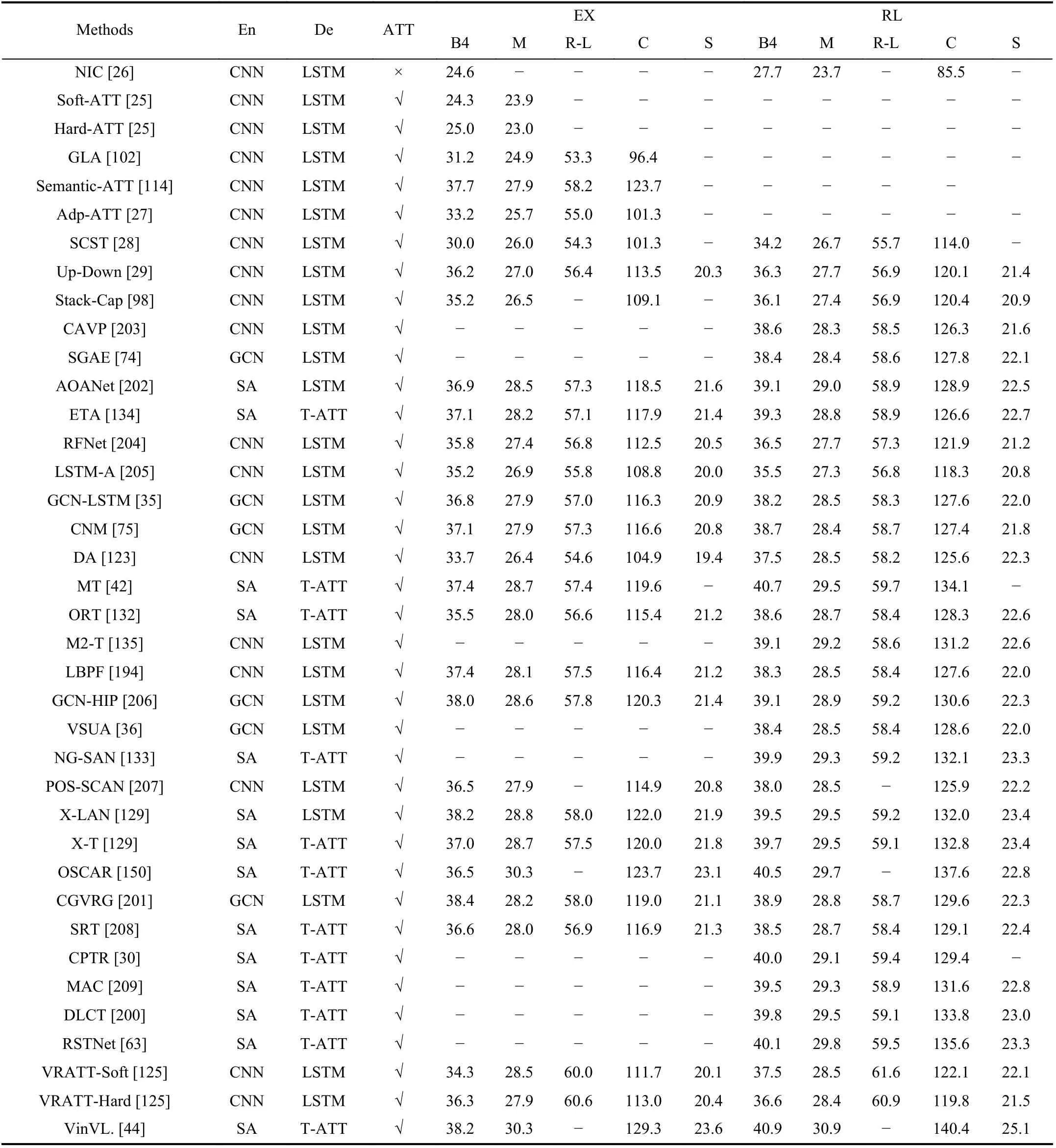
TABLE IV OVERVIEW OF DEEP LEARNING-BASED IMAGE CAPTIONING FRAMEWORKS AND PERFORMANCES IN DIFFERENT TRAINING STRATEGIES.“EN”, “DE” AND “ATT” MEAN ENCODER, DECODER AND ATTENTION MECHANISM RESPECTIVELY. “EX” REFERS TO THE CROSS-ENTROPY STRATEGY AND THE “RL” INDICATES THE REINFORCEMENT LEARNING STRATEGY. “T-ATT” IS THE ATTENTION USED IN TRANSFORMER DECODER, WHICH CONTAINS A SELF-ATTENTION FOR WORD EMBEDDING AND A CROSS-ATTENTION FOR ALIGNING THE VISUAL AND LANGUAGE INFORMATION. THE MARKERS OF “B4”, “M”, “R-L”, “C” AND “S” ARE THE STANDARD METRICS OF BLEU-4, METEOR,ROUGE-1, CIDER AND SPICE RESPECTIVELY. THESE SCORES ARE TAKEN FROM THE RESPECTIVE PAPERS, AND ALL RESULTS COME FROM THE KARPATHY’S SPLIT OF MS COCO DATASET

Fig. 18. Qualitative examples from five popular captioning models on MS COCO val images. All models are retrained by us with ResNet-101 features. Errors are highlighted in red, and new descriptions of objects, attributes, relations are highlighted in green, blue and orange severally.
C. User requirements Captioning
Different users have different caption requirements in different situations. For example, people need to post more personalized, emotional, and diversified sentences on social apps. User requirements captioning, such as diversity captioning [172], personality captioning [215] and topic captioning,which can meet various needs for different users in different scenarios, is also a direction necessary and worthy to further research. Specific datasets and model improvements can be proposed to meet user needs. Furthermore, external knowledge and commonsense reasoning are also good ideas, as they can help models generate captions with more stylized information and enhance knowledge reasoning as well.
D. Paragraph Captioning
Most current image captioning research focuses on singlesentence captions. But, the descriptive capacity of this form is limited. As we know, a picture may contain rich information worth a thousand words. To completely depict an image,paragraph captioning [71], [216] is considered as the feasible description, which can generate a paragraph with multiple sentences for describing the given image. However, existing paragraph captioning models mostly focus on generating multi-sentence of several topics without considering the semantic coherence between sentences. How to leverage more fine-grained, relevant visual features and priori knowledge to generate a true paragraph with linguistic coherence corresponding to the image, is still a challenging and interesting task.
E. Non-Autoregressive Captioning
Existing encoder-decoder models use autoregressive decoding to generate captions. It may result in sequential error accumulation and slow generation, which limit the applications in practice. Inspired by machine translation, nonautoregressive (NA) decoding [217], [218] has been proposed to solve these issues, which aims to speed up the inference time. Preliminary NA models suffer from the language quality problem due to the indirect modeling of the target distribution and ignoring the sentence-level consistency. The Non-Autoregressive captioning models need further improvement for generating elegant descriptions while maintaining low time consumption for words prediction.
F. Datasets and Metrics Exploring
Image captioning cannot be separated from the specific datasets. Existing image captioning datasets are not enough to fully support the above extended directions. Therefore, more new specific datasets, such as novel objects captioning dataset, fashion captioning dataset and multilingual captioning dataset, need to be developed. Similarly, the evaluation metrics should neither be limited to the accuracy based on similarity calculation. Although some diversity metrics and semantic-level metrics are proposed, it is still a challenging area for evaluating multiple image captioning with an openended nature.
VI. CONCLUSIONS
In this paper, we review the development of the image captioning and related issues including datasets and evaluation metrics. Firstly, we give a brief introduction to the traditional retrieval-based, template-based methods and their improvements. Secondly, recent deep learning image captioning models are discussed in detail, especially the encoder-decoder framework, attention mechanism and training strategies. After that, We classify and summarize the datasets and evaluation metrics for image captioning. The existing methods are compared on the benchmark MS COCO based on the standard evaluation metrics. Although these deep learning models have achieved significant progress, there is also room for improvements. So finally, we give a detailed discussion about potential future research directions in the image captioning task. Image captioning has been widely used in intelligent information transmission, intelligent home, smart education and other fields. This makes it still an important research direction in deep learning and artificial intelligence and will have an increasing impact on our daily life in the future.
 IEEE/CAA Journal of Automatica Sinica2022年8期
IEEE/CAA Journal of Automatica Sinica2022年8期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Complex-Valued Neural Networks:A Comprehensive Survey
- Cyberbullying and Cyberviolence Detection: A Triangular User-Activity-Content View
- Networked Knowledge and Complex Networks: An Engineering View
- Battery Full Life Cycle Management and Health Prognosis Based on Cloud Service and Broad Learning
- Estimation Based Adaptive Constraint Control for a Class of Coupled String Systems
- Multi-Attention Fusion and Fine-Grained Alignment for Bidirectional Image-Sentence Retrieval in Remote Sensing