
Automatic extraction and structuration of soil–environment relationship information from soil survey reports
2019-02-14 03:12:26WANGDeshengLIUJunzhiZHUxingWANGShuZENGCanyingMATianwu
WANG De-sheng , LIU Jun-zhi , ZHU A-xing , , WANG Shu , ZENG Can-ying , MA Tianwu
1 Key Laboratory of Virtual Geographic Environment, Nanjing Normal University, Nanjing 210023, P.R.China
2 State Key Laboratory Cultivation Base of Geographical Environment Evolution (Jiangsu Province), Nanjing 210023, P.R.China
3 Jiangsu Center for Collaborative Innovation in Geographic Information Resource Development and Application, Nanjing 210023,P.R.China
4 State Key Laboratory of Resources and Environmental Information System, Institute of Geographic Sciences and Natural Resources Research, Chinese Academy of Sciences, Beijing 100101, P.R.China
5 Department of Geography, University of Wisconsin-Madison, Madison, WI 53706, USA
Abstract In addition to soil samples, conventional soil maps, and experienced soil surveyors, text about soils (e.g., soil survey reports)is an important potential data source for extracting soil–environment relationships. Considering that the words describing soil–environment relationships are often mixed with unrelated words, the first step is to extract the needed words and organize them in a structured way. This paper applies natural language processing (NLP) techniques to automatically extract and structure information from soil survey reports regarding soil–environment relationships. The method includes two steps:(1) construction of a knowledge frame and (2) information extraction using either a rule-based method or a statistic-based method for different types of information. For uniformly written text information, the rule-based approach was used to extract information. These types of variables include slope, elevation, accumulated temperature, annual mean temperature, annual precipitation, and frost-free period. For information contained in text written in diverse styles, the statistic-based method was adopted. These types of variables include landform and parent material. The soil species of China soil survey reports were selected as the experimental dataset. Precision (P), recall (R), and F1-measure (F1) were used to evaluate the performances of the method. For the rule-based method, the P values were 1, the R values were above 92%, and the F1 values were above 96% for all the involved variables. For the method based on the conditional random fields (CRFs), the P, R and F1 values for the parent material were, respectively, 84.15, 83.13, and 83.64%; the values for landform were 88.33, 76.81, and 82.17%, respectively. To explore the impact of text types on the performance of the CRFs-based method, CRFs models were trained and validated separately by the descriptive texts of soil types and typical pro files. For parent material, the maximum F1 value for the descriptive text of soil types was 90.7%, while the maximum F1 value for the descriptive text of soil pro files was only 75%. For landform, the maximum F1 value for the descriptive text of soil types was 85.33%, which was similar to that of the descriptive text of soil pro files (i.e., 85.71%). These results suggest that NLP techniques are effective for the extraction and structuration of soil–environment relationship information from a text data source.
Keywords: soil–environment relationship, text, natural language processing, extraction, structuration
1. Introduction
The soil–environment relationship, which plays a key role in predictive soil mapping, is usually extracted from soil samples (Stumet al.2010; Beucheret al.2015; Brungardet al.2015; Henglet al.2015), conventional soil maps (Qi and Zhu 2003; Odgerset al.2012; Nauman and Thompson 2014; Heunget al.2016), and experienced soil surveyors(Cooket al.1996; Zhu 1999; Corneret al.2002; Liu and Zhu 2009). However, in some cases, all these data sources may not be available, so other potential data sources are needed. Texts about soil, such as soil survey reports, field investigation reports, and related manuscripts, are first-hand information-rich survey data and the basic information for understanding the soil-forming process (Rossiter 2008).These texts, expressed in a natural language (such as English, Chinese and French), contain a variety of descriptions such as the soil type distribution, soil-forming conditions, pro filed morphological features, and physical and chemical properties (Shiet al.2004). Therefore, these texts are worthwhile data sources for extracting soil–environment relationships.
Considering that the words describing soil–environment relationships are often mixed with unrelated words, the first step is determining how to extract the needed words and organize them in a structured way. The automatic extraction and structuration of words describing the soil–environment relationship from texts can be achieved through the information extraction techniques in natural language processing (NLP).
NLP is a discipline that integrates linguistics, computer science, and mathematics as well as studies the linguistic aspects of human-human and human-machine communication (Manaris 1998; Zong 2013). The information extraction techniques are dedicated to the detection and recognition of named entities, relations, events,and temporal expressions while ignoring other irrelevant information and are suitable to derive structured information from unstructured, free or semi-structured texts (Martin and Jurafsky 2009; Piskorski and Yangarber 2013). The specific methods of information extraction can be generally divided into rule-based methods and statistic-based methods. The rule-based methods are also known as knowledge engineering methods, which use rules written by domain experts that encode linguistic knowledge by matching patterns over various structures: text strings, partof-speech tags, and dictionaries (Appelt 1999; Rodrigues and Teixeira 2015). Rule-based methods have been widely applied to problems such as the recognition of a person’s name, local organization names, temporal expressions,entity attributes, spatial relations, and events (Shariffet al.1998; Mikheevet al.1999; Aone and Ramos-Santacruz 2000; Yuet al.2003; Shaalan and Raza 2007; Zhao and Sui 2008; Zhanget al.2009; Chang and Manning 2012;Valenzuela-Escárcegaet al.2015). This type of method has the advantage of high precision if the rules and lexicons are complete for a specific scenario, but these methods are not suitable for complex scenarios in which the rules and lexicons cannot be enumerated (Appeltet al.1993;Soderland 1999; Ciravegna 2001).
The statistic-based methods regard information extraction as classification or clustering tasks. Many methods have been proposed to address this problem, including supervised learning, semi-supervised learning, distant supervision,unsupervised learning and deep learning approaches(Piskorski and Yangarber 2013; Rodrigues and Teixeira 2015; Wuet al.2015). Compared with the rule-based method, the statistic-based method does not need to define fixed and complete rules and lexicons. Instead, it uses a corpus to train the classi fiers, which are then used to extract information from unseen text (Jurafsky and Martin 2014).If there are new patterns that can be used for extracting information, updating the corpus and retraining the statistical model is all that is needed (Zong 2013). Therefore, this method is more flexible and suitable for complex scenarios,but it is both time- and labor-intensive to build a high-quality corpus (Wanget al.2014; Zitouni 2014).
Both types of information extraction methods have their advantages and disadvantages. To extract different types of soil–environment relationship information from text, a hybrid approach was used. Section 2 presents how to extract and structure different types of soil–environment information from text. Section 3 discusses the application of the method to the Chinese soil survey reports. Conclusions are given in Section 4.
2. Methodology
Before extracting information from the text, a knowledge framework was proposed to define the information needed to characterize the soil–environment relationship. This information included soil type/properties and environmental variables that characterized soil-forming conditions, which was organized in the form of “name of soil/environment variable: value” (e.g., soil type: Lateritic red earths, slope:10–30 degree). NLP techniques were used to extract the information and fill in the knowledge framework.For information contained in uniformly written text (e.g.,“3 000 m”, “25°”, and “50°C” can be expressed in the“number+quanti fier” form), the rule-based approach was used for information extraction. These types of variables included slope, elevation, accumulated temperature, annual mean temperature, annual precipitation, and frost-free period. For information contained in text written in diverse styles (e.g., “alluvial deposit”, “granite porphyry”, and“diabase” cannot be expressed in uniform form), the statisticbased method was adopted. These types of variables included landform and parent material. The overall process of the NLP-based approach is shown in Fig. 1.
2.1. Construction of the knowledge framework
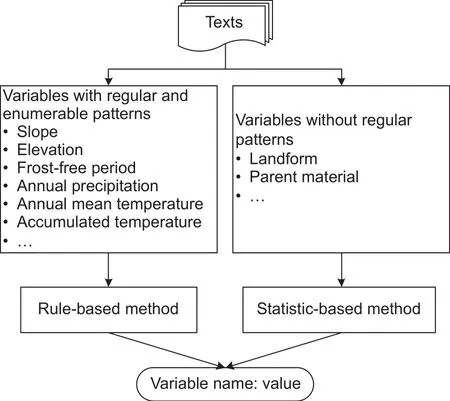
Fig. 1 Overview of soil–environment relationship information extraction.
The formation and spatial distribution of soil is affected by several environmental factors, such as climate, topography,parent material, organisms, age and space (Jenny 1941;McBratneyet al.2003). For example, red soil is mainly distributed in the hilly area south of the Yangtze River,which has an annual average temperature of 16 to 18°C.The annual precipitation is 800 to 2 000 mm, the natural vegetation is the evergreen defoliate broad-leaved mixed forest and evergreen broad-leaved forest, and most of the soil parent materials are Quaternary laterite and granite. In predictive soil mapping, these soil–environment relationships can be expressed implicitly using models such as the support vector machine and artificial neural networks,or they can be expressed explicitly using models such as the decision tree, rules and frame. With regard to the text data sources, the extracted soil–environment relationships are suitable for the explicit models.
In this paper, a knowledge frame was designed to organize the soil–environment relationship information extracted from the text data source. The frame is a typical knowledge presentation method that conforms to human cognitive habits and could simplify reading and cognitive dif ficulties (Minsky 1975). Fig. 2-A shows the structure of the proposed knowledge frame. Each soil type corresponds to a frame, which consists of two themes:the soil-type theme and the soil-sample theme. Both themes consist of several environmental variables or soil properties. Each environmental variable or soil property has a name representing the semantic of the variable and its corresponding value. The variables and soil properties in the framework can be customized for specific scenarios.Fig. 2-B shows an example of the extraction results presented in the frame.
2.2. Information extraction using the rule-based method
The rule-based method is suitable for information extraction from a text with regular and finite patterns. The text in Chinese soil survey reports belonging to this method has the following characteristics: 1) the variable name and value are in the same clause; 2) there is a limited set of synonyms that can be enumerated for one semantic meaning; and 3)the units of measurement are often given after the quanti fier within variable value. For example, in the clause “The elevation is 3 300 m”, the variable name is “elevation”, and the value is “3 300 m”. “Elevation” is usually expressed as“elevation”, “absolute elevation” and “altitude”. The value of the elevation, when combined with the variable name in the same clause, is “3 300 m”.
Before information extraction, each text block was split into clauses by punctuation marks (e.g., coma or period),which is called sentence segmentation in NLP. A Chinese clause is a string of words not separated by spaces like other language such as English or French, so the clause string should be separated as words. This process is called word segmentation.
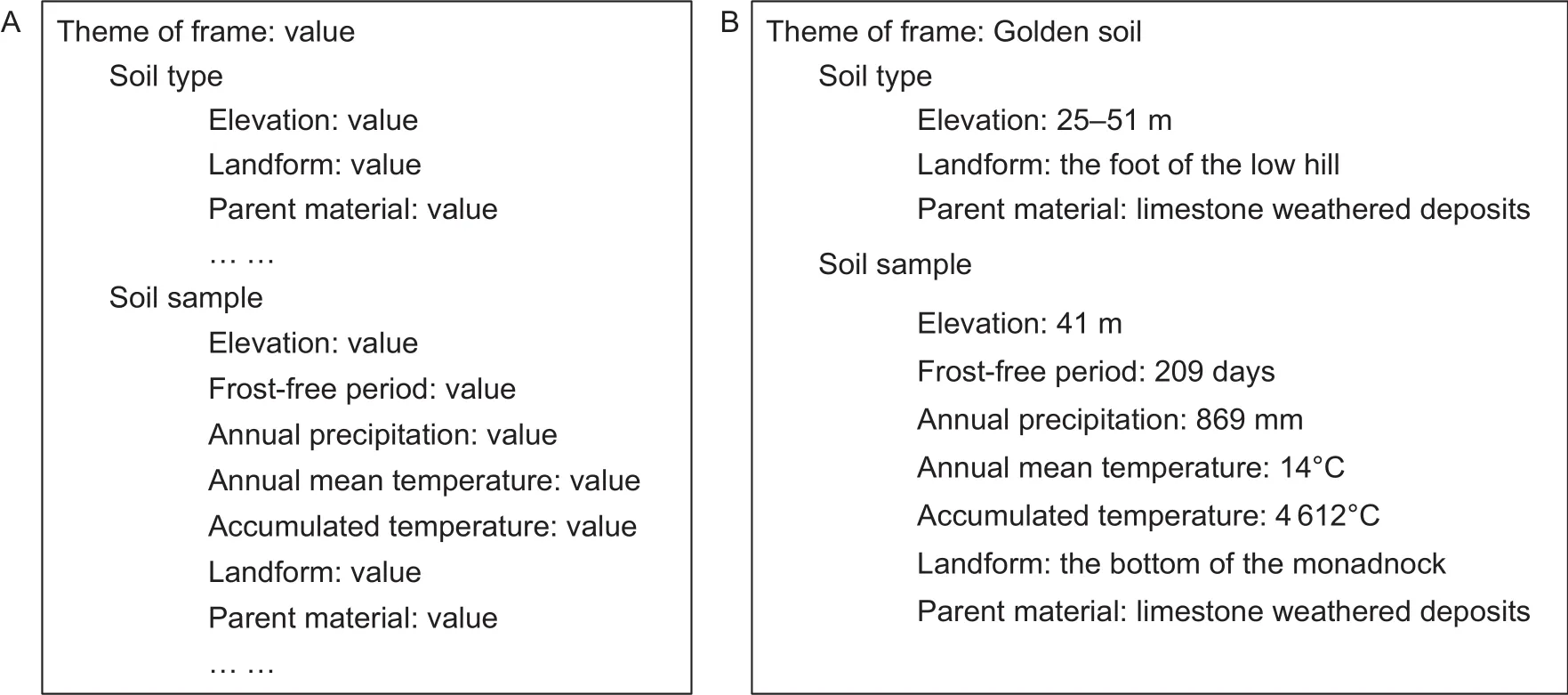
Fig. 2 Knowledge frames. A, the structure of soil-environment relationship information. B, an example of the extraction results.
Two steps were used to extract the information for each variable listed in the knowledge frame (e.g., elevation): 1)the selection of the clause containing the target variable information and 2) the extraction of the variable’s value from the clause. The detailed process is shown in Fig. 3.Selection of the clause containing the target variable informationFor a given target variable, the clauses containing any synonym according to its semantic meaning should be selected. A semantic dictionary containing the synonym set for each variable was established in advance.During the selection process, a two-level loop, one level iterated through each clause and the other level iterated through each synonym for a given variable, was used to find clauses containing target variable information.
Extraction of the target variable value from the clauseA typical extraction pattern for the target variable value is “variable name+unrelated words+{pre fix+number or(number+quanti fier)+punctuation+(number+quanti fier)+suf fix}”. The parentheses represent the combination of several elements and the section in the brace represents the variable value. For example, if the input clause was “海拔25–51 m” (The elevation is 25–51 m), the matching results would be “海拔 (elevation) [variable name]+{25[number]+“–” [punctuation]+“51 m” [number+quanti fier]}”,and the extracted variable value would be “25–51 m”. The contents in the square bracket represent the matching parts in the rule. If the input clause was “坡度多在20°以上” (Most of the slope is over 20 degree), the matching results would be “坡度 (slope) [variable name]+多 (most of)[unrelated words]+在 (is) [unrelated words]+20° (20 degree)[number+quanti fier]+以上 (over) [suf fix]”, and the extracted variable value would be “20°以上” (over 20 degree).

Fig. 3 The process of the rule-based method.
The above process was accomplished mainly through Chinese word segmentation (e.g., “20°以上” (over 20 degree) is segmented to “20, °, 以上 (over)”), part-of-speech tagging (e.g., “20 [number], °[quanti fier]”), pre fix and suf fix matching (e.g., “以上 (over) [suf fix]”) and rule matching(e.g., “20[number]+°[quanti fier]+以上 (over) [suf fix]” matches with the rule: “number+quanti fier+suf fix”). Chinese word segmentation and part-of-speech tagging can be carried out with free software tools such as NLTK (http://www.nltk.org), Stanford NLP (http://stanfordnlp.github.io/CoreNLP),and LTP (http://github.com/HIT-SCIR/ltp). Pre fix and suf fix matching need a dictionary of pre fixes and suf fixes. The establishment of a pre fix and suf fix dictionary is as follows: 1)Manually summarize the pre fix and suf fix words that appear in the variable values in terms of semantics and 2) expand them using the synonym dictionary. Then, combine the adjacent tags, including the pre fix, number, punctuation, quanti fier and suf fix, into a sequence (e.g., “20 [number], ° [quanti fier], 以上(over) [suf fix]” is combined into “number+quanti fier+suf fix”)and extract the potential variable value by matching the sequence with rules in a rule base. To get diverse types of variable values, a rule base needs to be established. The rule base can be generalized manually according to variable value instances. Examples of the rules are shown in Table 1.Several rules may be matched in the base; therefore, among the potential variable values, the best variable value remains to be picked out. The maximum matching method was used to start the match from the left side and select the longest match in a match set. Ultimately, the longest one was taken as the most suitable soil variable value.
2.3. Information extraction using the statistic-based method
In soil survey reports, there may also be text without regular and finite patterns, For example, in clauses describing parent material (e.g., “分布在廣東省湛江市和惠陽縣等古淺海沉積物位置較高的地段” (Distributed in the higher places of ancient shallow marine sediments in Zhanjiang and Huiyang, Guangdong Province), there may not be explicit words for the variable name, and the variable values cannot be enumerated. In these cases, statistic-based methods were used for information extraction. The key element of the statistic-based method is an annotated corpus (text set), which is used for model training and validation. More information about natural language annotation is provided in Pustejovsky and Stubbs (2012). Since the annotation of a corpus is laborious and costly (Jurafsky and Martin 2000),this method was used only when rules and lexicons could not be enumerated.
One popular statistical method for information extraction from text is the conditional random fields (CRFs) model.This model uses the undirected graphs and conditional probability model for annotating and segmenting ordered data (Laffertyet al.2001). An important feature of CRFs is that it does not assume the independence of data (Sutton and McCallum 2012) and allows the data elements in the sequence to have long-distance tolerance.
In this paper, the CRF++ (http://taku910.github.io/crfpp) open source software was used to construct the CRFs model. As shown in Fig. 4, the CRFs model is a supervised learning method, so it needs training before application. The commonly used training inputs for CRF++include training files and feature templates. An example of a training file is shown in Table 2: the first three columns are word, part-of-speech and K value. “Word” is the result of word segmentation and the carrier of other information,and part-of-speech is the basic grammatical attributes of words (Birdet al.2009). Both word and part-of-speech re flect the characteristics of linguistics. The K value is Boolean and stands for whether the current word is in the keyword dictionary, so it embodies the semantic information.The fourth column contains the tags represented in BIO format, which indicates the variable the word belongs to.For example, PM denotes parent material, and the tags B,I, E, and O denote the beginning, inside, ending and out of a variable value entity. B-PM means the current word is the beginning of the parent material value.
The variable tag for each word was obtained in two steps.First, an annotated corpus was constructed manually. For each clause, the variable value was tagged with a variable name. For example, in the clause “分布在廣東省湛江市和惠陽縣等古淺海沉積物位置較高的地段” (Distributed in the higher places of ancient shallow marine sediments in Zhanjiang and Huiyang, Guangdong Province), “古淺海沉積物” (ancient shallow marine sediments) was picked out and annotated with “PM (parent material)”. However, the annotated words may be separated into several words after word segmentation. For example, “古淺海沉積物” (ancient shallow marine sediments) was separated into “古” (ancient),“淺海” (shallow marine), and “沉積物” (sediments). In thesecond step, these separated words were automatically annotated according to the position of the separated word in the whole word. For example, as the whole word belongs to“PM” and the separated word “古” (ancient) is located in the beginning of the whole word, this word is annotated as “BPM”, which means the beginning of the parent material value.

Table 1 Examples of the rules for extracting soil variables1)
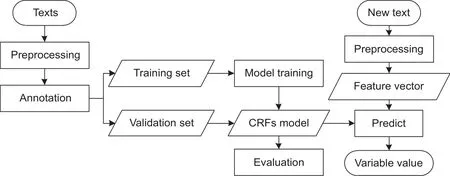
Fig. 4 The process of the conditional random fields (CRFs)-based method.
An example of a feature template with context window(n) is shown in Table 3. Context features re flect the concurrence of characteristics of words, the window size of which depends on the specific information extraction task.In general, a window size of two to three is commonly used for Chinese named entity recognition (Wuet al.2017).
These input data were then used to train the CRFs model. The final tag column is used as the dependent variable and the first three columns (word, part-of-speech and K value) could be used as independent variables. In this paper, different combinations of independent variables were tested (i.e., the word alone, the word plus its part-ofspeech, and all three variables). The annotated records were divided into two parts, one part for training and the other part for validation. Then, the trained model could be used to extract the values for a given variable from the text of soil survey reports. Examples (translated from Chinese) of the output of the CRFs model are as follows:for parent material, the output of “The parent material of this soil species is mainly limestone weathered deposits”is “The/O parent/O material/O of/O this/O soil/O species/O is/O mainly/O limestone/B-PM weathered/I-PM deposits/EPM”. For landforms, the output of “Distributed at the bottom of a low hill in Xuzhou, Jiangsu Province” is “Distributed/O at/O the/B-Landform bottom/I-Landform of/I-Landform a/ILandform low/I-Landform hill/E-Landform in/O Xuzhou/O,/O Jiangsu/O Province/O”.
2.4. Experimental design
The raw experimental dataset was derived from the soil species (series) of China soil survey reports (OSNSSC 1993,1994a, b, 1995a, b, 1996). These texts were organized by soil species and included the descriptions of soil types and typical pro files. The texts of 200 soil species were used in the experiment and there were 3 972 sentences after sentence segmentation. To build the dictionary for assisting Chinese word segmentation, the soil science word set was built based on the Chinese National Standards for soil taxonomy (GB/T 17296-2009 2009) and China Soil Database (http://vdb3.soil.csdb.cn); the geological word set was build based on Sogou dictionaries (http://pinyin.sogou.com/dict). After sentence segmentation, the variable information in each clause was annotated manually. For each variable, the annotated clauses were divided into two types based on whether they contained variable information;80% of the clauses in each type were used to generalize the information extraction rules or train the statistical model,while 20% of the clauses were used for validation. The information regarding elevation, accumulated temperature,annual precipitation, annual mean temperature, and frostfree period was extracted by using the rule-based method,while the parent material and landform information was extracted based on the CRFs model. For the rule-based method, the dictionaries of variable semantics, pre fixes and suf fixes were built based on the HIT-CIR Tongyici Cilin(Extended) (http://www.ltp-cloud.com). For the statisticbased method, the keyword dictionary of parent material and landform values was summarized manually. The features selected for the CRFs model included word, part-of-speech,K value, and their context features. In this study, window sizes from one to four were tested.

Table 3 Example of the feature template with context window n
The performance of soil–environmental information extraction can be evaluated using three measures: precision(P), recall (R), and F-measure (F).
P is a fraction and indicates how many times the retrieved results are true. P is expressed as eq. (1):

Where, C is the number of correct results of extraction.The correctness of the extraction results was checked by comparing them with the manually annotated results, which were compiled through referencing literatures and consulting experts. IC is the number of incorrect results of extraction.
R indicates how many times the true environmental variable values were extracted among all the annotated values. R is expressed as eq. (2):

Where, NA means the number of all expected results of extraction.
F is expressed as eq. (3), which is the harmonic mean of precision and recall. In general, F was used to evaluate the validity of the recognition approach and can be simpli fied into the F1-measure (F1) value expressed as eq. (4), where,α=1.

3. Results and discussion
3.1. Validation of the rule-based method
The validation results of the rule-based method are presented in Table 4. The F1 values of all variables were over 95%, and the F1 values of the annual mean temperature and the annual precipitation were one. All the precisions equaled one, and the recall rates were all larger than 90%, which indicated that the expression of these variables and their values are in uniform styles.
The rule-based method was also applied to a larger validation dataset containing the text of 2 473 soil species from the soil species of China soil survey reports to further evaluate the performance of this method. The rules were generalized from the texts of 200 soil species mentioned in Section 2.4. As shown in Table 5, the F1 values of all variables were over 97%. All the precisions were one and the recall rates were over 95%. These results indicated that the rule-based method had a high rate of accuracy in specific scenarios.
3.2. Validation of the CRFs-based method
Tables 6 and 7 list the validation results of the CRFsbased method. The results showed the following: 1) The maximum F1 values for the parent material and landform variables were 83.64 and 82.17%, respectively, while theminimum F1 values were 79.27 and 72.18%, respectively.2) The most suitable context window sizes (n) for both the parent material and landform variables were one and two,respectively. 3) The most useful features corresponding to the two variables were both the combination of word (Wn)and part-of-speech (Pn).

Table 4 The performance of soil–environment variable extraction using the rule-based method

Table 5 The performance of the rule-based method in specific scenarios

Table 6 The performance of parent material value extraction using the conditional random fields based method (%)1)

Table 7 The performance of landform value extraction using the conditional random fields based method (%)1)
To explore the impact of text types on the performance of the CRFs-based method, CRFs models of parent material were trained and validated separately by the descriptive texts of soil types and typical pro files. The validation results are shown in Tables 8 and 9. The maximum F1 value for the descriptive text of soil types was 90.7%, while the maximum F1 value for the descriptive text of soil pro files was only 75%.For the descriptive text of soil types, the optimal context window size was three and the optimal features were the combination of Wn, Pnand key value (Kn). For the descriptive text of soil pro files, the optimal context window size was two and the optimal features were the combination of Wnand Pn. These results indicated that text type had a significant impact on the performance of the CRFs model for the parent material variable. The descriptive texts of different soil types usually have similar styles and vocabularies to describe the parent material information, which are relatively easy for the CRFs to model. In contrast, the descriptive text of different soil pro files is often written using more diverse styles and vocabularies, so they are harder to be modeled.
CRFs models of landform were also trained and validated separately by the descriptive texts of soil types and typical pro files; the results are shown in Tables 10 and 11. The maximum F1 value for the descriptive text of soil types was 85.33%, which was similar to that for the descriptive text of soil pro files. The optimal features for the two models wereWn, Pnand Kn. For the descriptive text of soil types, the optimal context window size is three; the optimal context window size for the descriptive text of soil pro files is two.Overall, the CRFs models trained by the descriptive text of soil types and typical pro files had similar performances for the landform variables, which can be attributed to the fact that similar styles and vocabularies were used for the landform descriptions of different soil types and pro files.

Table 8 The performance of parent material value extraction for the descriptive text of soil types with the conditional random fields model (%)1)

Table 9 The performance of parent material value extraction for the descriptive text of soil pro files with the conditional random fields model (%)1)
3.3. Future work
The performance of the rule-based method mainly depends on the quality and completeness of the dictionaries and the rules. The dictionaries are used to assist with word segmentation, variable recognition, and recall rates determination. The rules determine the accuracy of the extracted variable value. Because both the dictionaries and the rules are closely related in specific application domains and tasks, they need to be changed enormously when applied to new domains or different tasks. The process of building dictionaries and rules automatically or semiautomatically should be studied further. In addition,the rule-based method is also in fluenced by sentence segmentation, which determines the length of the clause.If a clause is too short, the variable names and values may not be in the same clause, which will affect the result of the extraction. Therefore, how to determine the granularity of sentence segmentation is also an important issue that needs to be explored.
For the CRFs method, the corpus and the features are the main factors affecting the performance. A large corpus ensures that the model has enough training sets,and suf ficient types of expression styles to ensure that the model can apply to different situations. Because building the corpus is time- and labor-intensive, future work should emphasize how to build a corpus automatically or semiautomatically to ensure that both size and diverse styles are encompassed. Word, part-of-speech, K value and their context features were used as input features in this study,but there are more features such as syntax, dependency relationship and domain knowledge that may improve the model’s performance. Therefore, more features and feature combinations should be explored in future work.
In addition, only soil survey reports at the national level were used in this study. The reports at finer levels (e.g.,the county level) written with more diverse styles and vocabularies have not been tested, which will be studied in the future.
4. Conclusion
Texts such as soil survey reports, field investigation reports,and related manuscripts contain a wealth of information on soil–environment relationships. The first step toward extracting soil–environment relationship information from these texts is to extract the needed information and organize it in a structured way. This paper applied the natural language processing technique to automatically extract and structurize information regarding the soil–environment relationship from soil survey reports.
NLP-based soil–environment relationship information extraction includes two steps: (1) construction of the knowledge frame and (2) information extraction using both a rule-based method and a statistic-based method.For information contained in the text with regular and enumerable patterns, the rule-based approach was used.For information contained in the text without obvious regular patterns, the statistic-based (CRFs-based) method was used. The experiments were conducted using the soil species of China soil survey reports. The results showed that these methods can successfully extract soil–environment variable names and values. This study demonstrated that the NLP technique is effective for the extraction and structuration of soil–environment relationship information from a text data source.

Table 10 The performance of landform value extraction for the descriptive text of soil types with the conditional random fields model (%)1)

Table 11 The performance of landform value extraction for the descriptive text of soil pro files with the conditional random fields model (%)1)
Acknowledgements
This study is supported by the National Natural Science Foundation of China (41431177 and 41601413), the National Basic Research Program of China (2015CB954102),the Natural Science Research Program of Jiangsu Province, China (BK20150975 and 14KJA170001), and the Outstanding Innovation Team in Colleges and Universities in Jiangsu Province, China. Supports to A-Xing Zhu through the Vilas Associate Award, the Hammel Faculty Fellow Award, the Manasse Chair Professorship from the University of Wisconsin-Madison are also greatly appreciated.
猜你喜歡
海洋信息技術與應用(2022年2期)2022-08-29 04:03:54
小天使·三年級語數英綜合(2020年4期)2020-12-23 04:48:40
城市道橋與防洪(2019年5期)2019-06-26 00:56:04
湛江文學(2018年3期)2018-03-20 00:59:48
湛江文學(2018年3期)2018-03-20 00:59:48
湛江文學(2017年11期)2017-11-30 08:31:09
電氣化鐵道(2016年4期)2016-04-16 05:59:46
廣東海洋大學學報(2015年3期)2015-12-22 10:05:28
湛江文學(2015年2期)2015-12-18 14:05:02
河北遙感(2015年2期)2015-07-18 11:11:14
 Journal of Integrative Agriculture2019年2期
Journal of Integrative Agriculture2019年2期
- Journal of Integrative Agriculture的其它文章
- Digital mapping in agriculture and environment
- Maize production under risk: The simultaneous adoption of off-farm income diversification and agricultural credit to manage risk
- miR-34c inhibits proliferation and enhances apoptosis in immature porcine Sertoli cells by targeting the SMAD7 gene
- lnhibition of KU70 and KU80 by CRlSPR interference, not NgAgo interference, increases the ef ficiency of homologous recombination in pig fetal fibroblasts
- Protective roles of trehalose in Pleurotus pulmonarius during heat stress response
- Kiwifruit (Actinidia chinensis) R1R2R3-MYB transcription factor AcMYB3R enhances drought and salinity tolerance in Arabidopsis thaliana