
Constrained Multi-Objective Optimization With Deep Reinforcement Learning Assisted Operator Selection
2024-04-15 09:37:02FeiMingWenyinGongLingWangandYaochuJin
Fei Ming , Wenyin Gong ,,, Ling Wang ,,, and Yaochu Jin ,,
Abstract—Solving constrained multi-objective optimization problems with evolutionary algorithms has attracted considerable attention.Various constrained multi-objective optimization evolutionary algorithms (CMOEAs) have been developed with the use of different algorithmic strategies, evolutionary operators, and constraint-handling techniques.The performance of CMOEAs may be heavily dependent on the operators used, however, it is usually difficult to select suitable operators for the problem at hand.Hence, improving operator selection is promising and necessary for CMOEAs.This work proposes an online operator selection framework assisted by Deep Reinforcement Learning.The dynamics of the population, including convergence, diversity,and feasibility, are regarded as the state; the candidate operators are considered as actions; and the improvement of the population state is treated as the reward.By using a Q-network to learn a policy to estimate the Q-values of all actions, the proposed approach can adaptively select an operator that maximizes the improvement of the population according to the current state and thereby improve the algorithmic performance.The framework is embedded into four popular CMOEAs and assessed on 42 benchmark problems.The experimental results reveal that the proposed Deep Reinforcement Learning-assisted operator selection significantly improves the performance of these CMOEAs and the resulting algorithm obtains better versatility compared to nine state-of-the-art CMOEAs.
I.INTRODUCTION
CONSTRAINED multi-objective optimization problems(CMOPs) contain multiple conflicting objective functions and constraints, which widely exist in real-world applications and scientific research [1].For example, web service location-allocation problems [2] and vehicle scheduling of urban bus lines [3].
The development of solving CMOPs by constrained multiobjective optimization evolutionary algorithms (CMOEAs)has seen prominent growth due to the wide existence of this kind of problem.Generally, a CMOEA contains three key components that affect its performance: the algorithmic strategy used to assist the selection procedures, the constraint-handling technique (CHT) to handle constraints, and the evolutionary operator to generate new solutions.In the past decade,a large number of CMOEAs have been proposed, most of which focus on enhancing algorithmic strategies [4]–[7] and CHTs [3], [8].By contrast, little research focused on how to adaptively select the evolutionary operator in CMOEAs has been reported in the literature.
According to [9], different evolutionary operators1An evolutionary operator means the operations of an evolutionary algorithm used for generating offspring solution, such as the crossover and mutation of GA, the differential variation of DE, and the particle swarm update of PSO/CSO.are suited to different optimization problems.For example,crossovers in genetic algorithms (GAs) [10] are effective in overcoming multimodal features; mutations in differential evolution (DE) [11] can handle complex linkages of variables because they use the weighted difference between two other solutions.The particle swarm optimizer (PSO) [12] shows good performance on convergence speed and the competitive swarm optimizer (CSO) [13] is good at dealing with largescale optimization problems because of its competitive mechanism, and the multi-objective PSO (MOPSO) [14], [15] is particularly designed and effective for multi-objective situations.Given the fact that a real-world CMOP is usually subject to unknown features and challenges, using a fixed evolutionary operator will limit the applicability of a CMOEA.Although ensemble and adaptive selection of operators have received increased attention in the multi-objective optimization community [16]–[18], unfortunately, no research efforts have been dedicated to constrained multi-objective optimization.Hence, it is necessary to study the effect of adaptive operator selection in dealing with CMOPs.
Among the reinforcement learning community, deep reinforcement learning (DRL) is an emerging topic and has been applied in several real-world applications in the multi-objective optimization field [19]–[23].Also, its effectiveness in dealing with multi-objective optimization problems (MOPs)has been studied recently [17], [24], [25].Since DRL uses a deep neural network to approximate the action-value function,it can handle continuous state space and thereby is suitable for operator selection for CMOPs because a population could have infinite states during the evolution.Therefore, it is promising to adopt DRL techniques to fill the research gap of operator selection in handling CMOPs.However, when applying DRL to CMOPs, the main challenge is to properly consider constraint satisfaction and feasibility in a DRL model.
This work proposes a DRL-assisted online operator selection framework for CMOPs.Specifically, the main contributions are as follows:
1) We propose a novel DRL model for operator selection in CMOPs.The state of the population, including the convergence, diversity, and feasibility performance, is viewed as the state, the candidate operators are regarded as actions, and the improvement of the population state is the reward.Then, we develop a deep Q-learning (DQL)-assisted operator selection framework for CMOEAs.A deep Q-network (DQN) is trained to learn a policy that estimates the Q-value of an action at the current state.
2) The proposed model can contain an arbitrary number of operators and the proposed framework can be easily employed in any CMOEA.In this work, we develop an operator selection (OS) method and further instantiate it by using GA and DE as candidate operators in the DRL model.Then, the OS is embedded into four popular CMOEAs: CCMO (coevolutionary framework for constrained multiobjective optimization)[4], PPS (push and pull search) [26], MOEA/D-DAE (multiobjective evolutionary algorithm with detect-and-escape) [27],and EMCMO (evolutionary multitasking optimization framework for constrained multiobjective optimization) [7].
3) Extensive experimental studies on four popular and challenging CMOP benchmark test suites demonstrated that the OS method can significantly improve the performance of CMOEAs.Furthermore, compared to nine state-of-the-art CMOEAs, our methods obtained better versatility on different problems.
The remainder of this article is organized as follows.Section II introduces the related work.Section III elaborates on the proposed methods.Then, experiments and analysis are presented in Section IV.Finally, conclusions and future research directions are given in Section V.
II.RELATED WORK AND MOTIVATIONS
A. Preliminaries
Without loss of generality, a CMOP can be formulated as
wheremdenotes the number of objective functions;x=(x1,...,xn)Tdenotes the decision vector withndimensions (i.e., the number of decision variables);x∈R, and R ?Rnrepresents the search space.gi(x) andhj(x) are thei-th inequality andjth equality constraints, andqdenotes the number of constraints.
In a CMOP, the degree of thej-th constraint violation (CV)of a solutionxis
whereσis a small enough positive value to relax the equality constraints into inequality ones.The overall CV ofxis
xis feasible if ? (x)=0; otherwise, it is infeasible.
B. Adaptive Operator Selection in MOPs
In recent years, adaptive operator selection is gradually attracting research attention in the design of multi-objective optimization evolutionary algorithms (MOEAs).
Wanget al.[16] proposed a multi-operator ensemble method that uses multiple subpopulations for multiple operators and adjusts their sizes according to the effectiveness of each action to reward good operators and punish bad ones.Tianet al.[17] adopted DRL to construct an adaptive operator selection method for MOEA/D.The proposed DRL model regards the decision vectors as states and the operators as actions; then, the fitness improvement of the solution brought by the operator is taken as the reward.Santiagoet al.[28] suggested a fuzzy selection of operators that chooses the most appropriate operators during evolution to promote both diversity and convergence of solutions.Donget al.[18] devised a test-and-apply structure to adaptively select the operator for decomposition-based MOEAs.The proposed structure contains a test phase that uses all operators to generate offspring and test the survival rate as the credit of operators.Then, the apply phase uses only the best operator for the remaining evolution.Yuanet al.[29] investigated the effect of different variation operators (i.e., GA and DE) in MOEA.McClymont and Keedwell [30] proposed a Markov chain hyper-heuristic that employs Reinforcement Learning and Markov chains to adaptively select heuristic methods, including different operators.Linet al.[31] devised a one-to-one ensemble mechanism that measures the credits of operators in both the decision and objective spaces and designed an adaptive rule to guarantee that suitable operators can generate more solutions.
C. DRL and Its Applications in MOPs
As we know, evolutionary computation aims to find the optima from a static environment.However, reinforcement learning can learn an optimal coping strategy in a dynamic environment [32].The policy enables the agent to adaptively take actions that gain the largest cumulative reward at the current environmental state [33].Different from reinforcement learning, DRL uses a deep neural network to approximate the action-value function.More specifically, Q-learning learns a policy through a discrete Q-table that records the cumulative reward of each action at each state [34].In contrast, DQL trains a Q-network that approximates the action-value function to estimate the expected reward of each action [35].The action-value function is also known as a probability model that estimates the probability of taking each action.Generally,DQL has two types of working principles.We assume that the DQN is trained, where two types are depicted in the left half and right half of Fig.1, respectively.For the Type-I DQL model, the input includes a state and an action (shown in a cube), and the output is the Q-value of this action under this state.For the Type-II DQL model, the input contains only the state, and the DQN can output the Q-values of all actions.
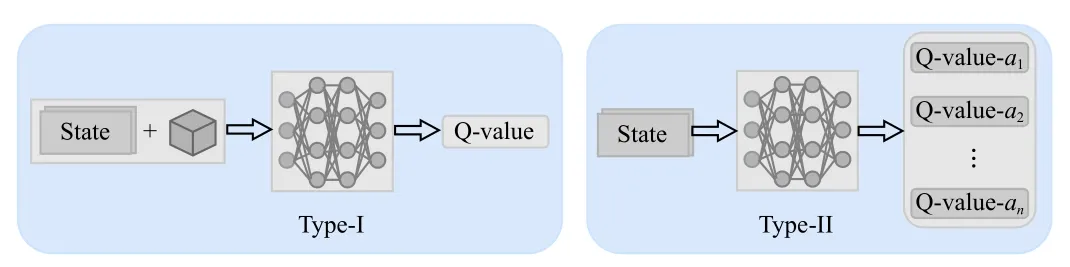
Fig.1.An illustration of two types of working principles of the DQL technique.
Without loss of generality, DQL trains a Q-network through the loss function
where T is the training data randomly sampled from an experience replay (EP); the experience replay is a data set that records historical data for the training of the Network;Q(st,at)is the output of the Network with the input (st,at) andaT, andqtis the Q-value of taking actionatat the statest, which is formulated as
whereQ(st+1,a′) is the maximum reward of taking the next action under the state whereatis performed.Therefore,qtcan not only calculate the current reward of performing actiona,but also estimate the maximum cumulative reward in the future.
Recently, DRL techniques are attracting more and more attention in the multi-objective optimization community.Researchers either employ DRL techniques to solve realworld MOPs or utilize them to enhance the performance of MOEAs.
1)Applications in Real-world MOPs: Liet al.[22] presented a DRL-assisted multi-objective bacterial foraging optimization algorithm for a five-objective renewable energy accommodation problem.Caviglioneet al.[20] suggested solving the multi-objective placement problem of virtual machines in cloud data centers by a DRL framework that selects the best placement heuristic for each virtual machine.Schneideet al.[19] designed a DRL-based DeepCoord approach that trains an agent to adaptively learn how to best coordinate services without prior and expert knowledge in dealing with a three-objective service coordination problem.
2)Applications in MOEAs: Tianet al.[17] used the DRL technique to adaptively select the evolutionary operators in dealing with MOPs.In their methods, the decision variable of a solution is regarded as the state, the operator is regarded as the action, and the improvement of fitness of the solution is the reward.Liet al.[24] proposed modeling each subproblem decomposed by the reference vectors as a neural network and generating Pareto-optimal solutions directly through the trained network models.They modeled the multi-objective TSP (MOTSP) as a Pointer Network and solved it using DRL techniques.Zhanget al.[25] developed a concise meta-learning-based DRL technique that first trains a fine-tuned metamodel to derive submodels for the subproblems to shorten training time.Then, the authors further used their technique to solve MOTSP and multi-objective vehicle routing problems with time windows.
D. Motivations
In the evolutionary computation community, evolutionary operators (also known as variation operators) that generate new candidate solutions for selection are an important part [9].A fixed operator can not be suitable for all problems according to the no free lunch theorem.Therefore, adaptive operator selection is widely recognized as an interesting and key issue for evolutionary computation [36].Although adaptive operator selection has attracted some attention in the multi-objective optimization community, unfortunately, there are currently no research efforts dedicated to the design of CMOEAs.Given that a CMOP inherits the features and challenges of MOPs other than its constraints, it is valuable and promising to develop adaptive operator selection methods for solving CMOPs.
During the evolution of solving a CMOP, the whole environment is dynamic because the population is different and unknown in advance at each iteration.Therefore, adopting reinforcement learning techniques to solve the adaptive operator selection issue is intuitively effective.However, traditional reinforcement learning techniques such as Q-learning may be less effective in dealing with such problems because the environment can include an infinite number of states, that is, the search space is continuous but Q-table can only handle discrete state space.In contrast, DRL techniques that train a deep neural network as the policy are suitable for the continuous and infinite state space.due to the recursive nature of this formula [17].As a result,DRL techniques such as DQL are more suitable for the evolutionary process of CMOEAs since both historical and future performance should be considered in the heuristic algorithms[37].Thus, DQL is very promising for adaptive operator selection.
Meanwhile, there are some challenging issues that must be resolved to successfully apply DRL to CMOPs.Since a CMOP contains constraints, it is necessary for a DRL model to consider constraint satisfaction and feasibility in the design of the state and reward.In addition, the effectiveness of an action (i.e., operator) on both handling constraints and opti-
Another advantage of DRL techniques is that the outputqtof (5) contains not only the current rewardrtbut also the maximum expected reward after taking this action.Consequently,qtcan represent the maximum cumulative reward in the future mizing objectives should be evaluated in training the DRL model.
To adopt DQL in CMOEAs, we need to develop a model that determines the state, action, reward, and learning procedure.Our proposed DQL model and the DQL-assisted CMOEA framework are elaborated on in the next section.
III.PROPOSED METHODS
A. Proposed DRL Model
In this work, the evolutionary operators are regarded as actions, thus the actions include
whereopiis theith evolutionary operator such as GA, DE,PSO, and CSO, andkis the number of candidate operators.It should be noted that in our proposed model, any number of operators can be used as candidates.
Then, we define the state of a population by considering its performance in terms of convergence, diversity, and feasibility.The average sum of objective functions of solutions in the population is used to evaluate the convergence of the population in the objective space, i.e., the approximation to the CPF(constrained Pareto front).Specifically, it is formulated as
wherefj(x) is thej-th objective function value.When the population approximates the CPF,conwill become smaller.The objective functions are not normalized due to the following underlying considerations.After normalization, all objectives
will belong to [0,1].Although the influence of different scales can be eliminated, theconfails to represent the real distribution of the population.
The average CV value of solutions in the population is used to estimate feasibility, i.e., the distribution of the population in the feasible/infeasible regions.Specifically, it is formulated as
where ?(x) is the CV ofx.If all solutions of the population are in feasible regions,feais zero.Otherwise, it will be a large value if the population is located outside the feasible regions.
The sum of scales, in all objective dimensions that the population covers, is used to estimate the diversity of the population.Specifically, it is formulated as

Then, we use three components to form a state.The state set is
It usescon,fea, anddivto reflect the current state of the population.In this case, whether an operator should be selected depends on a comprehensive evaluation of the current population state and its effectiveness in enhancing these performances.
The reward is calculated by
wherecon′,fea′, anddiv′are the new state of the population for the next generation.The reward we define in this work represents the improvement of the population state, including the performance in terms of convergence, diversity, and feasibility.Therefore, the effectiveness of a selected operator can be comprehensively evaluated.It is necessary to note that these three terms are normalized when they are input to the network as training/predicting data.
A record is formed as
and the EP is formed as
Such a data structure enables the EP to record the state, the selected operator, the reward, and the new state at each iteration.Thus, when training the network, the training data include all necessary items to approximate the action-value function in handling the operator selection issue.
Based on the above definitions and proposals, we develop a DQL model for operator selection for CMOEAs.The proposed model is shown in Fig.2.This model contains four procedures, they are:
1)Evolution Procedure: In the evolution procedure, the CMOEA generates offspring by the selected operator (determined by the DQN) and determines solutions that can survive to the next generation.
2)Interaction Procedure: In the interaction procedure, the agent and the environment exchange information and interact with each other.The agent gives the environment an action(i.e., operator) and the environment generates feedback (i.e.,reward) from the evolution of the CMOEA for the agent.
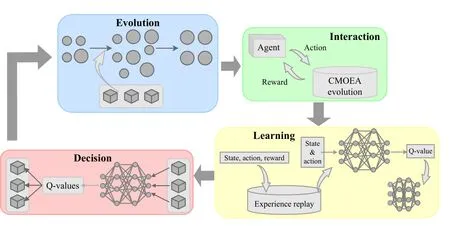
Fig.2.The illustration of the proposed DQL model.
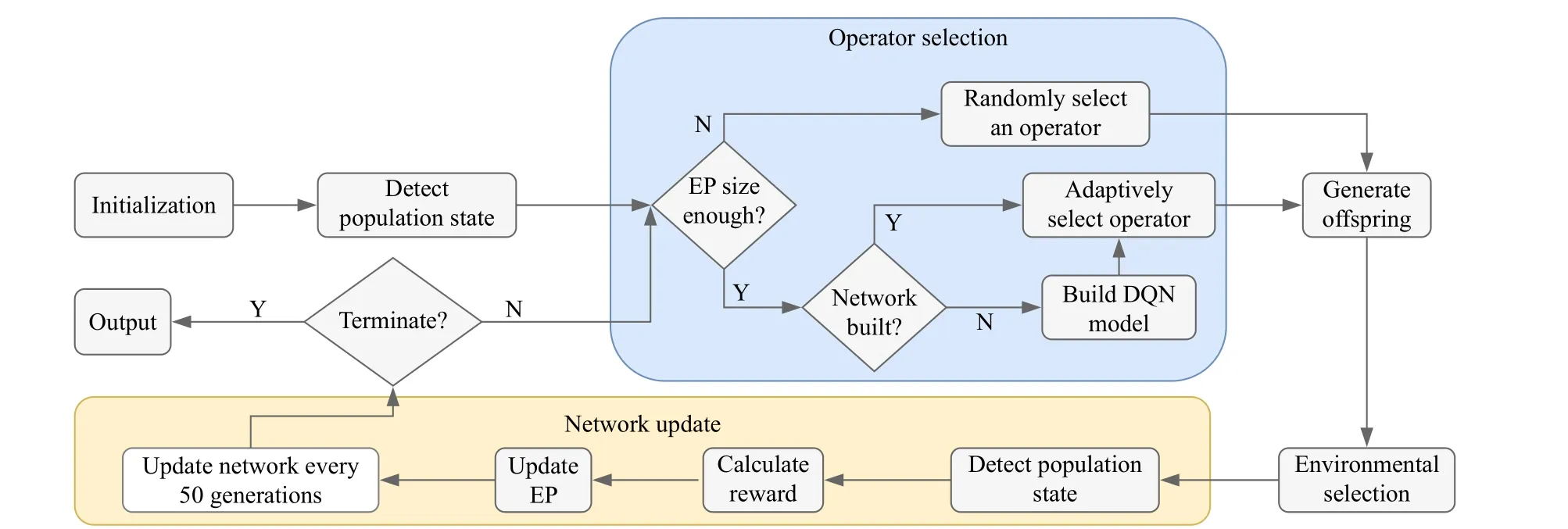
Fig.3.The flowchart of the proposed DQL-assisted CMOEA framework.
3)Learning Procedure: After the agent receives the feedback, it learns and improves the policy in the learning procedure.First, the record of the current iteration is added to the EP.Second, the DQN is trained based on the training data sampled from the EP.The input of the DQN is state & action,which is to say, the population state and the adopted operator at one iteration.The output of the DQN is the Q-value of adopting that operator at that population state.
4)Decision Procedure: After the DQN is trained, the agent can use it to decide which action to take in the face of a population state.The decision procedure first estimates all Q-values of all actions.Then the action with the largest Q-value is selected.
The above four procedures execute in order at each iteration to achieve the DQL-assisted operator selection for CMOEA.
B. Proposed DQL-Assisted Framework
Based on the DQL model, we develop a DQL-assisted adaptive operator selection framework for CMOEAs.We present the flowchart of the proposed DQL-assisted CMOEA framework in Fig.3.The main steps are as those in a CMOEA (initialization, mating, and selection), except that the DQLassisted framework contains two additional parts.
The blue part contains the operator selection process.In this process, the size of the EP needs to meet the requirement before the DQN is trained because we need enough data to train the Network.If the size of the EP is not enough, we randomly select an operator at the iteration to give equal weight to each operator so that the exploration can be guaranteed.Otherwise, if the size of the EP meets the requirement and the DQN is not built, the DQN is first built.If the DQN has been trained, it is directly used to adaptively select an operator for the following steps.
After we get an adaptively selected operator, the offspring are generated based on the mating selection of the CMOEA,and the environmental selection of the CMOEA is conducted to determine the population for the next generation.
Then, the network update process (in yellow) is conducted.It mainly contains two specific parts.At each iteration, the population state is detected and the record is calculated.Afterward, the EP is updated by adding the record of this iteration.After every 50 iterations, the QDN is updated.The above steps continue until the termination condition is met.

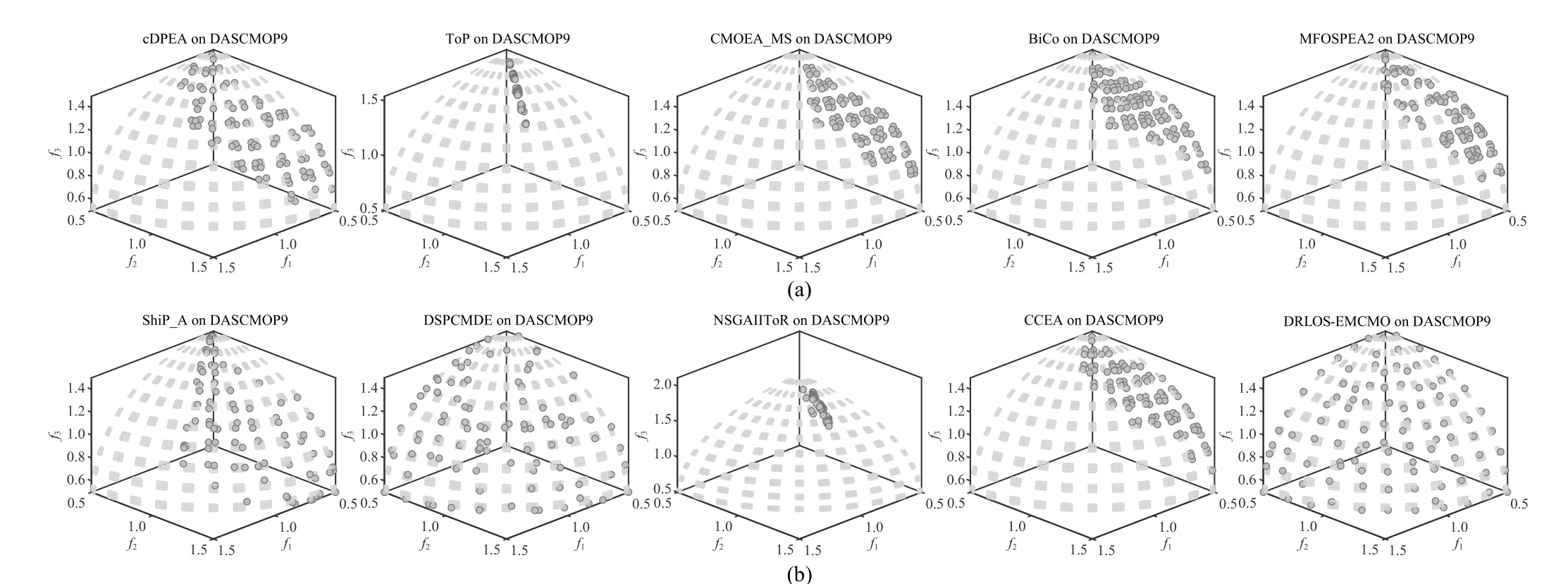
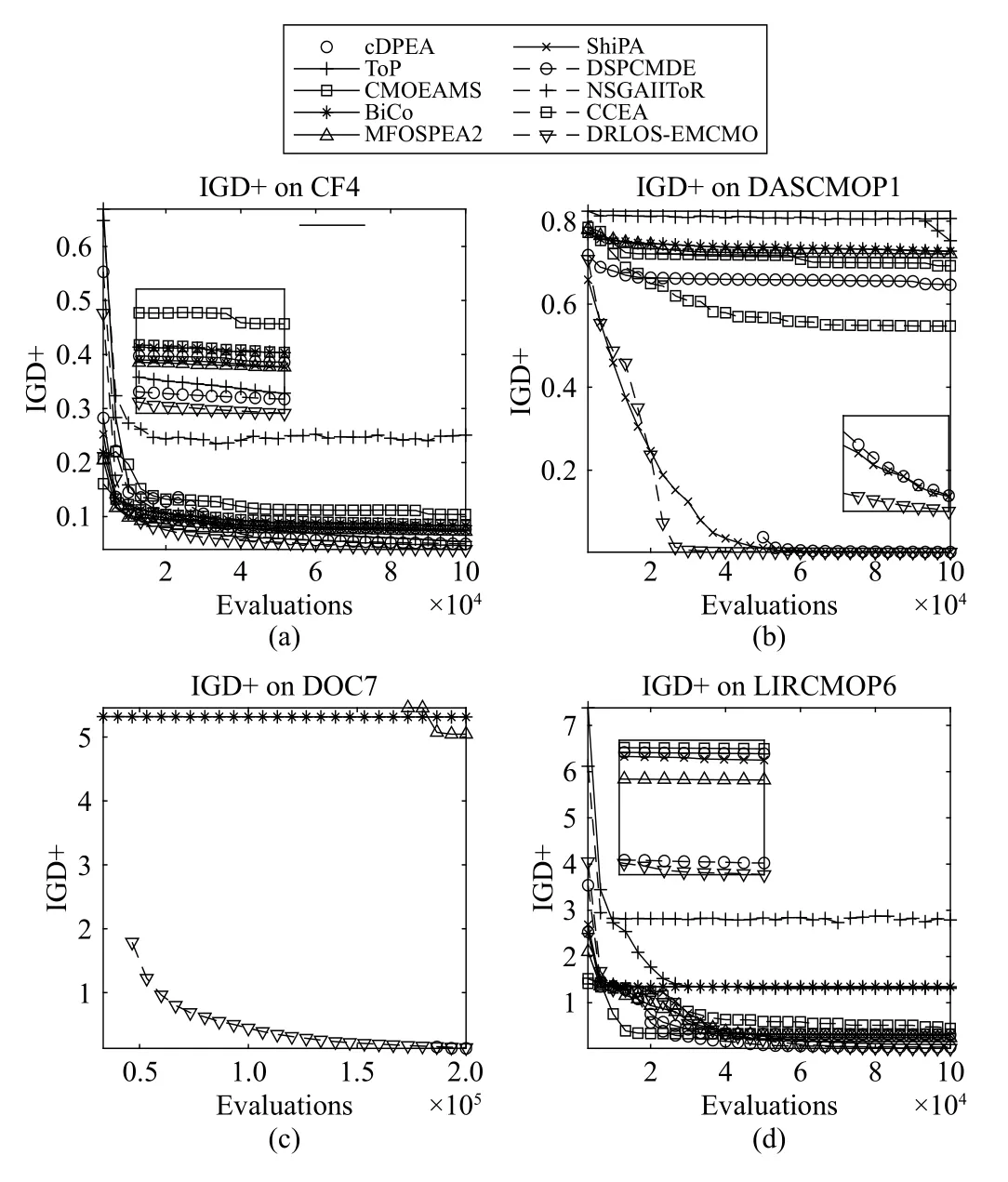
Algorithm 1 The DQL-Assisted Framework for CMOEAs Require: N (population size), (termination condition), i (number of operators), (maximum size of EP), (required size of EP)P Gmax msep rsep Output: (the output solution set of the CMOEA)1: Initialization of the CMOEA;2: Determine the state of the population;EP ←3: initialize the EP;g ←0 4: ;g The pseudocode of the proposed DQL-assisted framework for CMOEAs is presented in Algorithm 1.The inputs include the population size, the termination condition (maximum function evaluations), the maximum size of EP, and the required size of EP for training the DQN.The output is the same as the output solution set of the selected CMOEA.The main steps are consistent with the process in the flowchart.First, the initialization of the CMOEA is conducted to generate the initial population(s) for evolution (line 1).Then, the state of the initial population is determined (line 2) to prepare the first record.The EP set EP is initialized as empty then(line 3) and the index of the current generationgis initialized as zero (line 4).In the main loop, the following steps are performed: 1) If the EP has not meet the required sizersep, lines 7-11 are performed.First, an operator (denoted asith operator) is randomly selected (line 7).Then, the offspring set O is generated based on the operator and the mating selection of the CMOEA (line 8).Afterward, the environmental selection of the CMOEA is performed to select the population P for the next generation (line 9).According to this iteration, the reward and the new state are determined and used to form a new record t (line 10).Then EP is updated using the record t(line 11).It should be noted that EP is a queue that follows the first in, first out rule. 2) Otherwise if the EP has met the required sizersep, then lines 13-20 are performed.In the beginning, the DQNQis not built, so it is initialized using data from E P by Algorithm 2(line 14). 3) In the later iterations where the DQN has been built, lines 16-20 are performed.First, an operator is adaptively selected according to the current state and the DQL-assisted method presented in Algorithm 3 (line 16).Then the offspring set O is generated by the CMOEA using the selected operator (line 17).Afterward, the population for the next generation is selected based on the environmental selection of the CMOEA(line 18).Finally, the new record is formed (line 19) and the EPis updated (line 20). 4) Once every 50 iterations, the DQN is updated usingEP by Algorithm 3 (line 25).This step guarantees that the DQN can approximate the recent environment. Finally, the output solution set of the CMOEA is output as the final solution set (line 25). In this work, we adopt a simple Back-propagation neural network as the DQN.The detailed parameter settings of the adopted DQN architecture are listed in Table I.When the DQN is trained or updated, the procedure of Algorithm 2 is conducted. The inputs include the experience replay EP and the required size of training datastr.The output is a DQNQ.First,strrecords are sampled from E P and form a set T as the training data (line 1).Then, the former four items (i.e., the statestand the actionat) are used as the input of the DQN(lines 2 and 3), while the fifth item (i.e., the rewardrt) is used as the output of the DQN (line 4).The last three items are used to train DQN as thest+1in (5) (line 5).An important step is that we need to normalize the inputs and output to eliminate the influence of different scales so that the DQN can be accurately estimated (line 6).Then, the normalized training data is used to train the DQN using (4) as the loss function(line 7). The OS method in this work is similar to the common method of selecting the action in Reinforcement Learning.The detailed Pseudocode is presented in Algorithm 3.The inputs include the possibility of a greedyεto control the possibility of selecting the operator by DQN or in a random method.They also include the current population states, the operator set A, and the DQNQ.The output is the selected operatora.First, a random numberkbetween [0,1] is generated (line 1).Ifkis less than the possibility of greedy, the DQN is used to select an operator (lines 3 and 4).When DQN is used, all operators are tested through the DQN, and the one with the maximum reward is adopted.Ifkis greater thanε, the index of the selected operator is randomly generated (line 6)to guarantee exploration.In this work, we use GA and DE operators (i.e., their crossover and mutation strategies) as the candidate actions to instantiate the framework.The reasons for selecting these two operators are two-fold: 1) First, GA and DE are the two most commonly used operators in existing CMOEAs; 2) Second, GA can handle multimodality well and has a strong capability for convergence, while DE can handle linkages well and is good at exploring the decision space [9]. It is worth noting that before the E P meets the required size(i.e., line 6 in Algorithm 1), the operator is randomly selected to enhance exploration.Also, parameterεenables some random selection to enhance the exploration. According to Algorithms 1-3, the computational complexity of our methods is determined by three components, i.e., the selected CMOEA, the training of DQN, and the calculations of population state.The complexity of training the DQN (a Backpropagation neural network) isO(4u2) if we useuto represent the number of neurons.The time consumption of calculating the state isO(mnN).The time complexity of a CMOEA is usuallyO(mN2) toO(N3) (e.g., CCMO [4]).Therefore, the overall computational complexity is determined by the selected CMOEA. The differences between our proposed operator selection method and existing adaptive operator selection methods are two-fold: 1) Our method can apply to CMOPs because the design of the DQL model and the algorithmic framework both consider constraints and the feasibility of solutions, but existing methods are not applicable to CMOPs. 2) Our method is based on DQL, which can evaluate the improvement of the population brought by the selected operator in the future, while existing methods can only evaluate the improvement according to historical evolution. Although Tianet al.[17] also proposed a DQL-assisted operator selection method, our methods are different from theirs in three aspects: 1) This work handles CMOPs, while the topic of [17] is unconstrained MOPs.Handling CMOPs is more difficult than MOPs due to the existence of constraints. 2) Our proposed DQL model is different from the model in[17].In [17], the decision variable is regarded as the state, and the improvement of a single solution (offspringvsparent solution) is regarded as the reward. 3) The method in [17] is a specific algorithm for MOPs,while our proposed framework can be embedded into any CMOEAs. The differences between our methodology and existing applications of DRL in solving MOPs are as follows: 1) First, this work proposes a universal adaptive operator selection framework that can be used in any algorithm for CMOPs.By contrast, most existing applications focus on using DRL to solve a specific real-world application problem. 2) Second, most existing applications of DRL in solving MOPs can only solve discrete MOPs, while our method can solve any form of CMOP as long as the embedded operators and the adopted CMOEA can handle discrete or continuous decision variables. This section presents the experimental studies.Section IV-A presents the detailed experimental settings.Section IV-B compares the DQL-assisted operator selection with the original CMOEA and random operator selection.Section IV-C gives the comparison studies between our method and state-of-theart CMOEAs.Section IV-D shows the parameter analyses of the DRL-assisted operator selection technique and the adopted neural network.Section IV-E studies the effectiveness of using two performance indicators, instead of the proposed simplistic assessments in (7) and (9), to assess the population state. 1)Benchmark Problems: In the experimental studies, we selected four challenging CMOP benchmark test suites to test our methods.The benchmarks include CF [38], DAS-CMOP[39], DOC [40], and LIR-CMOP [41].The main difficulties and challenges of these benchmarks are summarized in Table S-II in the Supplementary File. 2)Algorithms in Comparison: In this work, we embed our proposed DQL-assisted operator selection framework into four existing CMOEAs; they are CCMO [4], MOEA/D-DAE[27], EMCMO [7], and PPS [26].In the comparison studies,we selected nine state-of-the-art CMOEAs for comparison,including methods using different operators.They are c-DPEA [42], ToP [40], CMOEA-MS [5], BiCo [43], MFOSPEA2 [6], ShiP-A [44], DSPCMDE [45], NSGA-II-ToR [8],and CCEA [46]. 3)Parameter Settings and Genetic Operators: For algorithms that use GA as the operator, the simulated binary crossover (SBX) and polynomial mutation (PM) [47] were used with the following parameter settings: a) Crossover probability waspc=1; distribution index was ηc=20; b) Mutation probability waspm=1/n; distribution index was ηm=20.CRFor algorithms that use DE as the operator, the parameters andFin the DE operator were set to 1 and 0.5, respectively. The evolutionary settings and parameters of our methods are presented in Table S-III in the Supplementary File.The explanations for the settings are also presented in Section IV in the Supplementary File.All other parameter settings of the comparison methods were the same as in their original literature (i.e., the default settings in PlatEMO). 4)Performance Indicators: Inverted generational distance based on modified distance calculation (IGD+) [48] and hypervolume (HV) [48] were adopted as indicators to evaluate the performance of different algorithms.We used two Pareto-compliant indicators to achieve a sound and fair comparison [49].Detailed information on these three indicators could be found in the Supplementary File.The valueNaNmeans an algorithm cannot find a feasible solution or the final solution set is far from the CPF. 5)Statistical Analysis: Each algorithm is executed 30 independent runs on each test instance.The mean and standard deviation values of IGD+ and HV were recorded.The Wilcoxon rank-sum test with a significance level of 0.05 was used to perform the statistical analysis using the KEEL software [50].“+”, “-”, and “=” were used to show that the result of other algorithms was significantly better than, significantly worse than, and statistically similar to those obtained by our methods to the Wilcoxon test, respectively.AllNaNvalues of HV and IGD+ are replaced by zero and 100, respectively. In the first part of the experiments, we compare the CMOEAs embedded using the DQL-assisted operator selection method with the original CMOEAs using a fixed operator and the CMOEAs using random operator selection to verify the effectiveness of the DQL-assisted operator selection method.The results in terms of HV and IGD+ on the four benchmarks are presented in Tables S-V to S-XII in the Supplementary File. For the CFs, it can be found that DRLOS-CCMO and DRLOS-EMCMO significantly outperformed the corresponding methods using a fixed operator or random operator.However, CCMO and EMCMO perform better or at least competitively on the three-objective CF8-10, revealing that for these large objective space instances, the operators of GA can enhance convergence.As for MOEA/D-DAE and PPS, it can be determined that using random and adaptively selected operators outperformed using a fixed operator.For DAS-CMOPs,the superiority of CCMO and EMCMO on DAS-CMOP4-8 reveals that these instances prefer the GA operator.On the contrary, DAS-CMOP1-3 and DAS-CMOP9 prefer the DE operator.However, an adaptive operator selection method can better handle DAS-CMOP1-3 and DAS-CMOP9 than PPS using the DE operator, revealing that the DQL-assisted operator selection can learn to decide which operator to use according to the population state during evolution.For DOCs, the results are similar to those of CFs.DRLOS-CCMO and DRLOS-EMCMO performed significantly better than other methods, revealing that DOC prefers the DE operator and the adaptive selection method can accurately determine DE as the operator.Since PPS uses DE as the operator, the performance is not significantly influenced by operator selection on DOCs.The results among RandOS and DRLOS also reveal that using DRL to adaptively select operators during evolution performs better than random selection.For LIR-CMOPs, it is apparent that the proposed OS method can significantly improve the performances of all CMOEAs.Nevertheless, the results show that LIR-CMOP13-14 prefer GA as operator. To better understand the performance, we conduct the Friedman test with Holm correction at a significance level of 0.05 on all results.The average rankings and p-values are summarized in Table II.It can be found that the DQL-assisted operator selection method outperforms the fixed operator and random operator selection.For these four CMOEAs, using our proposed DQL-assisted operator selection method can improve their performance. In summary, our proposed DQL-assisted OS method can improve the performance of these CMOEAs.The DQLassisted operator selection method can better determine the operator based on the population state compared to using a fixed or randomly selected operator. After the verification of the proposed DQL-assisted OS method, we further compare the DRLOS-EMCMO algorithm with nine state-of-the-art CMOEAs to study the algorithmic performance of these CMOEAs.The statistical results on four benchmarks are presented in Tables III-V in this file and Tables S-XIII-S-XVIII in the Supplementary File. In general, DRLOS-EMCMO outperforms other CMOEAs on these challenging CMOPs.But it performed worse in some CMOPs.Among the selected CMOPs, some instances rely on a particular operator.For example, the results show that DASCMOP4-8 and LIR-CMOP13-14 need the GA operator because of their multimodal feature.Besides, some instances of the CF test suite need the DE operator due to the linkage between variables.However, since the computational resources are used for all operators in DRLOS-EMCMO in the learning stage, DRLOS-EMCMO has fewer resources for the specifically needed operator in dealing with these problems, and thus, it performs worse.Additionally, it can be found that LIR-CMOP1-4, the CMOPs with an extremely small feasible region, require some constraint relaxation techniques such as penalty function in c-DPEA [42] and ShiP-A[3], orε-constrained in DSPCMDE [45] and CCEA [46].However, EMCMO does not contain a constraint relaxationtechnique, and thus, it performs worse on LIR-CMOP1-4.Except for these specific problems, DRLOS-EMCMO generally performs better than other CMOEAs. TABLE III STATISTICAL RESULTS OF IGD+ OBTAINED BY DRLOS-EMCMO AND OTHER METHODS ON DOC BENCHMARK PROBLEMS TABLE IV STATISTICAL RESULTS OF HV OBTAINED BY DRLOS-EMCMO AND OTHER METHODS ON LIR-CMOP BENCHMARK PROBLEMS. Fig.4.The final solution sets obtained by DRLOS-EMCMO and other methods on DAS-CMOP9 with the median IGD+ value among 30 runs. We depict the final solutions sets obtained by DRLOSEMCMO and other CMOEAs on CF1, DAS-CMOP9, DOC2,and LIR-CMOP8 in Figs.S-1 to S-3 in the Supplementary File and Fig.4 in this file.The results clearly show that DRLOS-EMCMO can approximate the CPF and obtain an even distribution in every instance.For DOC2, it can be found that only DRLOS-EMCMO can converge to two segments of the CPF, revealing that using GA performs worse than using an adaptively selected operator.As for LIR-CMOP8, it can be found DSPCMDE, adopting DE as the operator, also converges to the CPF.However, some dominant and extreme solutions remain, revealing that when GA can be adaptively selected, convergence can be further enhanced.Similarly for DAS-CMOP9, DSPCMDE finds fewer segments of the CPF compared to DRLOS-EMCMO, demonstrating that when GA can be used during evolution, the population can more effectively converge to the CPF and is less likely to get trapped in local optima. Additionally, we depict the convergence profiles of DRLOSEMCMO and other CMOEAs on CF4, DAS-CMOP1, DOC7,and LIR-CMOP6 in Fig.5.It can be determined that DRLOSEMCMO can not only achieve faster convergence speed but also obtain a better final indicator value. Fig.5.The convergence profiles on IGD+ of DRLOS-EMCMO and other methods on CF4, DAS-CMOP1, DOC7, and LIR-CMOP6 with the median IGD+ values among 30 runs. In summary, DRLOS-EMCMO outperforms these CMOEAs using a fixed operator, revealing that the DQL-assisted operator selection can achieve better versatility on different CMOPs. In the first part of parameter analyses, we change the required size of EP and the batch size to test its influence on training the DQL.Also, we change the greedy threshold to test the robustness of our method.The statistical results are presented in Tables S-XIX to S-L in the Supplementary File.It can be found that these two parameters have little influence on the performance in terms of all benchmark problems, demonstrating that our method is not parameter sensitive.Therefore current parameter settings are applicable when applying the DQL-assisted operator selection method to a new CMOEA. Then in the second part of parameter analyses, we conduct different settings of important parameters in the DQN, including the decay of learning rate, learning rate, number of iterations in training, and number of nodes in each hidden layer, to test the influence of these parameter settings.Detailed explanations of variants are reported in Table S-IV in the Supplementary File.In this part, only DRLOS-EMCMO is adopted to save space.Statistical results of HV and IGD+ are reported in Tables S-L to S-LVIII in the Supplementary File.On all benchmark problems, different parameter settings have little or no significant influence on DRLOS-EMCMO, revealing that the DQN adopted in this work is not parameter sensitive. In this part, we adopt two indicators, HV [48] and Spacing[51], to estimate the population state, respectively.These two indicators are selected because they do not need prior knowledge of the true PF.Compared to the items used in (7) and (9),HV and Spacing are two more sophisticated indicators that can provide a more concise estimation of the population state.The HV indicator can evaluate convergence and diversity,while the Spacing indicator can evaluate diversity. The results are reported in Tables S-LIX and S-LX in the Supplementary File, according to which the following conclusions can be found. 1) For CCMO and EMCMO, using simplistic evaluations as in (7) and (9) performs better when dealing with DSACMOP1-3 and DOCs, revealing that a sophisticated evaluation can easily lead to local optima because these instances need not only operators of GA but also other operators.In contrast, using HV and Spacing indicators performs better on DAS-CMOP4-9 which prefers GA.The indicators provide a more concise estimation of the dynamics of the population,allowing the algorithm to determine how to select operators of GA. 2) For MOEA/D-DAE, the choice of simplistic or sophisticated evaluations has no significant influence on the performance. 3) For PPS, using sophisticated evaluations performs significantly worse on instances with no preference for operators of GA and performs better on some instances with a preference for operators of GA, which further demonstrates that a simplistic evaluation has better versatility. In this article, we propose a DQL-assisted online operator selection method for CMOPs, filling the research gap in operator selection in CMOPs and introducing DRL techniques to CMOPs.We develop a DQL model that uses population convergence, diversity, and feasibility as the state, the operators as actions, and the improvement of the population state as the reward.Based on this DQL model, we develop a versatile and easy-to-use DQL-assisted operator selection framework that can contain any number of operators and be embedded into any CMOEA.We embedded the proposed method into four existing CMOEAs.Experimental studies have demonstrated that the proposed adaptive operator selection method is effective, and the resulting algorithm outperformed nine state-ofthe-art CMOEAs. Nevertheless, some issues must be addressed regarding the current study of this paper.According to the experimental results, DRL-assisted CMOEAs perform worse when a CMOP prefers specific operators.Therefore, it is necessary to improve learning efficiency so that fewer computational resources can train a more accurate DRL model to determine the desired operators.Moreover, increasing the maximum number of function evaluations in the experiments may improve the numerical performance of DRL-assisted CMOEAs, which is also true when the proposed method is applied to real-world problems. In the future, the following directions are worth trying: 1) Some other operators can be embedded to extend this framework to solve other kinds of MOPs.For example, the CSO [13] or other enhanced operators [52] can be embedded to solve large-scale CMOPs [53].In addition, some advanced learning-based optimizers such as switching particle swarm optimizers [54], [55] can be used as actions to enhance performance. 2) Advanced neural networks [56] can be employed as the DQN to see if they can enhance the performance of the proposed DQL-assisted operator selection method. 3) Moreover, hyperparameter adaptation [57] is necessary for future study since there are many hyperparameters that need to be adjusted. The codes of the methods in this work can be obtained from the authors upon request.C. Train/Update the DQN
D. Proposed OS Method
E. Computational Complexity
F. Remarks
IV.EXPERIMENTAL STUDIES
A. Experimental Settings
B. On the Effectiveness of DQL-Assisted OS
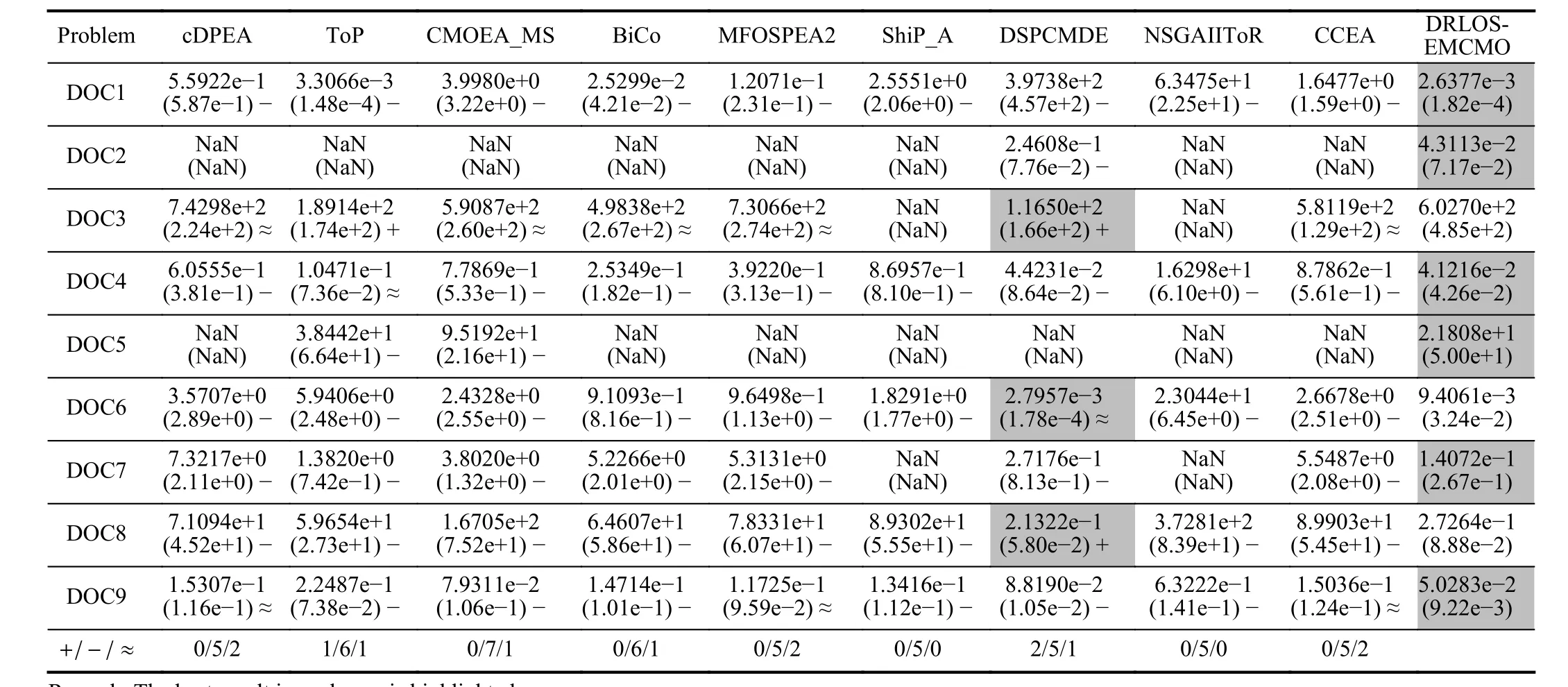
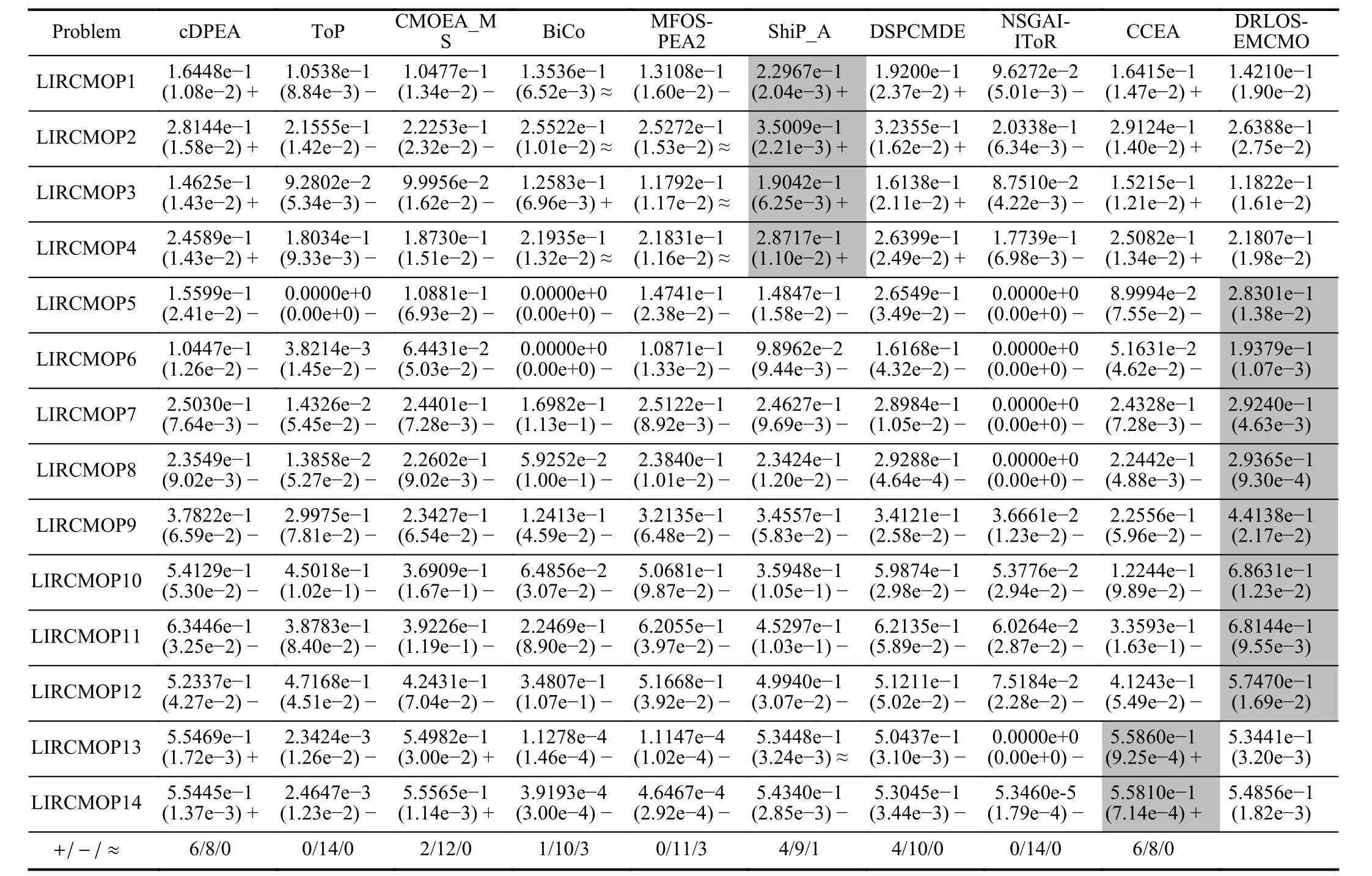
C. Comparison Studies
D. Parameter Analyses
E. Ablation Studies on Assessing Population State Using Indicators
V.CONCLUSIONS AND FUTURE WORK
 IEEE/CAA Journal of Automatica Sinica2024年4期
IEEE/CAA Journal of Automatica Sinica2024年4期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Parameter-Free Shifted Laplacian Reconstruction for Multiple Kernel Clustering
- A Novel Trajectory Tracking Control of AGV Based on Udwadia-Kalaba Approach
- Attack-Resilient Distributed Cooperative Control of Virtually Coupled High-Speed Trains via Topology Reconfiguration
- Synchronization of Drive-Response Networks With Delays on Time Scales
- Policy Gradient Adaptive Dynamic Programming for Model-Free Multi-Objective Optimal Control
- Lyapunov Conditions for Finite-Time Input-to-State Stability of Impulsive Switched Systems