
Image Retrieval Based on Vision Transformer and Masked Learning
2023-10-29 11:41:44LIFengPANHuangsheng潘煌圣SHENGShouxiang盛守祥WANGGuodong王國棟
LI Feng(李 鋒), PAN Huangsheng(潘煌圣)*, SHENG Shouxiang(盛守祥), WANG Guodong(王國棟)
1 College of Computer Science and Technology, Donghua University, Shanghai 201620, China 2 Huafang Co., Ltd., Binzhou 256617, China
Abstract:Deep convolutional neural networks (DCNNs) are widely used in content-based image retrieval (CBIR) because of the advantages in image feature extraction. However, the training of deep neural networks requires a large number of labeled data, which limits the application. Self-supervised learning is a more general approach in unlabeled scenarios. A method of fine-tuning feature extraction networks based on masked learning is proposed. Masked autoencoders (MAE) are used in the fine-tune vision transformer (ViT) model. In addition, the scheme of extracting image descriptors is discussed. The encoder of the MAE uses the ViT to extract global features and performs self-supervised fine-tuning by reconstructing masked area pixels. The method works well on category-level image retrieval datasets with marked improvements in instance-level datasets. For the instance-level datasets Oxford5k and Paris6k, the retrieval accuracy of the base model is improved by 7% and 17% compared to that of the original model, respectively.
Key words:content-based image retrieval; vision transformer; masked autoencoder; feature extraction
0 Introduction
Currently, the mainstream technology in the field of image retrieval is content-based image retrieval (CBIR). The workflow of CBIR is to extract the visual features of the image, generate the corresponding feature descriptors, and finally use the similarity measure function for evaluation. Compact yet rich feature representations are at the core of CBIR[1]. Therefore, image feature extraction is an essential factor affecting the effectiveness of image retrieval.
CBIR methods are mainly available at the instance level and the category level. In instance-level image retrieval, a query image of a specific object or scene is usually given. The goal is to find images containing the same object or scene. The images may have different backgrounds. In contrast, category-level image retrieval aims to find images of the same class as the query.
In the last two decades, significant progress has been made in the image feature extraction, which consists of two essential phases: feature engineering and feature learning[1].
The feature engineering phase focuses on several low-dimensional semantic features extracted by mathematical computation, such as color features, texture features and shape or spatial location[2]. One of the better-handcrafted features in this area is the scale-invariant feature transform (SIFT)[3]. The bag of words (BoWs) model has achieved good results in image classification and retrieval through SIFT descriptors. However, the feature expression ability extracted by the BoWs is poor, so the performance of the image retrieval dataset is not very good. These low-level features need to be designed manually, and the retrieval stability in different scenarios is low.
Feature learning is mainly based on deep learning networks.It has been developed since 2012 with the rise of deep learning and the excellent results of deep convolutional neural networks (DCNNs) for image classification tasks[1]. In particular, with the great success of AlexNet[4]and networks such as VggNet[5], GoogleNet[6]and ResNet[7]in image classification, the exploration of DCNNs in image retrieval has also been launched. DCNNs can learn powerful feature representations with multiple levels of abstraction directly from the data, and these features work well for image retrieval. There are two main approaches to extract feature by DCNNs: using existing models and fine-tuning them. It is essential to know how to use the network more effectively to extract features.
With the success of the transformer architecture in the field of natural language processing (NLP), the superiority of the transformer has been demonstrated in image processing in the last two years. The vision transformer (ViT)[8]model has shown better results on image classification tasks. There are also many researchers investigating the use of the ViT model in downstream tasks in the image domain, such as detection transformer (DETR)[9]to obtain state-of-the-art (SOTA) results in the field of target detection and segmentation transformer (SETR)[10]to obtain the same SOTA results in semantic segmentation. However, the application of the ViT model in image retrieval is still relatively few, and the performance of the ViT model needs to be verified.
The existing network structures and their parameters were designed and trained on datasets for image classification tasks. When these networks are used on instance-level datasets to extract features, they cannot work well, so it is necessary to fine-tune the networks on these datasets. Supervised fine-tuning requires much time and labor to annotate images, so self-supervised learning is preferred.
In the paper, a masked learning-based approach is proposed for fine-tuning feature extraction networks. In detail, the ViT model is used as the backbone network for feature extraction, and the self-supervised masking learning method is combined to fine-tune the image in the specific domain. The influence of class vectors and average pooling strategy on feature extraction is discussed in detail, and a suitable feature extraction scheme is proposed for self-supervised learning. Four standard image retrieval datasets (Ukbench[11], Holidays[12], Oxford5K[13]and Paris6k[14]) are used to evaluate the performance.
1 Related Work
1.1 Vision transformer
The transformer[15]architecture was initially used in the natural language processing (NLP) domain and achieved SOTA on many NLP tasks. Convolutional neural network (CNN) architectures in the visual domain cannot transform images into sequences, and a transformer block is usually added after the CNN layer. In order to solve this problem, the ViT model divided the image into many 16 pixel×16 pixel image patches and then projected them into a fixed-length vector. The subsequent coding operation is the same as that of the transformer. Compared to traditional CNNs, more data are required in the ViT model to achieve better results due to the lack of inductive bias. There has been much-improved research, for example swin-transformer[16], to address the problem that the ViT model training requires a larger dataset and more time.
There are some applications of the ViT model in the field of image retrieval. Gkeliosetal.[17]applied the ViT model without fine-tuning to image retrieval, compared it with some traditional methods on several datasets and found that it worked well. Lietal.[18]used the ViT model as a backbone network to extract features and combine features with standard deep hashing methods for compressive coding. El-Noubyetal.[19]used the ViT model as the feature extraction network and combined it with metric learning methods. Yangetal.[20]proposed an EfficientNet model and a swin-transformer model based on the deep orthogonal fusion of local and global features (DOLG) model.
1.2 Self-supervised learning
In computer vision, most neural networks use supervised learning, which can be very time consuming and challenging due to the large amount of labeled data required. In contrast, deep learning networks can use self-supervised learning methods to train the network without labeled data.
There are currently three main categories of self-supervised learning in computer vision: (i) a pretext task, by constructing a task to drive the model for learning; (ii) contrastive learning, such as the MoCo[21-23]series of algorithms, SimCLR[24]series of algorithms, of which the core idea is that the same image undergoes different data enhancement methods and the extracted features still have high consistency; (iii) masked learning, such as BERT pre-training of image transformers (BEiTs)[25]and masked autoencoders (MAEs)[26], which mainly involves randomly masking blocks of images and reconstructing images of masked regions using images of unmasked regions.
Among them, masked learning is a more suitable self-supervised learning approach for the ViT model. ViT models are more conducive to combining models related to the NLP domain to generate larger multi-modal general models than traditional convolutional neural networks.
More research is needed on self-supervised fine-tuning in image retrieval[1], and there are currently two main approaches. One is manifold learning[27], which fine-tunes the network by mining correlations in features to find positive and negative samples in the dataset. The other one is the autoencoder method, which focuses on reconstructing the output, so it is as close to the input as possible. The MAE method used in this paper is the autoencoder method.
2 Methods
2.1 Overview
The fine-tuning and the feature extraction are focused on by using the MAE model on image retrieval datasets. As shown in Fig.1, a pre-trained checkpoint directly replaces the part left of the dashed line, and the right part is the work of this article. The MAE model is pre-trained and self-supervised on the ImageNet dataset. Then fine-tuning of the corresponding image classification dataset was supervised when image classification tasks were done. In this paper, the checkpoint model with self-supervised pre-training was used on the ImageNet dataset as the baseline model.
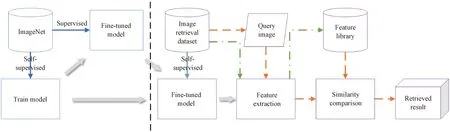
Fig.1 System flow diagram
The right side of the dashed line in Fig.1 shows the main workflow. The solid line represents the process of self-supervised fine-tuning of the model. The dot-dash line represents extracting features from the image retrieval dataset and building a feature library. The dashed line represents the final image retrieval process.
2.2 Self-supervised fine-tuning
In the field of NLP, bidirectional encoder representation from transformer(BERT)[28]uses a self-supervised approach to train the transformer model, the principle of which is to mask words randomly with a 15% probability and then predict the original words at the masked locations. MAE is the BERT of the vision domain, and its core idea is to mask some image patches in a picture at random with a certain percentage and then reconstruct the pixel values of these parts. The MAE model starts with self-supervised training on a large dataset, followed by supervised fine-tuning to achieve SOTA for the image classification task eventually.
As shown in Fig.2, MAE uses an asymmetric encoder-decoder design. The encoder part mainly encodes the image patches while the decoder reduces them. Only the unmasked images are encoded in the encoding phase, while all image patches are processed in the decoding phase. After completing pre-training, the decoder can be removed and only the encoder is used for the image retrieval task. The separable design of the encoder-decoder allows us to easily apply the encoder to downstream tasks.
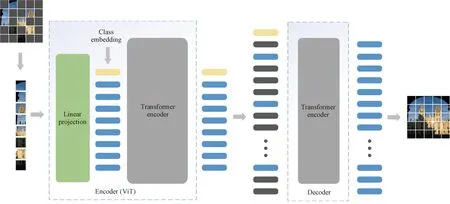
Fig.2 MAE architecture diagram[26]
The encoder architecture uses the ViT model. Taking the base model as an example, the image is usually firstly divided into multiple 16 pixel×16 pixel blocks. Then, each block is projected into a fixed-length vector by a linear layer, a particular class embedding vector is added, and all these vectors add position encoding. Finally, a series of transformer blocks are stacked together for self-attention (the main difference between different sizes of the ViT model is the number of stacked transformer blocks). Thus, the global features of the image can be well learned through the encoder and are suitable for image retrieval tasks. The difference between MAE and ViT is that here the encoder only needs to be passed in the unmasked image patches, thus speeds up the encoder’s processing. The encoder also discards the MLP layer from ViT and is only added for subsequent supervised fine-tuning.
The self-attention mechanism in the transformer encoder module is briefly introduced. As shown in Fig.3, the left part shows the architecture of the transformer encoder part, and the right part shows the schematic diagram of self-attention. The class vector does the attention operation with all other vectors:
(1)
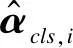
The class vector gets the global features from all vectors. While single attention obtains a single representation space, multi-head attention can obtain several different representation spaces, facilitating the model to learn different image features.
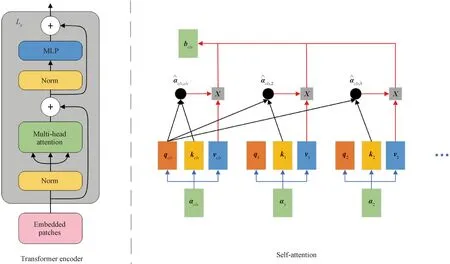
Fig.3 Architecture diagram of transformer encoder module[15]
The decoder usually uses fewer transformer blocks than the encoder, and the number of the transformer blocks set to be eight in the MAE base model. However, even one block can work. A checkpoint model pre-trained on a large dataset is used in this paper. The parameters of the decoder are frozen and only the encoder is trained to prevent the decoder from learning too much about the dataset features and affecting the representation of the image learned by the encoder.
Another feature of MAE is using a high masking rate which can be as high as 75% and MAE still recovers the original image using the model. Because there is too much redundant information, the interpolation method can recover the image when the masking rate is too low. The random masking operation is another image enhancement that can achieve a good result when there is little data in the dataset.
2.3 Feature extraction method
In the feature extraction phase, the MAE encoder is used. Specifically, the encoder uses pre-processed (size normalization and pixel normalization) images as input. The data sent to the encoder is no longer masked and the encoding operation is the same as the standard ViT architecture. After the image is divided into image patches and embedded into vectors, self-attention is done at these vectors by transformer blocks. There is no need for an MLP layer because feature extraction is focused on.
Taking the ViT base model as an example, after a single image passes through the encoder, a vector of 197×768 dimension is obtained, as shown in Fig.4. In the traditional CNN model, the feature map of the last convolutional layer is usually used to get a lower-dimensional vector for the subsequent retrieval using pooling. However, under the ViT framework, it can be found that the low-dimensional vector obtained by pooling the extracted vectors is less effective than using the class vector as the image descriptor. The class vector has learned enough feature expression when global self-attention operations are done with the image patch, so the class vector is an excellent global feature.
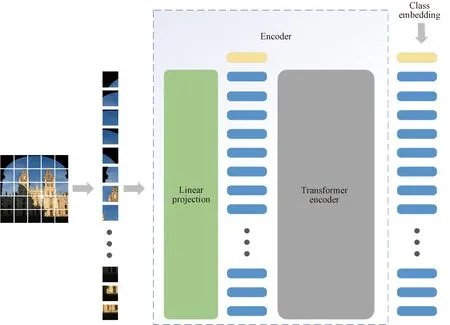
Fig.4 Feature extraction architecture diagram
3 Experiment
The experimental environment is described in detail and is evaluated by the proposed method in four available datasets.
3.1 Dataset
The Ukbench[11]dataset has 10 200 pictures. Four pictures are in one group and there are a total of 2 550 groups. The size of each image is 640 pixel×480 pixel, and the images in one group are taken from different perspectives and light conditions. The Ukbench dataset uses the average scores of the top four candidates to measure retrieval accuracy.
The Holidays[12]dataset consists of 1 491 photos taken by mobile phones, mainly including some personal holiday photos and a variety of scenes such as nature, architecture and humanities. The Holidays dataset consists of 500 image groups, each representing a different scene or object, and the number of images in each group ranges from 2 to 13. The first image of each group is the query image, and the correct retrieval results are the other images of the group.
The Paris6k[14]dataset contains 6 412 photos representing unique Paris landmarks. This collection contains 55 images of buildings and monuments from the request. There are more landmarks in Paris than in Oxford.
The Oxford5k[13]building dataset contains 5 062 images collected from the Flickr dataset by searching for specific Oxford landmarks. The dataset has been manually annotated to generate comprehensive ground conditions for 11 different landmarks. Five possible queries represent each landmark, and a total of 55 queries can evaluate the object retrieval system. In the Oxford5k building dataset, completely different views of the same building are marked with the same name, making the collection challenging for image retrieval tasks.
In the Ukbench dataset, the recall of the first four candidates is used to evaluate the retrieval performance. There are only four correct results for each query in the Ukbench dataset, so hereNocan represents the number of true positive cases. That is, in the best case,No=4.
No=Vo,
(2)
(3)
(4)
wherePprecisionis the precision of search results;Rrecallis the recall of search results;Vois the number of true-positive cases;Vuis the number of false-positive cases;Vwis the number of false-nagetive cases;
For Holidays, Paris6k, and Oxford5k datasets, the mean average precision (mAP) is generally used as the evaluation index. Based on the precision-recall curve, an array form of evaluation is average precision (AP), by calculating the average precision value corresponding to each recall value.
(5)
whereArepresents AP;nrepresents the total number of interpolation points;ri(i=1, 2, …,n-1) is the interpolation point for the recall values;Pinteris the accuracy value interpolation of the point.
The average value of all categories of AP is
(6)
wheremrepresents mAP;krepresents the total number of all categories;Airepresents each category of AP. In the best case, the maximum value of mAP is 100%.
3.2 Experiment details
Distance is used to measure similarity. Typical distance measures include Manhattan, Euclidean, cosine, Chebyshev, Hamming, and correlation distance measures. Here, cosine similarity is used to measure the similarity between features. The cosine similarity distance is mainly used to calculate the feature’s inner product space and compare the feature vector’s direction.
(7)
whereaandbrepresent two vectors which are needed to calculate the similarity, and their included angle isθ.
As shown in Eq. 7, the similarity range is [0, 1]. The smaller the angle between the two vectors, the closer the similarity to 1.
The L2 normalization is used:
(8)
wherexirepresents a vector that needs L2 normalization;yirepresents the L2 normalization vector;nrepresents the total number of vectors needed to be L2 normalized.
The experiment is carried out on the GPU workstation. The configuration includes Intel Xeon Bronze 3204, 64 G memory, two RTX2080Ti graphics cards, and the operating system Ubuntu 20.04. The deep learning framework uses the PyTorch framework, version 1.7.1. MAE uses the open-source PyTorch version of Meta. Since the implementation of the ViT module in MAE relies on the Timm library, the Timm0.3.2 version of ViT is used in this paper. Timm is an excellent open-source library of visual neural network models, which aims to integrate various SOTA models and can reproduce the training results of ImageNet.
The fine-tuning experiment in this paper combines data from the Ukbench, Holidays, Oxford5k, and Paris6k datasets into a large dataset for our training. The pre-trained checkpoint model is obtained from MAE because only the visual checkpoint model contains the decoder layer parameters, so the performance is slightly worse than that of the non-visual model.
For the base model, the image needs to be resized to 224 pixel×224 pixel. The optimizer uses AdamW, the base learning rate is 1.5x10-4, the weight decay is 0.05, the optimizer momentum is between 0.90 and 0.95, the batch size is 32, and 200 epochs are trained. Figure 5 shows the trend of loss and the learning rate in the training process of the base model after the decoder is frozen. It can be seen that after 200 epochs of training, the loss has been steadily declined, indicating that the training is practical.
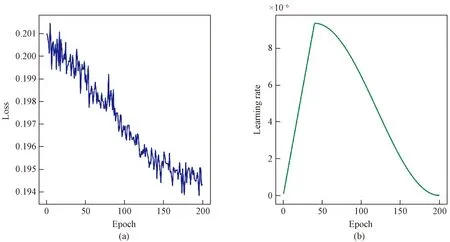
Fig.5 Trend of loss and learning rate during training: (a) loss; (b) learning rate
4 Results and Discussion
The performance of different fine-tuning methods on Ukbench, Holidays, Oxford5k, and Paris6k datasets is listed in Table 1. Visualize-raw is the pre-trained MAE visual checkpoint model; visualize-finetuned is the fine-tuned model using the checkpoint model; visualize-nodecoder is the fine-tuned model using the checkpoint model after freezing the decoder layer. The “base” in base-cls refers to the use of base model to extract image features, and the “cls” refers to the use of class vectors to represent image features. The base model is a standard MAE model, and the large model is a model with more transformer blocks stacked in the encoder.
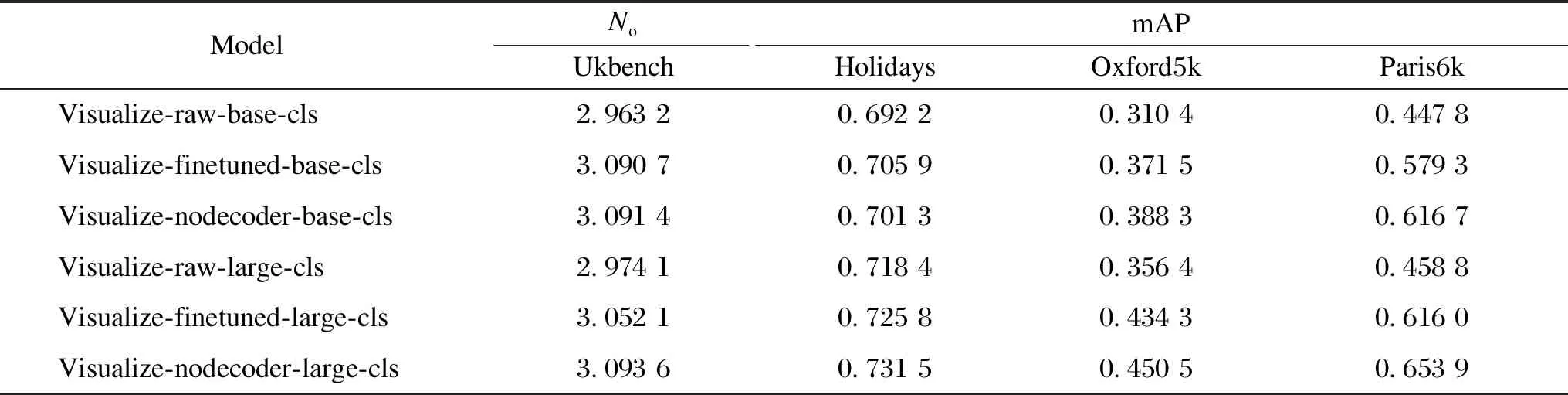
Table 1 Results on various datasets using different fine-tuning methods
It can be seen that the fine-tuning method has significant improvement on different datasets. Among them, the improvement on the Ukbench and Holidays datasets is not significant. However, for Oxford5k and Paris6k datasets, the mAP of the base model increases by 7% and 17%, respectively, and that of the large model increases by 9% and 19%, respectively. Ukbench and Holidays datasets are pictures of life. Such pictures account for a part of the dataset used in the pre-training of the MAE model, so the improvement is not significant after fine-tuning. Oxford5k and Paris6k datasets are mostly landmark buildings, and such images are less likely to appear during pre-training, so there is a noticeable improvement after fine-tuning by using the method in this paper.
Table 2 shows the comparison between the recognition results by using average pooling (avg) and cls as a feature, where finetuned-raw provides MAE’s checkpoint model with supervised fine-tuning on ImageNet. For the pre-training model, the cls vector is significantly better than the average pooling method, and the cls vector is still work better after self-supervised fine-tuning on the pre-training model. After supervised fine-tuning on the pre-training model, the average pooling method is more conducive to feature extraction. This phenomenon in self-supervised pre-training can be explained that the cls vector does global self-attention and is already a good image descriptor. When supervised fine-tuning, the cls vector is used as the input of the classification output head, which pays more attention to specific local objects and loses some global information. Hence, the average pooling method performs better. Therefore, when self-supervised fine-tuning, the cls vector is used as the image feature is better.

Table 2 Comparison of average pooling and cls vector as feature recognition results
For different versions of the same deep learning network, the performance on the same dataset is pretty different. Generally, the self-supervised training model is worse than the supervised model. As shown in Table 2, there is little difference in retrieval accuracy between unsupervised fine-tuning using cls vectors and supervised fine-tuning using cls vectors on Holidays, Oxford5k, and Paris6k datasets. Supervised training will pay more attention to specific objects (or local features) in the training process. In image retrieval, more attention is paid to specific objects in the image, so supervised models usually have better performance in retrieval. A simple look at the heat map (Fig.6) shows that a supervised training pays more attention to the local objects we expect to search, which undoubtedly improves the retrieval accuracy. The left side of each group is the heat map of the self-supervised pre-training model, and the right side is the heat map after supervised fine-tuning. Careful observation shows that the left map of each group generally pays more attention to the background of the sky and the ground. In comparison, the right map pays more attention to local buildings or reduces the attention to the background.

Fig.6 Eight groups of heat maps: (a) group 1; (b) group 2; (c) group 3; (d) group 4; (e) group 5; (f) group 6; (g) group 7; (h) group 8
5 Conclusions
In this paper, a self-supervised fine-tuning model is used to extract image descriptors in the field of image retrieval. This method has achieved good results on different datasets and used less time in image retrieval. The self-supervised fine-tuning method in this paper gets global features, and the global self-attention done by the ViT architecture also strengthens the global features. Local features could be used for fusion to get better results. With the continuous advancement of self-supervised learning and more optimization of the ViT architecture, such methods would indeed receive more attention in image retrieval.
 Journal of Donghua University(English Edition)2023年5期
Journal of Donghua University(English Edition)2023年5期
- Journal of Donghua University(English Edition)的其它文章
- Oscillation Reduction of Breast for Cup-Pad Choice
- Effect of Weft Binding Structure on Compression Properties of Three-Dimensional Woven Spacer Fabrics and Composites
- Optimization for Microbial Degumming of Ramie with Bacillus subtilis DZ5 in Submerged Fermentation by Orthogonal Array Design and Response Surface Methodology
- pth-Moment Stabilization of Hybrid Stochastic Differential Equations by Discrete-Time Feedback Control
- Semantic Path Attention Network Based on Heterogeneous Graphs for Natural Language to SQL Task
- Device Anomaly Detection Algorithm Based on Enhanced Long Short-Term Memory Network