
An Improved Memory Cache Management Study Based on Spark
2018-10-09 08:45:30SuzhenWangYanpiaoZhangLuZhangNingCaoandChaoyiPang
Computers Materials&Continua 2018年9期
Suzhen Wang, Yanpiao Zhang, Lu Zhang, Ning Cao and Chaoyi Pang
Abstract: Spark is a fast unified analysis engine for big data and machine learning, in which the memory is a crucial resource. Resilient Distribution Datasets (RDDs) are parallel data structures that allow users explicitly persist intermediate results in memory or on disk, and each one can be divided into several partitions. During task execution,Spark automatically monitors cache usage on each node. And when there is a RDD that needs to be stored in the cache where the space is insufficient, the system would drop out old data partitions in a least recently used (LRU) fashion to release more space. However,there is no mechanism specifically for caching RDD in Spark, and the dependency of RDDs and the need for future stages are not been taken into consideration with LRU. In this paper, we propose the optimization approach for RDDs cache and LRU based on the features of partitions, which includes three parts: the prediction mechanism for persistence, the weight model by using the entropy method, and the update mechanism of weight and memory based on RDDs partition feature. Finally, through the verification on the spark platform, the experiment results show that our strategy can effectively reduce the time in performing and improve the memory usage.
Keywords: Resilient distribution datasets, update mechanism, weight mode.
1 Introduction
Human society has entered the era of Big Data which has become one of the most important factors in production. The big data of industry and enterprise that can reach hundreds of TB or even hundreds of PB at a time has far exceeded the processing capacity of traditional computing techniques and information system. Cloud computing enables convenient and on-demand access to a shared pool of configurable computing resources,see Li et al. [Li and Liu (2017); Liu and Xiao (2016); Zhao, Wang, Xu et al. (2015);Thanapal and Nishanthi (2013)]. Spark has been widely adopted for large-scale data analysis, see Apache Spark [Apache Spark (2018)]. One of the most important capabilities in Spark is persisting (or caching) a dataset in memory or on disk across operations, see Lin et al. [Lin, Wang and Wu (2014); Zaharia, Chowdhury, Franklin et al. (2010)]. However,the user manually selects the RDD to cache by experience, which leads to several uncertainties and impact on efficiency. At the same time, the Spark can automatically monitor cache usage on each node and drop out old data partitions in a LRU fashion.
However, in Spark, the LRU algorithm only considers the time feature of the node where the partition is located but not the partition features.
Recognizing this problem, scholars have researched various replacement algorithms. By studying FIFO, LRU and other cache algorithms, the AWRP algorithm that calculates the weight for each object is designed in Swain et al. [Swain and Paikaray (2011)], but it assumes that the size of the blocks is equal. For the Spark framework, Bian et al. [Bian,Yu, Ying et al. (2017)] propose an adaptive cache management strategy from three aspects: automatic selection algorithm, parallel cache cleanup algorithm and lowest weight replacement algorithm. But it ignores the factor that the weight is changing during execution. The WR algorithm in Duan et al. [Duan, Li, Tang et al. (2016)] is proposed to calculate the weight of RDDs by considering the partitions computation cost, the number of use for partitions, and the sizes of the partitions. However, it does not take into account the change in the remainder usage frequency of the cache partition during task running.Before the persistence, Jiang et al. [Jiang, Chen, Zhou et al. (2016)] further consider whether the persistence is needed by judging the cost required and the computing cost.Zhang et al. [Zhang, Shou, Xu et al. (2017); Chen, Zhang, Shou et al. (2017); Chen and Zhang (2017)] put forward fine-grained RDD check-pointing and kick-out selection strategy according to DAG diagram, which effectively reduces RDD computing cost and maximizes memory utilization rate. Meng et al. [Meng, Yu, Liu et al. (2017)] taking full account of the distributed storage characteristics of RDD partition point out the influence of complete RDD partition and incomplete RDD partition on cache memory, but he does not discuss the choice of RDD caches.
By analyzing the researches above, in this paper, we optimize the selection strategy for caching RDD and the LRU replacement algorithm from the following aspects:
(1) We propose a prediction mechanism for caching RDDs. The use frequency of each RDD is obtained based on the DAG diagram, and it is further decided whether to cache the RDD according to the cost between the persistence and computation.
(2) We put forward a weight replacement algorithm based on RDD partition features According to the characteristics of partition, we calculate the weight model by using entropy method.
(3) The update mechanism for storage memory and weight of partition. Whenever the usage frequency of the partition changes, we update the partition weights and the storage memory in real time.
2 Introduction of Spark cache
2.1 Resilient distribution datasets
RDD is distributed collection of objects, that is, each one can be divided into multiple partitions. RDDs support four types of operations: Creations, transformations, controls and actions. The SparkContext is responsible for the creation of RDD. Additionally, the transformation operations create a new dataset from an existing one, and the control operations mainly persist the RDD. In the course of the execution of the program, the operation of producing RDD is delayed until the action operation happened, see Ho et al.[Ho, Wu, Liu et al. (2017)].
During the task execution, a DGA graph based on the Lineage can be created by DAGSheduler, and further divides the stage based on the dependency between the RDDs.See Gounaris et al. [Gounaris, Kougka, Tous et al. (2017); Geng (2015)] for more details.Each stage creates a batch of tasks which are then assigned to various executor processes.After all the tasks in a stage are executed, the reused RDD would be stored in the cache for further use, as illustrated in Fig. 1. The reused data is more common in some iterative computations, such as the PageRank andK-means mentioned in Zaharia et al. [Zaharia,Chowdhury, Das et al. (2012); Xu, Li, Zhang et al. (2016); Zhang, Shou, Xu et al. (2017);Chen, Zhang (2017); Napoleon and Lakshmi (2010)]. It can effectively reduce the cost of computing by caching the reused RDD to the storage memory. During the execution,users can specify the caching level and the object to be stored, such as the MEMORY_ONLY and MEMORY_ONLY_2 mean to store the RDD to the memory[Ding and He (2004)].
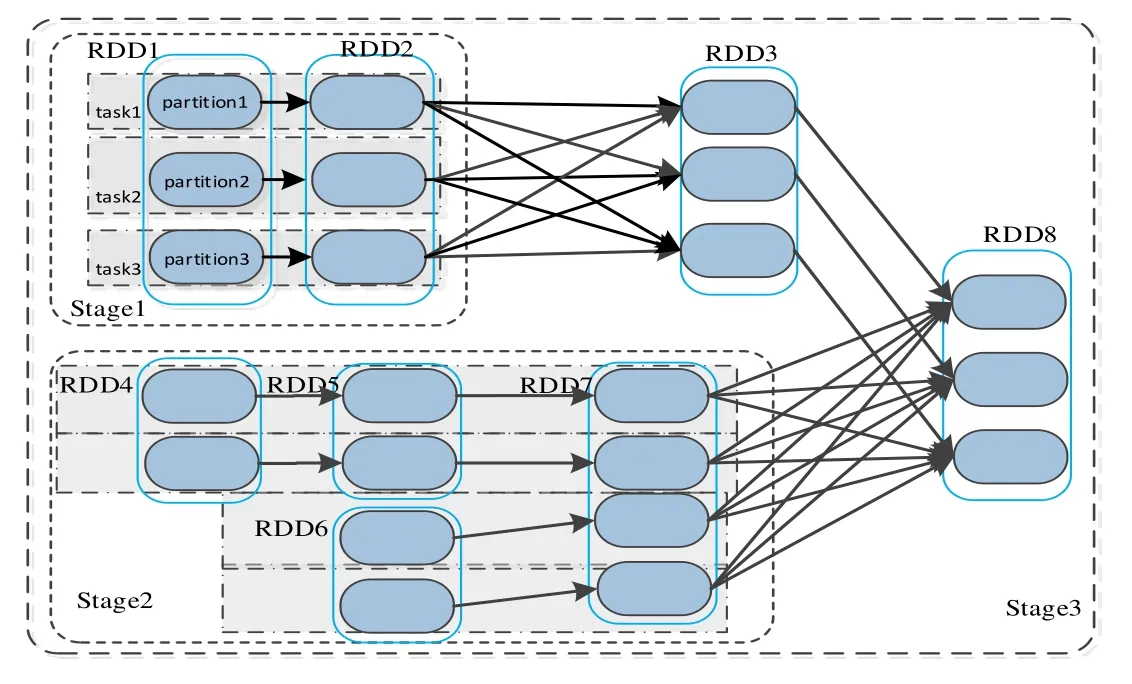
Figure 1: The schematic diagram of parallel computing for RDD
2.2 Memory management mode
As shown in Fig. 2, the schematic diagram of memory partition in Spark 2.0.1 is obtained by analyzing the source code, see Dabokele et al. [Dabokele (2016); Hero1122 (2017)].The memory is firstly divided into two main parts: Memoryoverhead (default 384 M) and ExecutorMemory. ExecutorMemory can be further divided into Reserved Memory (default 300 M) and UsableMemory. If the system memory is less than 1.5*ReservedMemory, there would be an abnormality report. Note that 60% (the proportions can be modified) of the UsableMemory is used for storage and calculation. HeapExecutorMemory is used for task computing, and HeapStorageMemory is mainly used to cache the intermediate results that need to be reused. After Spark 1.6, the StorageMemory and the ExecutorMemory can be dynamically converted to each other, what is called Unified. Stroage and Execution can borrow each other’s memory. It is important to note that when there is no enough memory in both space, the Storage portion will spill the data that over 50% to the disk ( based on the storage_level) until the memory borrowed is returned, this is because the execution(Execution) is more important than a cache (Storage). There the release data is also based on the LRU algorithm.
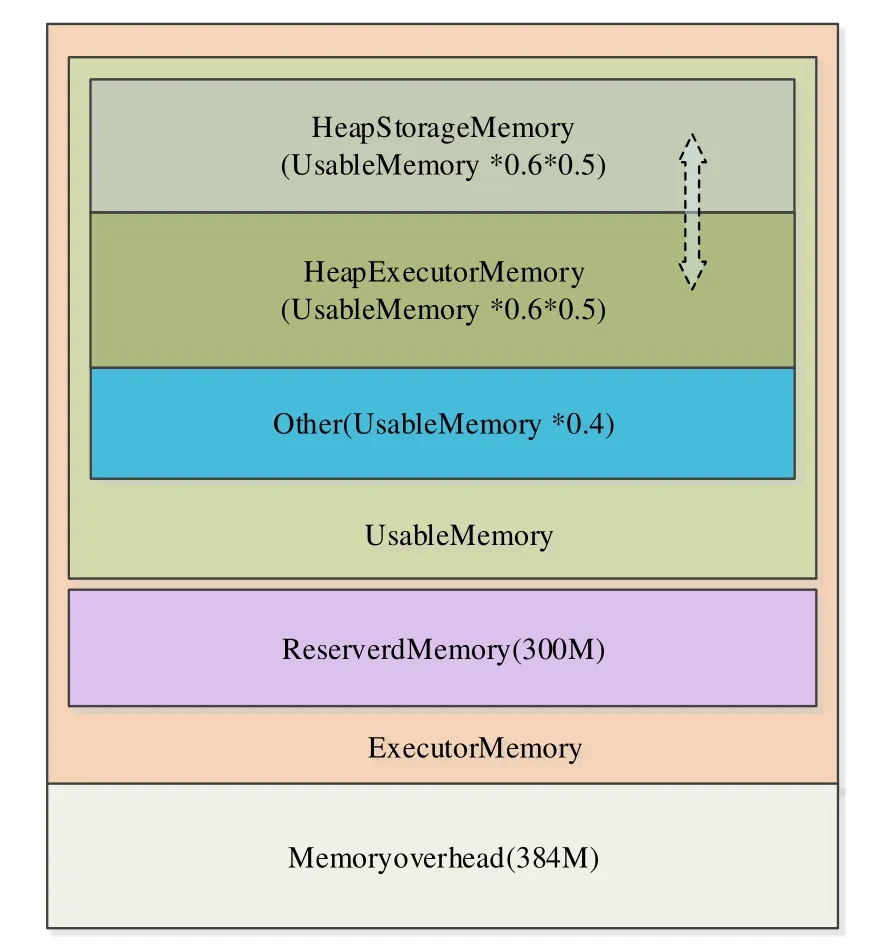
Figure 2: The diagram of Spark memory allocation
2.3 Cache mechanism in Spark
All of the calculations in Spark are done in the memory, and when there is a RDD that needs to be reused, it would be cached by experience. When storage capacity is insufficient, something essential needs to be done with replacement algorithm to reclaim the memory. The default algorithm is LRU which is mentioned in He et al. [He, Kosa and Scott (2007)]. The principle of LRU algorithm is: (1) The data newly added is inserted into the head of the linked list. (2) The data accessed is moved to the chain header. (3)When the storage space of the linked list is insufficient, the data at the end of the linked list is discarded. As shown in Fig. 3.
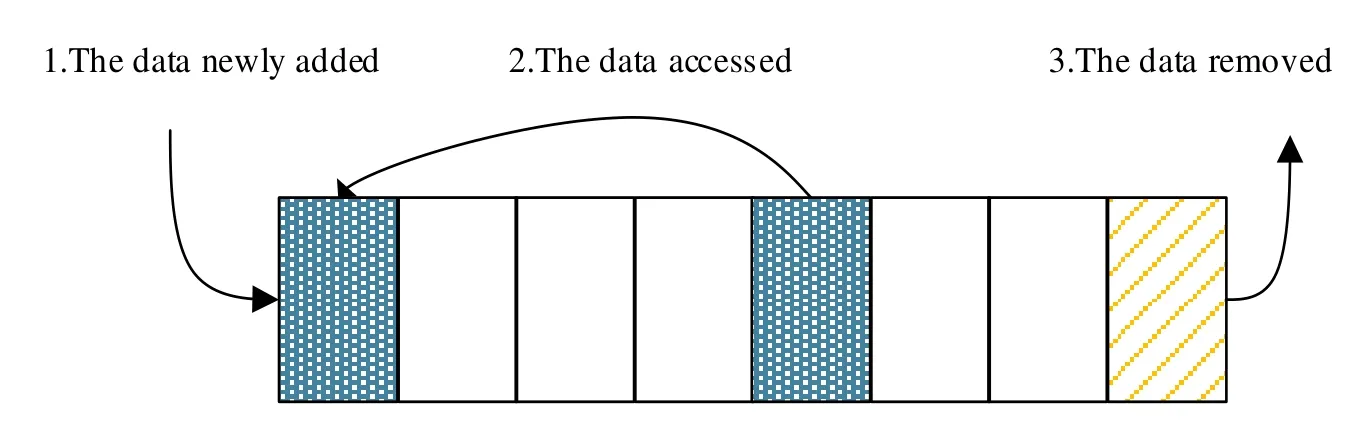
Figure 3: The principle of LRU algorithm
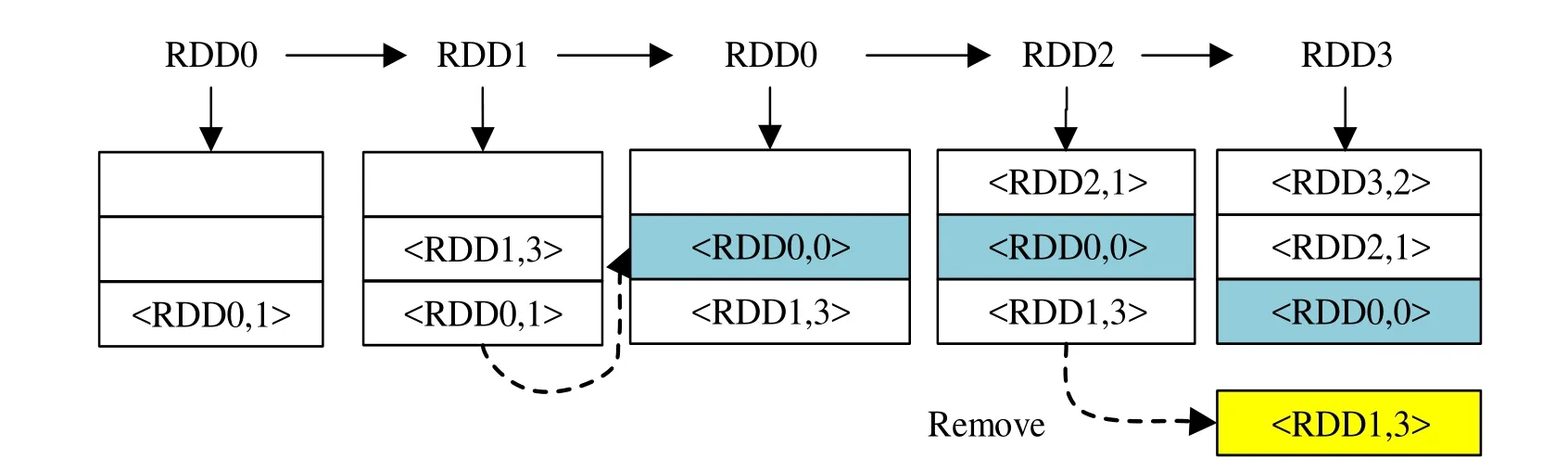
Figure 4: The cache replacement schematic of RDD
In Spark, the LRU replacement algorithm is implemented by LinkedHashMap with the characteristics of a double linked list, see Lan [Lan (2013)]. Because of its inability to predict the future use of each page, it will release the least recently used page, see Wang[Wang (2014)]. However, in Spark, different RDD partitions in the same storage memory are heterogeneous, that is, they are different in the size and usage frequency. In this case,it would lead to a lot of unnecessary calculations only by the time factor.
For instance, let RDD and the corresponding usage frequency represent for the series of RDDs:
3 Cache replacement model of RDD
In this section, we will learn from the follow parts. Firstly, analyze the influence factors of RDD cache, and then propose three innovations: The prediction mechanism for persistence, the weight model by using the entropy method, and the update mechanism of weight and memory based on RDDs partition feature.
Note that each job contains several RDDs, now letbe the set of RDDs, whilebe the set of partitions ofRi.
Definition 1Task execution speedup. There we use the task execution speedup expressed byTEspto measure the task performance with the optimized algorithm. There will be better performance of the task execution with the greater speedup. The Formula is as follows:

SetTLRUas the execution time with LRU algorithm, and theToptas the execution time with optimized algorithm.
3.1 Analysis of influence factors
To improve the research, it is necessary to learn the characteristics of RDD. The characteristic elements are as follows:
(1) The frequency of utilization
In order to avoid the unnecessary computation, it is necessary to make a judgment on the usage frequency of RDD. When an action occurs, the DAGScheduler creates a DAG based on the Lineage of RDD. By traversing the DAG diagram, we useto represent the characteristics of the RDD, in which theNirepresents the total usage frequency during the entire program. The RDD with largerNiis more worthy of being cached.
(2) The remainder use frequency of RDD partition
The RDD caching is in the form of partitions, and the residual frequency of the partitions decreases gradually in the course of task execution. There letNijbe the usage frequency for each RDD partition. Before caching theRi, we set the equation:Ni=Nij. When the first caching occurs ofRi, the value of theNijis reduced by one, and also it continues to decrease whenever theRiis used.
(3) Computational cost
When the cache memory is insufficient, the LRU algorithm will release the least recently used RDD. In the system, the algorithm only takes into account the time feature of the node where the partition is located. In fact, there would be unnecessary computational overhead provided that the partition eliminated needs to be reused next time. Therefore,the computational cost of partition should be a crucial factor. The partition with higher cost shouldn't be replaced. Here we usedefined in Duan et al. [Duan, Li, Tang et al.(2016)] to express the computational cost of RDD partition.

LetETijrepresent for the finish time, while theSTijas the start time. At the same time, the execution time of a RDD is determined by the maximum time of all partitions, so the computational cost of RDD is as follows:

(4) The size of partition
The partitions that occupy the larger memory space should be preferentially eliminated to release more resources.
3.2 The prediction mechanism for caching
The prediction mechanism is divided into two parts:
(1) WhenNiis equal to 2 In this case, the frequency will change to 1 by storing RDD in the cache. If not cache,there would be a recomputation cost. So it is necessary to decide whether it is worth to cache the RDD according to the relation:

(2) WhenNi>2, it is suggested to be cached
The execution process is as follows:

Algorithm 1: RDD automatic cache prediction algorithm.Input:RDD sequence: R={R1...Ri...Rn}the usage frequency of RDD: NR the partition of RDD: RP the size of RDD partition: SRP the frequency to be used of RDD partition: NRP the remaining memory size of the storage node: Scach the C is donated as the set of partitions cached.Initialization:NR=NRP For (i=1 to n)If (NR=2 and SRP
3.3 Weight replacement model
Replacement operations are required when the storage space is insufficient to accommodate the RDD that needs to be cached. Also, the Storage section can apply to all free memory in the Execution section. When the execution requires more memory, the storage portion will spill the data to the disk (based on the storage_level) until the memory borrowed is returned. Forced discard data is also based on LRU algorithm. In order to represent the importance of an index in the whole analysis process, we adopt the weight form. Therefore, to reduce the cost of the re-computation, we put forward the weight calculation model based on partition feature by using entropy method in Zuo et al.[Zuo, Cao and Dong (2013)] to optimize LRU algorithm. The entropy method determines the index weight based on the degree of variation of each index value. Entropy is a measure of the degree of disorder in the system and can be used to measure the effective information of known data packets and determine weights. By determining the weights based on the calculation of the entropy, the weight of each partition is determined according to the degree of difference in the feature values of the partitions. When there is a large difference between certain eigenvalues of the evaluation object, the entropy is smaller which means the number of valid information provided by this feature is larger.Accordingly, the weight of the object should be larger. Conversely, if the difference between a certain feature value is small, the entropy value should be larger. It indicates that the feature provides less information and the weight should be smaller. When a feature value of a partition is exactly the same, the entropy value reaches a maximum,which means that the feature value is useless information. The process of the weight calculation is as follows:
(1) Converting the characteristic of partition into matrix form
Assuming that there arenpartitions in the storage memory, and each partition hasmfeature attributes. In this paper we setm=3, which means there are three features:Nij,andSRij. LetXijbe the value of thej-th index of thei-th partition, the matrix is as follows:

(2) Normalization processing
Since the measurement units of each feature are inconsistent, the standardized operations must be performed before computing. That is, the absolute value of the eigenvalue should be converted to the relative value to solve the homogeneity problem of different eigenvalues. TheNijandare positive correlation index, andSRijbelongs to negative correlation index. The normalized treatment formula is as follows:
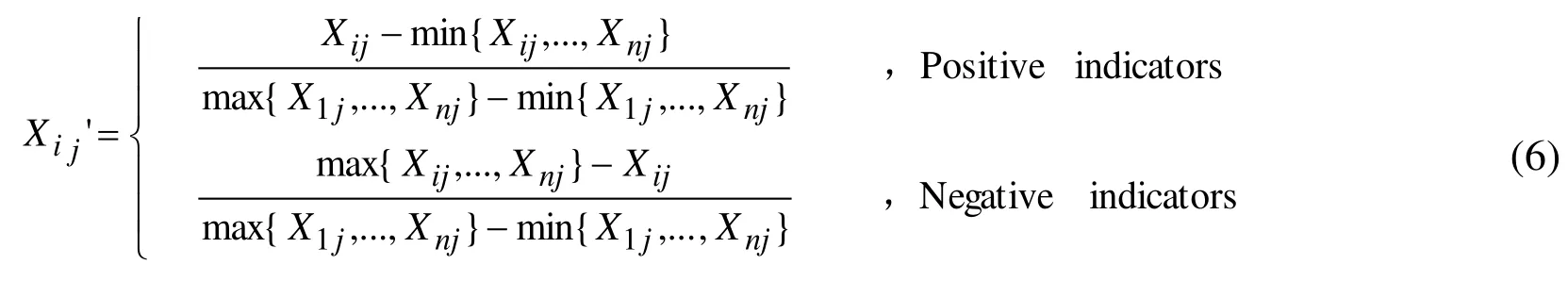
For convenience, the normalized dataX'ijis still represented byXij.
(3) Under thej-th feature, thei-th partition occupies the proportion of the feature

(4) The entropy of thej-th feature

Where thek>0,lnis natural logarithm, then theej≥0, andk=1/lnm2.
(5) The difference coefficient of thej-th eigenvalue

(6) The weight of each feature

(7) The weight of each partition

Finally, by calculating the weight of each partition, the partition with lowest weight should be considered first to be replaced when the replacement happened. The process is as follows:
Firstly, we need to compare the weight of the partition to be cached with the lowest weight:
(1) If there is a qualified partition in the cache, release the partition. Otherwise,conversely turn to (2).
(2) Put the RDD which needs to be cached to the wait cache area, and wait for weight updating in the storage memory.
The execution process is as follows:

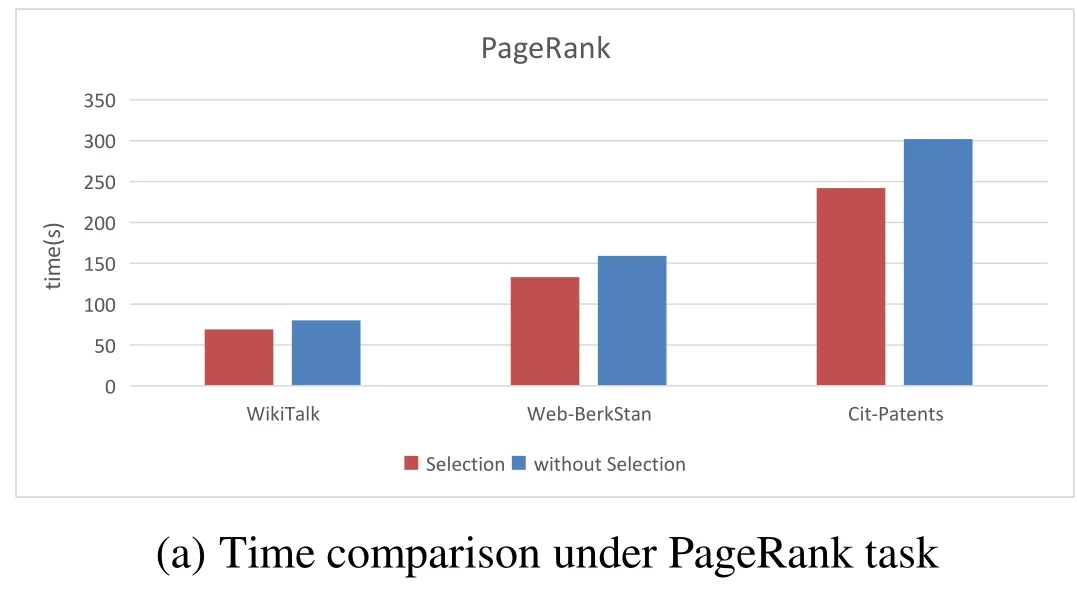
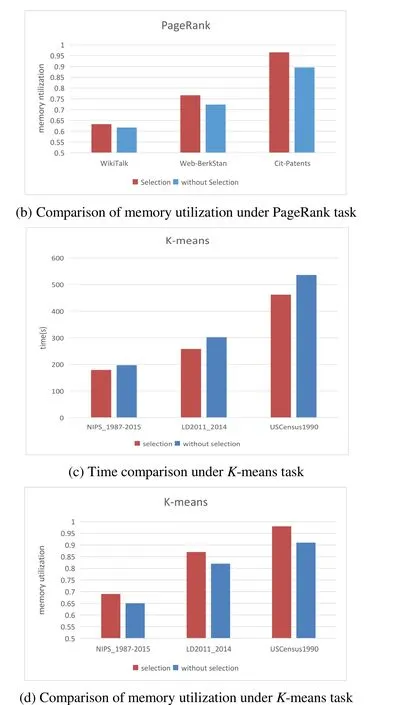
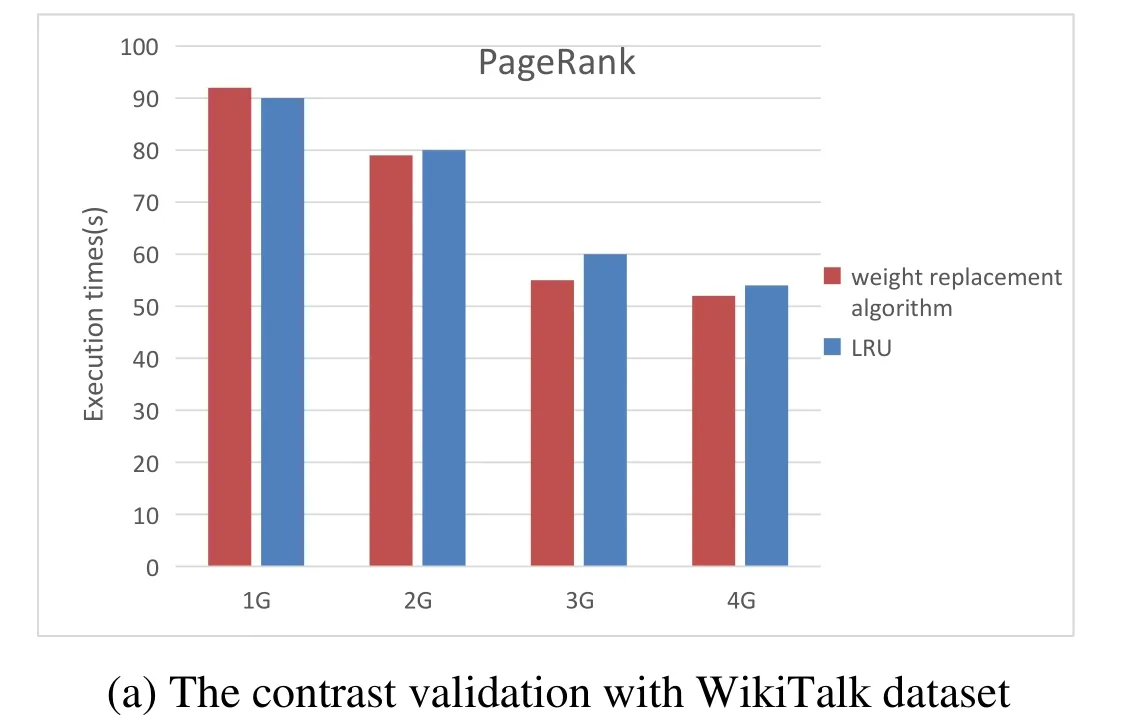
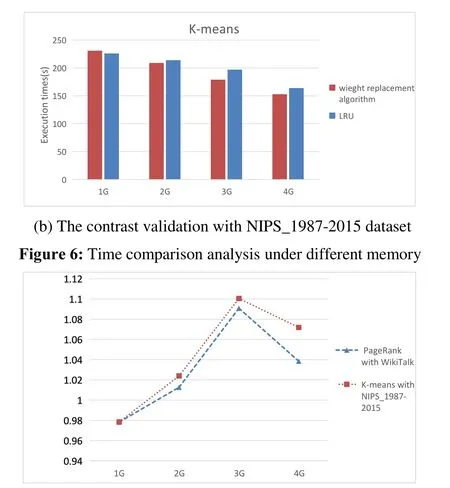
Algorithm 2: weight replacement Input:partition in cache area: Rp, weight:v the size of Rp:SRP surplus space of storage memory:Scach the C is donated as the set of partitions cached the set of the size for partitions cached:{CSRP1 ....CSRPp}for (i=1 to p)if (CRPi .weigth < v )put CRPi to weigthList[j] according to the weight from small to large end if end for for (i=1 to weigthList.length)if (SRP As we can see that in the process of task execution, the frequency of each partition to be used is constantly decreasing with the use of partitions, and the weights of the corresponding partitions are also changing. So we propose the update mechanism for storage memory and weight of partition: Whenever a partition in a storage area is used,the usage frequency of the partition is reduced by one, and all partitions are traversed to update the weight. At the same time, the partition to be used with frequency zero should be released to release more memory. During task execution, the weight of the partition should be updated whenever the remainder usage frequency of partitions in the storage area is reduced. The execution process is as follows: Algorithm 3: Update mechanism Input:the remainder usage frequency of partitions:NRP the C is donated as the set of partitions cached:C={CRP1,...,CRPi,...,CRPp}while a RDD will be used in computing:for (i=1 to p)if (CRPi will be used) then NRPi=NRPi -1 renew CRPi.weigth end if if (NRPi==0)C=C-CRPi end if end for The environment required in this experiment is as follows: (1) Cluster environment: Six virtual machines that created by two laptop computers and a desktop. (2) Cloud environment: Use Spark 2.0.1 as the computing framework and Hadoop Yarn as resource scheduling module. (3) Monitoring environment: nmon and nmon analyser. (4) Use The PageRank andK-means as the task algorithm, and choose three datasets from SNAP et al. [SNAP (2018)] and [UCI (2007)] respectively. The datasets are shown in Tab. 1 and Tab. 2. Table 1: The Description of datasets from SNAP Table 2: The Description of datasets from UCI This experiment was carried out under the PageRank and K-means tasks respectively,meanwhile completed under different sizes of data sets. In this experiment, we mainly compare and analyze the difference in execution time and memory utilization rate under without RDD cache selection and with RDD cache selection. As shown in Fig. 5, the results of each experiment are obtained by running 5 times. The Figs. 5(a) and 5(b) show the experimental results under the PageRank task, while the Figs. 5(b) and 5(c) are under the K-means. Through the comprehensive analysis of Figs. 5(a) and 5(c), when the dataset is relatively small, the task execution time is short, so the difference is not obvious. Along with the amount of data increases, the performance with the prediction mechanism for caching is well. Through the comprehensive analysis of Figs. 5(b) and 5(d), the memory usage of the task with the prediction mechanism is very high mainly because the cache data will occupy storage memory after the cache mechanism is optimized. In summary, the prediction mechanism for caching reduce the execution time and improve the rate of memory usage to a certain extent. Figure 5: Schematic diagram of task execution time and memory utilization under optimization and unoptimized cache mechanism This part is implemented by modifying theevictBlocksToFreeSpacefunction in the source file namedMemoryStore. The datasets of WikiTalk and NIPS_1987-2015 have been used in this verification separately. To ensure that there are multiple RDDs to be cached, the dataset is divided into several small datasets separately in the process of data reading by analyzing implementation code of PangRank and K-means. Now this process satisfies the conditions for multiple RDDs to be cached. Another condition is that there are RDDs that need to be cached, so we verify the weight replacement algorithm by using the RDD cache prediction mechanism proposed by this paper.This algorithm is called only when the storage memory is insufficient. So this experiment is verified under different memory sizes: 1 G, 2 G, 3 G and 4 G. As shown in Fig. 6,compared with LRU algorithm, when the memory is small, our improved algorithm could not reduce the execution time well for the reason that the analyzing of the partition features and the updating for weight and memory could occupy much time. With the increase of memory, the weight replacement algorithm performs well. When the memory is large, there is enough memory to store the cache partition, and the number of the partition replacement is reduced. As we can see that the execution time of the two algorithms is similar with enough memory. As Fig. 7 shown, we use the task execution speedup to measure the task performance.According to the Formula (1), it respectively shows the speedup under PageRank with WikiTalk andK-means with NIPS_1987-2015. As we can see, the optimized algorithm shows the poor performance in 1 G memory. While with the larger memory, it shows good performance. When the memory is large enough, the optimization algorithm advantage is no longer obvious. Figure 7: Task execution speedup with different tasks The By analyzing the characteristics of the Spark RDD data model, we propose three points: (1) Proposing prediction mechanism for RDD cache through the usage frequency of RDD, and the cost of re-computation and cache. (2) Based on the entropy method, we propose a weight model based on RDD partitioning feature by analyzing the remainder frequency of RDD partition, computational cost and the size of partition. (3) Putting forward the update mechanism for storage memory and weight of partition. In the actual running scene, the memory of the cluster environment is limited. For the multitask execution with big data, this method can effectively reduce the task execution time and improve the memory utilization. Acknowledgement:This paper is partially supported by Education technology research Foundation of the Ministry of Education (No. 2017A01020).3.4 The update mechanism for storage memory and weight of partition

4 Experimental verification

4.1 The verification for RDD cache prediction mechanism
4.2 The verification for weight replacement algorithm
5 Conclusion
 Computers Materials&Continua2018年9期
Computers Materials&Continua2018年9期
- Computers Materials&Continua的其它文章
- Fast Near-duplicate Image Detection in Riemannian Space by A Novel Hashing Scheme
- In Situ Synthesis of Cuprous Oxide/Cellulose Nanofibers Gel and Antibacterial Properties
- Perceptual Gradient Similarity Deviation for Full Reference Image Quality Assessment
- Mitigating Content Caching Attack in NDN
- Feature Relationships Learning Incorporated Age Estimation Assisted by Cumulative Attribute Encoding
- Provably Secure APK Redevelopment Authorization Scheme in the Standard Model