
A lightweight RFID tags anti-collision scheme based on searching tree
2018-12-27 03:19:48SHANGHong
重慶郵電大學(xué)學(xué)報(自然科學(xué)版) 2018年6期
SHANG Hong
(Jiangsu Key Laboratory of Internet of Things, Taihu University of Wuxi, Wuxi 214064, P. R. China)
Abstract: The existing RFID (radio frequency identification) searching tree anti-collision schemes incur large amounts of redundancy data due to an excess of long query commands, which increases the communication overhead. The paper proposed a lightweight anti-collision scheme based on searching tree. At first, the scheme designed a novel query response mode (i.e., single query with duo responses), which can make the collided tags respond to the next query in two subsequent slots respectively according to their most significant collided bit, and reduce the total number of queries by half. The scheme replaced the prefix matching circuit in tag with a counter, which can eliminate the prefix as the reference parameter of query command. Besides, the scheme put forward a predictive identification method to decrease the total number of the required slots. Finally, the scheme also proposed a locking technique to avoid the identified tags colliding with the unidentified tags, which can improve the identification efficiency of tags. The experimental results show that the communication overhead is decreased overall 42% by using single query with duo responses mode and counter trigger, and that the throughput is improving with the number of tags by using predictive identification.
Keywords:radio frequency identification (RFID); anti-collision; searching tree; lightweight
1 Introduction
Radio frequency identification (RFID) is an automatic identification system which consists of readers and tags. A tag has an identification number (ID) and a reader recognizes an object through consecutive communications with the tag attached to it[1]. The reader sends out a signal which supplies power and instructions to a tag, the tags transmit their ID using back scattering in response to the query from the reader. Since tags are self-contained entities that don’t know about other tags, they always send information to the reader on their own schedule. For a reader only has one channel for communication, having two or more tags simultaneously transmitting to the reader in the air interface leads to tag collision, the reader can’t identify the tags due to tag collision. To read information properly from these tags, the reader must adopt an anti-collision scheme. Taking system cost, protocol complexity, bandwidth requirements, hardware requirements for tag, and overall performance into consideration, time division multiple access (TDMA) protocols are the most popular methods to deal with the tags collision[2]. According to the coordinating policy for the shared RF wireless channel, they can be further classified into Aloha and tree based schemes. Aloha-based ones have fairly low cost and complexity in system implementation, but their throughput are low (less than 36.8%), and usually suffer from the tag starvation problem (i.e., some specific tags possibly can’t be identified due to always colliding with others)[3]. In contrast, tree-based schemes not only have high throughput, but don’t suffer from the tag starvation problem. In fact, tree-based ones can single out and read every tag by iteratively grouping the collided tags. According to grouping policy, tree-based schemes can be categorized into the following categories[4], i.e., query tree, splitting tree, searching tree and bitwise arbitration tree. Among the tree-based schemes, the searching tree scheme outperforms others because it uses Manchester coding[5]. The reader can find collided bits in the received tag ID by Manchester decoding. Once collision occurs, the reader will divide the collided tags into two subsets. Hence, there always exist some tags responding the query from the reader, which reduces the delay caused by idle slot, and improves the throughput (more than 50%)[6]. Therefore, our proposed RFID tags anti-collision scheme will still focus on the searching tree scheme.
2 Related works
In this section, we survey the relatedprevious works for the proposed scheme, which include three schemes based on binary search.
In binary searching-based schemes, it requires the reader to knowthe position of collided bits, which can be resolved by Manchester coding. As known, Manchester coding represents each data bit by the level transition of signal wave within each bit period. So, there exists no data bit which signal level doesn’t change. If such data bit is tracked, it would be identified as a collided bit. Therefore, the reader can obtain the position and the number of collided bits.
Binarysearching tree scheme (BST)[5]is the original binary searching-based scheme. The reader sends query command with reference ID. The initial reference ID is the maximum possible tag ID value (e.g., 11111111). Those tags with ID equal to or lower than the reference ID shall respond with their ID. If only one tag responds, the tag could be identified. Otherwise, some collisions occur, and none of tag could be identified. In this case, the reader can find the most significant collided bit (denoted asχ) in the received ID by Manchester decoding, and then send a new query command by replacing the |χ| bit of reference ID with ‘0’ (|χ| is the position ofχ). The above process is iterated, until only one tag responds. If the reader identifies a tag, it would send a quiet command, which require the tag to enter the sleep state and no longer respond to the query command from the reader.
BST scheme can deal with the tag collision, but it suffers from high communication overhead. BST usually selects the whole tag ID as the reference ID of the query command, and always require tag to respond the query with its whole ID. In order to reduce the communication overhead rooting from a long reference ID, conference[7]proposed dynamic binary searching tree (DBST) scheme which adopts variable-length ID as its reference ID. In the scheme, the reference ID is a prefix, which is a part of the received tag ID preceding theχfollowed by a data bit ‘0’. If the part of tag ID is equal to the prefix (i.e., tag ID match the prefix), the tag should respond with the remaining bits of the tag ID, which can reconstruct as a complete tag ID combined with the prefix by the reader. Otherwise, the tag shall enter a wait state to wait for the later query from reader. If collision occurs when more than one tag has the same prefix, the above process will repeat many times until only one tag responds.
After a tag is identified successfully, DBST scheme will enter a new query iteration procedure after the reader sends a query command with initial reference ID (i.e., returns to the root), which doesn’t use the history information of the query process and results in low throughput. To improve the throughput, conference[8]proposed dynamic binary searching tree scheme based on regressive strategy (RDBST), which set up a stack in the reader, and pushes the prefix into the stack in every collision slot. After a tag is identified, the latest prefix shall be popped out to replace the initial reference ID as the reference ID of the next query command. This regressive strategy reduces repeating steps by the stack recording the whole query steps orderly. The total number of slots is reduced from lb(n!)+nto 2n-1 (nis the number of tags).
RDBST scheme greatly reduce the total number of slots by the regressive strategy, thus its throughput is much higher than that of Aloha-based scheme. Furthermore by using variable-length ID, RDBST efficiently reduces the total number of transmitted bits, and improve the transmission efficiency of valid message. Hence, RDBST has much lower communication overhead. However, compared with the Aloha-based schemes, its communication overhead is still high because there are lots of redundant data in each turn of tag identification. Therefore, this paper aims to reduce the redundant data generated in the process of identification. As the above anti-collision schemes shown, the reader groups the collided tags into two subsets and then queries them respectively. Furthermore, the identified prefix is used as the reference ID of query command, which not only increases the communication overhead, but requires all the tag to do the prefix matching after receiving query command. However, using a new responses mode (i.e., Single query with duo responses mode) in our proposed scheme, the collided tags will respond the next query in two subsequent slots according to the |χ| bit in their ID, respectively. Meanwhile, the proposed scheme also eliminates the prefix matching related to query command through a new trigger method (i.e., Counter trigger).
3 A lightweight RFID tags anti-collision scheme based on searching tree
As the survey in Section 2 highlights, there is still a high communication overhead associated with these existing anti-collision schemes. So this paper focused on how to reduce the communication overhead and improve the throughput, and proposed a lightweight anti-collision scheme based on RDBST.
3.1 Methods for how to reduce the communication overhead
1) Single query with duo responses mode: to decrease the number of queries
In the existing searching tree schemes[7-11],the reader first finds theχin the received ID if collision occurs, and then re-sends a query command with a new prefix. Here, the new prefix in the query consists of a part of the received ID before theχand a data bit ‘0’. If the corresponding part of collided tags’ ID matches the prefix (i.e., their |χ| bit is ‘0’), they will respond the query. Due to mismatching the new prefix, the remaining collided tags’ID (i.e., their |χ| bit is ‘1’) must wait for a new query command to give responses. In other words, the collided tags are divided into two subsets by the new prefix, which depends on the |χ| bit in essence. However, there is only one subset able to respond to a query with this prefix. Hence, the query-response mode is called single query with single response. Obviously, the mode in the existing schemes does not make full use of the independent feature of the two tag subsets in terms of ID bit pattern.
To improve the tag identification efficiency of each query command, and further decrease the total number of queries, it require to design a new query-response mode, which is expected that the collided tags can give more than one independent responses for a query.For the purposes, the paper re-defines the part of the received ID preceding theχas the prefix within query commands. The re-definition can make the corresponding part of all collided tags’ ID able to match the prefix, and also make all of collided tags able to give respond once receiving a query. Besides, the paper also re-designs the responding strategy and operation for the collided tags as follows. If the |χ| bit in collided tags’ ID is ‘0’, then the tags are required to immediately respond in the current slot. Otherwise, they are required to be delayed a slot and respond in the next slot. The query-response mode is called single query with duo responses mode, which is illustrated by Fig.1.

Fig.1 An example of single query with duo responses mode
If tag collision occurs in slot 0, the prefix is pushed into stack; otherwise, the reader sends a quiet command and then the identified tag enters the sleep state. If tag collision occurs in slot 1, the collided tags in the slot are queried again; otherwise, the latest prefix shall be popped out and used as the parameter of next query command (i.e., regressive query).
The little hare took it and cried, Now it is my turn to pierce them, and as he spoke he passed the rod back through the reeds and gave Big Lion s tail a sharp poke15
2) Counter trigger: to reduce the total length of query command
As known from the above subsection, the tag can respondonly if its ID matches the prefix of query command. Therefore, the prefix matching plays the key role in deciding whether the tag responds the query command. However, as the reference parameter in query command, the prefix usually takes more bits of query command, which increases the communication overhead in tag identification. By using variable-length ID, the prefix takes up partial tag ID, but it’s not enough short yet.
In order to reduce the total length of query command,it is very necessary to shorten the identification parameter in query command. Based on the requirement, the value of |χ| directly replaces the prefix as the identification parameter of query command, and the prefix is re-assigned a new function, i.e., a recorder of collided tag. Besides, a counter is set up in tag to trace the depth of the recorder, and is used as a trigger to respond the next new query command. Its initial value is zero. If tag collision occurs, only the collided tags which counter value is zero can respond the new queries. The other tags which counter value is non-zero must wait for a regressive query command (i.e., de-query) until their counter decrease to zero, and then start a new round of query.
The identification process with counter trigger is illustrated as shown in Fig.2. Here, the example will present the process from the following key aspects, i.e., when/how to push/pop the ID information of collided tags (i.e., the prefix and the value of |χ|), how to trace the collision event by the counter in the collided tag, and the counter how to trigger the response operations of the collided tag. There are 5 tags with tag ID of 8-bit length in this example.
Step1The reader starts the identification process by sending an initial command. All tags initialize their counter (i.e.,C1~C5←0) and then respond. The reader finds the most significant collided bit |χ|=3 in received ID by Manchester decoding.
Step2The reader sends a query command, i.e., query(3). The tags with a counter value of zero check the 3thbit in their ID. It is ‘0’ in tag1~3, so they respond in slot0. It is ‘1’ in tag4 and tag5, so they respond in slot1. Tag1~3 collide in slot0, the reader pushes the prefix and the |χ| (i.e., 10110, 2) into the stack, and tag1~3 increase their counters by one (i.e.,C1~C3←+1), respectively. Tag4~5 collide in slot1, the reader finds the |χ| (i.e., 0) in received ID.

Fig.2 An illustration of the identification process with counter trigger
Step3The reader sends a query command, i.e., query(0). Because the value of counters in tag1~3 is 1, so tag1~3 don’t respond. In contrast, Tag4~5 respond in slot0 and slot1, respectively. And so they can be identified and then enter sleep state.
Step4Because no collision occurs in step 3, the reader pops the latest prefix and the |χ| (i.e., 10110, 2), and then sends a regressive command, i.e., de-query(2). Once received the de-query command, the tags (i.e., tag1~3) are required to decrease their counters by one, and so the counter value of tag1~3 is 0. Tag1~3 respond in slot0 and slot1, respectively. Tag1 is identified in slot0. Tag2~3 collide in slot1, the reader finds the |χ| (i.e., 1) in received ID.
As shown,the tags can respond only if its counter value is zero. If prefix is pushed into the stack, the counter shall increase by one; if prefix is popped, the counter shall decrease by one.
3.2 The methods for how to improve the throughput
1) Predictive identification: to decrease the total number of slots
In [12], tag ID and its XORed value (i.e., parity-check bit) are reconstructed a new tag ID. Because the parity-check bit is the most significant bit of the new ID, it is always identified firstly. Once it is identified, all the responding tags will have even (or odd) number of ‘1’ in their ID. But there isn’t the case of one collided bit in the received ID. Only in the case of two collided bits, the reader can identify two tags by its parity-check bit. This scheme increases the complexity of scheme. In this paper, we adopted an easy predictive identification method as follows. If there is only one collided bit in received ID, the reader could directly identify the two tags. Because the collided bit must be caused by two tags, the bit is either ‘0’ or ‘1’. For example, if the received ID is 101011X0 (X is the collided bit), the ID of two tags must be 10101100 and 10101110. The predictive identification could also save two slots.
2) Locking technique: to avoid the identified tags colliding with the unidentified tags
In some cases, the reader repeatedly identifies the same tags since these tags always stay in itscommunication range. If the overlapping area has tags, the identified tags still respond and collide with the unidentified tags. In order to prohibit the identified tags from colliding with the unidentified tags, the paper proposed a locking technique working as follows. Each tag reserves a memory area to store the ID of the reader (i.e., RID) when starting the identification, and clear the RID after leaving reader’s communication range. When starting tag identification, the reader sends an initial command with RID to the tags nearby. Then the tags interpret themselves as the identified tags if the tags have a matching RID. These identified tags are locked, and enter the sleep state and don’t respond. They can get out of the sleep state after leaving reader’s communication range. If the storage area is empty, the tags regard themselves as the unidentified tags, and then store the received RID, meanwhile responding with their IDs to the query of reader.
4 Performance evaluation and analysis
The simulation of MATLAB situation is as follows. There is only one reader, and the number of tags in the field of the reader increases from 100 to 1 600. The length of the tag IDs is 16 bits. We consider two scenarios according to the distribution pattern of tag IDs, i.e., Random assignment and sequential assignment. The following metrics[13]are considered in evaluating the efficiency of tag identification, i.e., the total number of queries, the length of query command, the throughput and the communication overhead. From these aspects, we comparatively evaluate the performance of RDBST scheme[8], FST scheme[12]and our proposed scheme LWST. For simplicity, we use the bit-sequence of the reference parameter in the query commands and the transmitted ID bits as the communication overhead without considering the control parameters (e.g., suffixes and check redundancy). The ratio of the total number of slots to the total number of the identified tags is defined as the throughput (u).
As shown in Fig.3 and Fig.4, compared with FST scheme, the total number of queries is decreased by half in LWST no matter the allocation of tag IDs. The results show that Single query with duo responses mode decreases the total number of queries by half.

Fig.3 Number of queries (random ID)
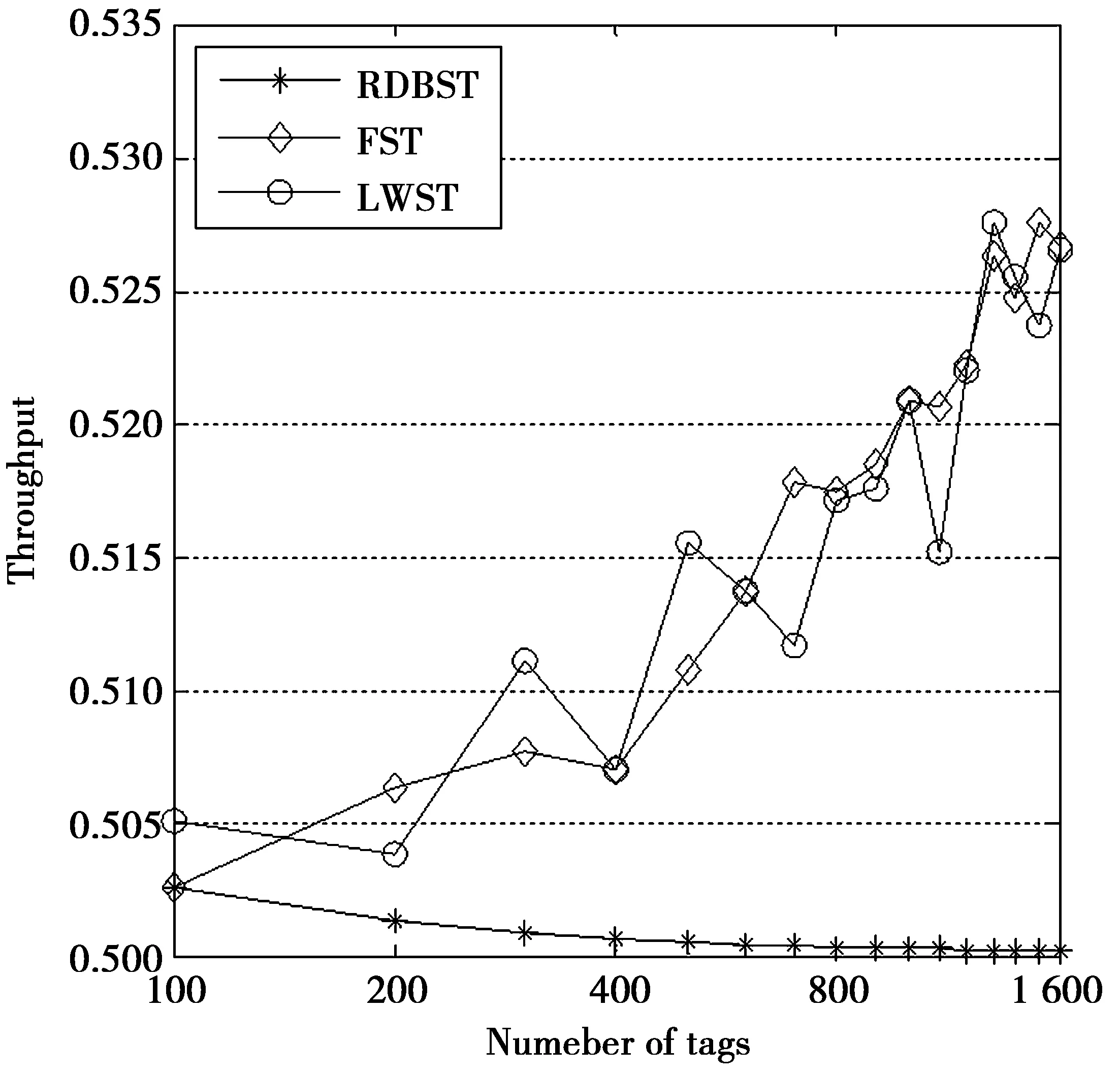
Fig.4 Number of queries (sequential ID)
Fig.5 shows the performance comparison where the prefix andthe |χ| are used as the reference parameter of query command, respectively. The LWST uses the counter as the trigger in response to query, which makes the reference parameter of query command need only the |χ|. The expression of the |χ| needs only lbkbits (kis the length of ID). If the length of ID is doubled, the parameter of query command only needs to increase one bit. However, other schemes use the prefix matching circuit as the trigger, which requires the prefix as the reference parameter of query command. If the length of ID is doubled, the parameter of command would double. The result indicates our proposed scheme significantly reduce the length of query command by using the counter as the trigger in response to query.

Fig.5 Length of query command
As shown in Fig.6,the throughput of RDBST approaches 50%, which is close to theoretical value:u=n/(2n-1). The throughput of FST and LWST are significantly higher than RDBST. It indicates that the predictive identification improve the throughput by reducing the total number of slots. Fig.7 shows the case that 16-bit IDs are allocated by sequential assignment. The throughput of RDBST is still 50%. However, the throughput of the other two schemes is close to 1. That indicates the predictive identification could improve the throughput by taking advantage of the allocation of tag IDs. As shown in Fig.6 and Fig.7, the throughput curves of FST and LWST almost coincide. That indicates the simple predictive identification of LWST could replace the complex predictive identification of FST.
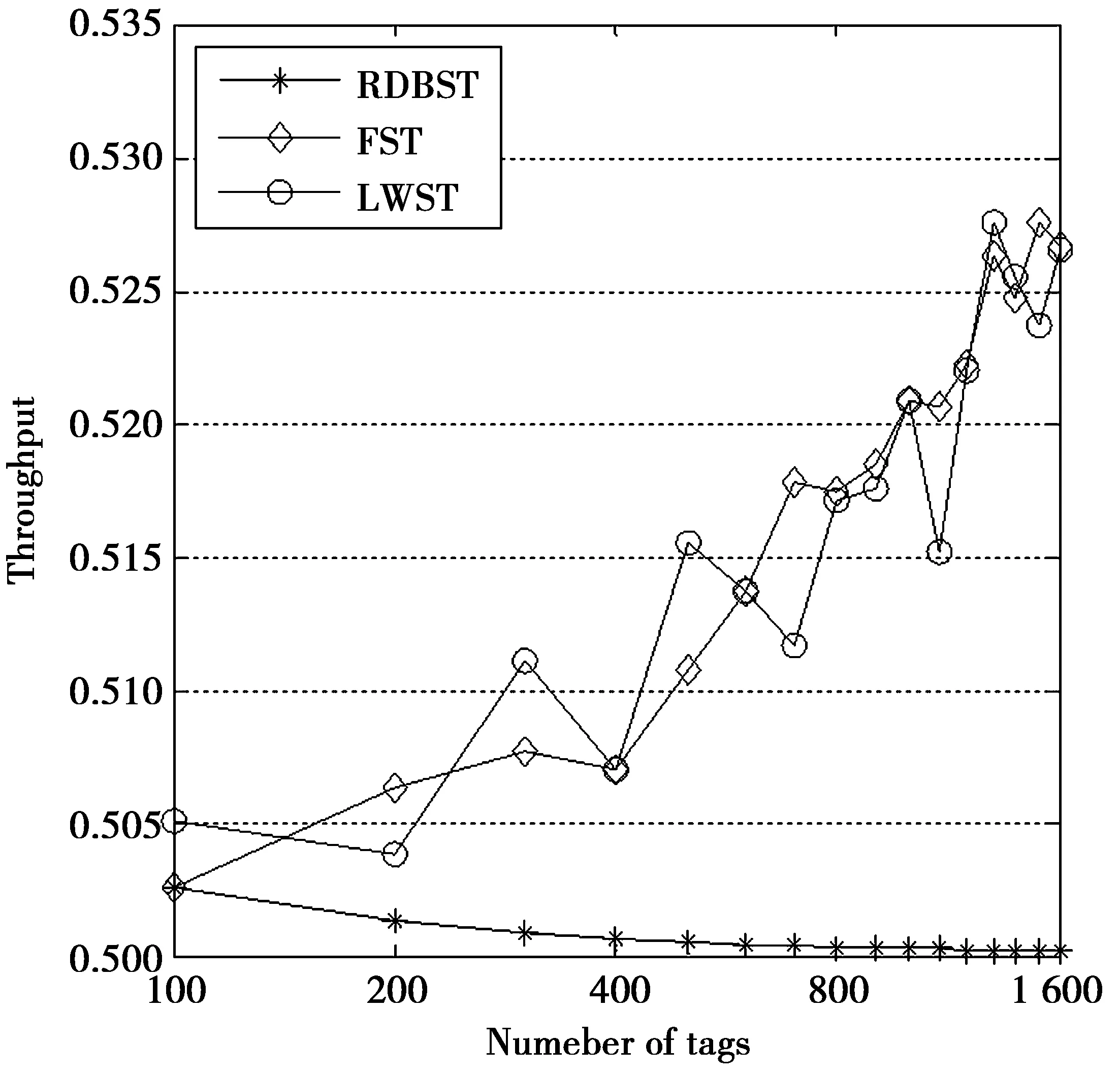
Fig.6 Throughput (random ID)

Fig.7 Throughput (sequential ID)
Fig.8 showsthe case that 16-bit IDs are allocated by random assignment, LWST has overall 42% less communication overhead than RDBST, 38% less than FST. Fig. 9 shows the case that 16-bit IDs are allocated by sequential assignment, LWST has overall 69% less communication overhead than RDBST, 39% less than FST. The results show that LWST performs better than other schemes no matter the allocation of tag IDs.

Fig.8 Communication overhead (random ID)

Fig.9 Communication overhead (sequential ID)
The results also prove thatin the sequential assignment of tag IDs experiment, LWST shows better performance. In most cases, tag IDs are assigned sequentially, such as warehouse management, production line, etc. In conferences [14]and [15], they preprocess ID or lock the collided bits before next query, and the locked bits constitute a new ID. In the case of a few tags, the schemes save some transmitted ID bits. While in the case of a large quantity of tags, the amount of the saved bits is the same as LWST. Therefore, those schemes don’t win better performance but increase the complexity of the schemes.
5 Conclusions
This paper is aimed primarily at reducing the redundant data generated in the process of identification and proposes alightweight anti-collision scheme based on searching tree. The scheme greatly decreases the total number of queries and reduces the length of query command, thus reducing the communication overhead. In the case of one collided bit in the received ID, the reader can identify two tags by predictive identification, which reduces the total slots and improves the throughput. The analysis on simulation result indicates that LWST scheme performs significantly better than the existing binary tree schemes. It is very suitable for the RFID anti-collision protocol in the case of a large quantity of tags.
