
Offline Urdu Nastaleeq Optical Character Recognition Based on Stacked Denoising Autoencoder
2017-05-08 11:32:25IbrarAhmadXiaojieWangRuifanLiShahidRasheed
China Communications 2017年1期
Ibrar Ahmad , Xiaojie Wang, Ruifan Li, Shahid Rasheed
1 Center for Intelligence of Science and Technology (CIST), School of Computer Science,Beijing University of Posts and Telecommunications, No.10 Xitucheng Road, Beijing 100876, China.
2 Department of Computer Science, University of Peshawar, Peshawar 25120, Pakistan.
3 Pakistan Telecommunication Company Limited (PTCL), Islamabad 44000, Pakistan
* The corresponging author, email: toibrar@yahoo.com, ibrar@upesh.edu.pk
I.INTRODUCTION
Urdu is the national language of Pakistan and is widely used in Southern Asia.Two different writing systems for Urdu namely Nastaleeq and Naskh are primarily in vogue.Nastaleeq system of writing is widely adopted in traditional Urdu books and newspaper writings.Other regional languages such as Persian,Pashto, Punjabi, Baluchi, and Siraiki also practice Nastaleeq writing style [1].All such applications increase the importance of Optical Character Recognition (OCR) for Nastaleeq script.OCR for printed Urdu Nastaleeq text therefore becomes imperative for digitalization.
During the last two decades, a lot work has been done on character based [2-8] and ligature based [1, 9-14] Urdu OCR.Despite of their success, there remain two major limitations: lack of suitable feature extraction techniques and scarcity of available data.Almost all researchers have applied hand-engineered feature extraction techniques which may not fully represent the data.Secondly,the largest reported dataset used comprised of approximately 83000 ligatures [15], which is not large enough for evaluating practical Urdu OCR.This paper addresses two main shortcomings that currently Urdu OCR systems exhibit.Firstly, we have used autoencoder based feature extraction method which is already proved very successful [16-20] for recognizing many image datasets by extracting features automatically from raw pixel values.And secondly, we have trained our system on 178573 ligatures from un-degraded version of Urdu Printed Text Image (UPTI) dataset [9]and tested on almost same number of ligatures from degraded versions of UPTI with 93% to 96% accuracy.
This paper proposes the use of stacked denoising autoencoder and softmax for automatic feature extraction directly from raw pixel values and classification, respectively.
1.1 Previous work
Previous work done on OCR for Printed Urdu Nastaleeq text can be classified into two types:characters based method and ligature based method.In literature, the former is known as segmented oriented while the latter as segmented free techniques also.A ligature may be a word or a sub-word which is composed of one or more connected characters.A ligature may usually compose of 1 to 8 characters.The Nastaleeq text recognition, as compared to Naskh, is more complex due to its overlapping, compactness, context sensitiveness, cursive nature, diagonality, and many other[21]properties shown in Figure 1.
Initially, considerable efforts were devoted to the recognition of Urdu basic character set.Multilayer Layer Perceptron (MLP) Network[2], Support Vector Machines (SVM) [3], Neural Network (NN) [4], Hidden Morkov Model(HMM) [5], Principal Component Analysis[6], Back Propagation (BP) based NN [7],and pattern matching classifier [8] have been used for recognition of Urdu characters.All of these OCR systems have used man designed features like invariant moments [3], structural features (width, height and checksum) [4],Discrete Cosine Transforms (DCT)[5], topological features [7] and chain code [8].The largest reported dataset is 36800 characters [3]with the accuracy of 93.59%.
Difficulties and complexities [21] of Urdu Nastaleeq text segmentation into characters cause the paradigm shift from character to ligature based Urdu text recognition systems.Most of the prevalent Urdu OCR techniques work on ligature based recognition [1, 9-10,12-15, 22].
Ligature based OCR systems produce superior results as compared to the counterpart character based recognition schemes.
Various models and features are explored in literature on ligature based Urdu text recognition.Many choices of learning models have been used for this purpose, such as HMM [1,13-15, 22], K-Nearest Neighbor (KNN) [9,23], SVM [12], and Bidirectional Long Short Term Memory (BLSTM) structure[10-11] with a layer of Connectionist Temporal Classification (CTC) at output.From the previous work,it is evident that the DCT is the most dominant features extraction technique used [1, 12-15, 22] for Urdu OCRs.Some other features include shape context [9], raw pixel values[10], sliding window [11], and Hu invariant moments [23], which are all man-designed.In Urdu OCR systems, no one has so far used any of the deep learning methods e.g.autoen-coders for automatic feature extraction [16].

Fig.1 Complexities of Nastaleeq writing style
1.2 Motivation
Scarcity of data for training is one of the major drawbacks of all Urdu OCR systems to-date.The largest data set for Urdu OCR system consists of 83000 ligatures [15].Also, one can easily detect that all available Urdu OCR systems are heavily relying on hand-engineered feature except [10-11].Such features are very hard to design, expensive, domain dependent and do not accurately mimic the properties of a dataset.Manual labeling like [10-11] of an enormous data set is almost impossible.
Autoencoders have been used to extract feature representation directly from the raw pixel values of an image [16-17, 29].With noisy input, Denoising Autoencoders (DAs)have been used to extract robust hidden representation of data independent of domain [19-20, 30].It can represent the intrinsic features of data which are very difficult to uncover by human-designed features.
Stacked Denoising Autoencoders (SDAs)have been successfully applied for character recognition [18] and recognition of Bangla Lanuage [24-25].Therefore, with the success of automatic feature extraction by autoencoders in many image recognition fields, it is a reasonable selection to let SDAs learn features itself from raw data of Urdu Nastaleeq text.
1.3 Contribution
In this paper, we presented a ligature based Urdu OCR application by using the basic SDA[18].No one in Urdu OCR research, thus far has reported the use of DA or SDA for feature learning.Here, different SDA networks with softmax layer on top are trained and tested on a very large dataset, known as Urdu Printed Text Image (UPTI) dataset [9].Detail about UPTI is presented in Section 3.1.
In the referenced work, the largest data set for Urdu OCR system consists of 83000 ligatures (224 pages *371 ligatures per page) [15].Similarly, over 10, 000 ligatures have been used in [9] from UPTI data set.Although [8]reports 98% accuracy, it uses very small data set i.e.noise free 9262 ligatures of 2190 classes.
We have used 178573 ligatures from 3732 classes of un-degraded version of UPTI for training the SDA and almost same number of ligatures from degraded versions for validation and testing.So, our training and testing set is more than twice in size than the largest dataset[15] used for Urdu OCR, so far.Validation and testing the trained SDA gives 4.14% error which is also lesser than the reported error in the referenced work.
The structure of this paper is as follows.In Section II, learning architecture of the recognition system is discussed.In Section III,experimental setup is explained.In Section IV,results are analyzed for evaluating the performance of recognition system.Finally, Section V concludes on the basis of results and analysis done.
I.LEARNING ARCHITECTURE
This section presents the introduction of basic autoencoder, denoising autoencoder and the architecture of proposed SDA model for ligature recognitions of Urdu language.Then the Algorithm 1 illustrates the training procedure of proposed SDA model.
2.1 Autoencoder
The most well-known use of deep neural networks is feature learning [16-18, 20].It offers a way to learn useful feature vector for the posed data [26].It may learn a compact,meaningful representation of the posed data,typically aiming for reducing dimensions [17].Autoencoder is basically a feed-forward and non-recurrent neural network.There may be one or more hidden layers in between input and output layer as shown in Figure 2.An autoencoder is a MLP except that it has equal number of inputs and output nodes.Moreover,an autoencoder predicts the input value x at the output.It does a feed-forward pass and predicts the value ofmeasures the difference between x andand back propagates by performing weight updates.
If the hidden layers are less than the input/output layers, then the final hidden layer represents the compressed representation of the input [27].As mentioned earlier, autoencoder is a subtype of MLP, therefore it can use all the activation functions used in MLP.
Denoising Autoencoder is a type of autoencoder, which tries to learn the input x at the output asby working on partially corrupted version of input.In this way, the learnt x may be more stable, robust and gives better higher level representation [19].
Different methods are available for corruption of input data, like MN, a suitable proportion of image pixels are masked to 0; Salt-and-Pepper Noise (SP), where randomly selected pixels of an image are set to maximum and minimum values of the image uniformly [18].We have used MN corruption method in our experiments.
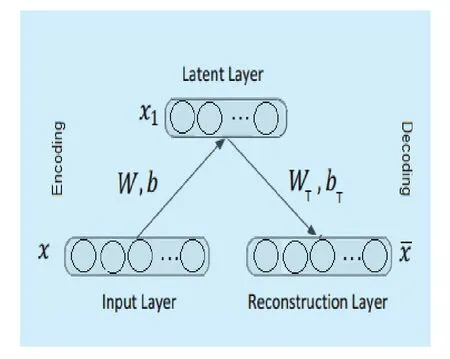
Fig.2 Basic autoencoder structures
2.2 Urdu ligature recognition stacked denoising autoencoder(ULR-SDA)
In this work, denoising autoencoders is used for learning Urdu ligature features.The architecture of the Stacked Denoising Autoencoder is illustrated in Figure 3.SDA network training consists of two steps: pre-training and fine-tuning.Former is performed in unsupervised way and latter in supervised manner.All layers of SDA are first trained layer wise,getting the input from latent representation of the previous network except the first hidden layer, which gets its input from outside.Pre-training is very helpful in initializing the network nodes by good representation instead of initializing them randomly [16].A MLP is made of all pre-trained layers and a back propagation algorithm is used for fine-tuning the network.
The process of the proposed Urdu Ligature Recognition Stacked Denoising Autoencoder (ULR-SDA) is illustrated in Algorithm 1.ULR-SDA also follows the two stage general setup of SDA as already explained.A deep stack of denoising autoencoders network is first pre-trained on the images of ligatures in an unsupervised manner, layer by layer as illustrated by first for-loop in Algorithm1.Afterwards, the trained layers are connected together to form a MLP.At the top of this MLP network, a logistic regression layer is added that uses softmax function for classification.This resultant network, ULR-SDA is then fine-tuned to anticipate the target ligatures as depicted by pseudo code lines 16-27 of Algorithm1.
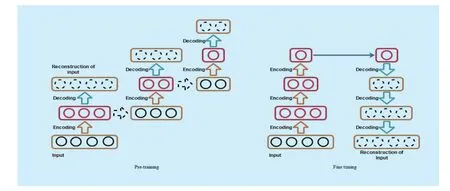
Fig.3 Training process of denoising autoencoder
The flowchart of proposed ULR-SDA is represented by Figure 4.It consists of three basic steps, namely, preprocessing, training,and testing.Preprocessing performs segmentation of image and ground truth sentences into ligatures.Training is carried out according to Algorithm 1.Testing performs classification with accuracy.
As proposed by Vincent et al.[16], for pre-training the stack of denoising autoencoder, the deep networks can be learnt using denoising autoencoders.The underlying model is trained with the intent to learn the hidden representation for reconstructing the input as normally done by standard auto encoder network.The only difference is that the denoising autoencoder is fed with the noisy input with the objective to learn more generalized hidden representation.
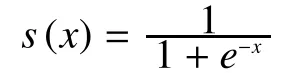
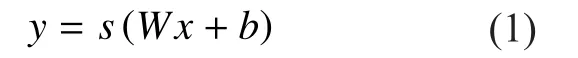
Here, the tied weight W and the bias vector b are used for encoding.The reconstructionis computed by using transposed weight matrixtransposed bias vectorand non-linear function s as follows:
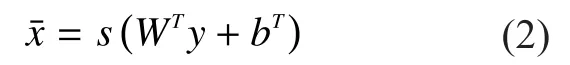
Thus, the derived autoencoder is trained on the noisy version of the input ligature x for its reconstruction.Therefore, the next autoencoder is trained in the same fashion, but the input for training of the next autoencoder is the hidden representation of the previous autoencoder.During this process, the reconstruction error between non-corrupted input ligaturexand reconstructedis computed by cross-entropy as presented in [16]:
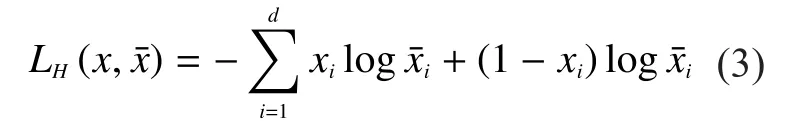
Once all autoencoders are pre-trained, they are connected layer wise to form a feed-for-ward MLP network.At the top of this MLP network, a layer of logistic regression added for the classification.The last layer uses softmax activation function for estimating class probabilities.This resulting complete MLP network of denoising autoencoders is finetuned through backpropagation algorithm.

Algorithm 1. Pseudocode for training ULR-SDA
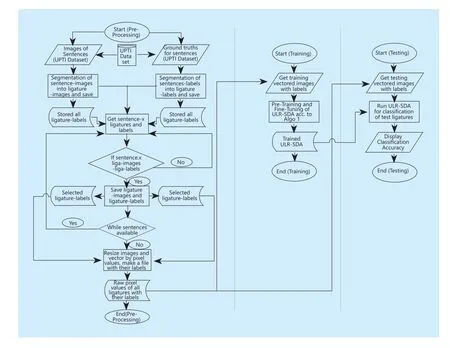
Fig.4 Preprocessing, training and testing process of urdu ligature recognition stacked denoising autoencoder (ULR-SDA)

Fig.5 UPTI sample sentence
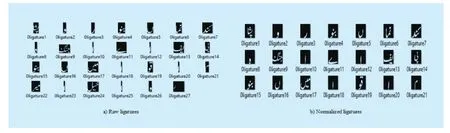
Fig.6 UPTI segmented ligatures
III.EXPERIMENTS
This section discusses the experiments for evaluating ULR-SDA architecture on printed offline Urdu script.
Two types of experiments based on different input dimensions were performed on UPTI dataset.ULR-SDA was trained on 178573 ligatures and tested on almost same number of ligatures with 3732 classes for 80*80 and 15*15 input dimensions.
3.1 Dataset and feature extraction
UPTI (Urdu Printed Text Images)1UPTI (Urdu Printed Text Images) dataset is provided by faisal.shafait@uwa.edu.au and adnan@cs.uni-kl.dedataset [9]is used for experimental purpose.This dataset contains 10063 sentence images.A sample sentence of UPTI is shown in Figure 5.
Four degradation techniques [28] have been applied, namely: jitter, elastic elongation,threshold and sensitivity.Every degradation technique has been applied with four different parameters value.So, UPTI contains 12 degradation versions of original 10063 sentence images.The sentence images of UPTI dataset from un-degraded as well as jitter, elongation and sensitivity degraded versions were segmented into ligatures as shown in Figure 6.The number of ligatures of un-degraded, jitter degraded, sensitivity degraded, and elastic elongation degraded versions are 189262,189265, 189260, and 189262 respectively.Segmented ligatures are then resized according to requirement as shown in Figure 6(a, b).
The ground truths are then tokenized into ligatures, having 3732 number of tokenized ligature classes after segmentation.Only ligatures from sentences are considered valid where a sentence contains equal number of images ligatures and label ligatures.This is because of the irregularities induced during printing as shown in Figure 7.Two ligatures are incorrectly connected by the extra length of the strokes, for exampleand.Fourth part consists of all secondary components of third part.Fourth partrepresents eight dots, out of that six are connected incorrectly.Size of these connected dots become more than the maximum threshold size of a secondary component and assumes as primary component by segmentation algorithm.Because of such incorrect connections,number of the image ligatures becomes less or more in numbers as compared to ligatures segmented from text lines of ground truth.
Only 3732 unique Urdu ligatures have been used in the UPTI dataset after dropping out the sentences where any sort of irregularity exists,as illustrated in preprocessing stage.Resized and normalized images of ligatures are then vectored into their pixel values and stored with their labels in tuple form for feeding as input to ULR-SDA.SVM classifier was also trained and tested with this format.
3.2 Experiment setup
For performing the experiments, ULR-SDA is trained on 178573 ligatures of un-degraded version and 60, 000 each from jitter degraded and sensitivity degraded versions of UPTI dataset for validation and testing respectively.There are 3732 classes of Urdu ligatures2A repository of 18, 000 Urdu ligatures: http://www.cle.org.pk/software/ling_resources/UrduLigatures.htm,which are used in UPTI dataset.Two different versions of UPTI dataset, i.e.; ligature images of 80*80 and 15*15 dimensions, have been constructed for experiments.For comparison study, a SVM classifier has also been trained and tested as explained earlier for ULR-SDA.In all cases, unsupervised pre-training and supervised fine-tuning (with simple stochastic gradient descent) procedures were applied,with early stopping based on validation set performance.In Figure 8 and 9, the “h” stands for 100 and ‘k’ for 1000.For example in Figure 8, 25h-16h-9h and 7k-5k-4k stand for SDA with hidden layers [2500, 1600, 900] and[7000, 5000, 4000] respectively.
3.3 Training ULR-SDA
Different ULR-SDA networks are trained and tested for ligature recognition as shown in Table I and Figure 8.Best ULR-SDA network has three hidden layers with [7000, 5000,4000] units for 80*80 input dimensions and[2500, 1600, 900] units for 15*15 input dimensions.All hidden layers were pre-trained as denoising autoencoders by stochastic gradient descent, using the cross-entropy cost method with the learning rate of 0.001.
For all experiments during pre-training, 10 epochs were executed for ligatures of 80*80 as well as for 15*15 dimensions.Fine tuning of the entire MLP network was done by stochastic gradient descent using cross entropy loss function while adopting the learning rate of 0.1.The fine tuning executed until number of epochs were less than100 or the validation error did not fall below 0.1 % as shown in Fig-ure 8.All experiments were conducted using Theano library 6 on GPU.
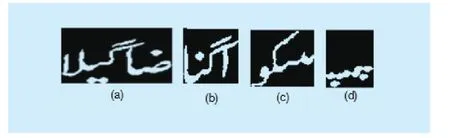
Fig.7 Wrongly connected components of ligatures
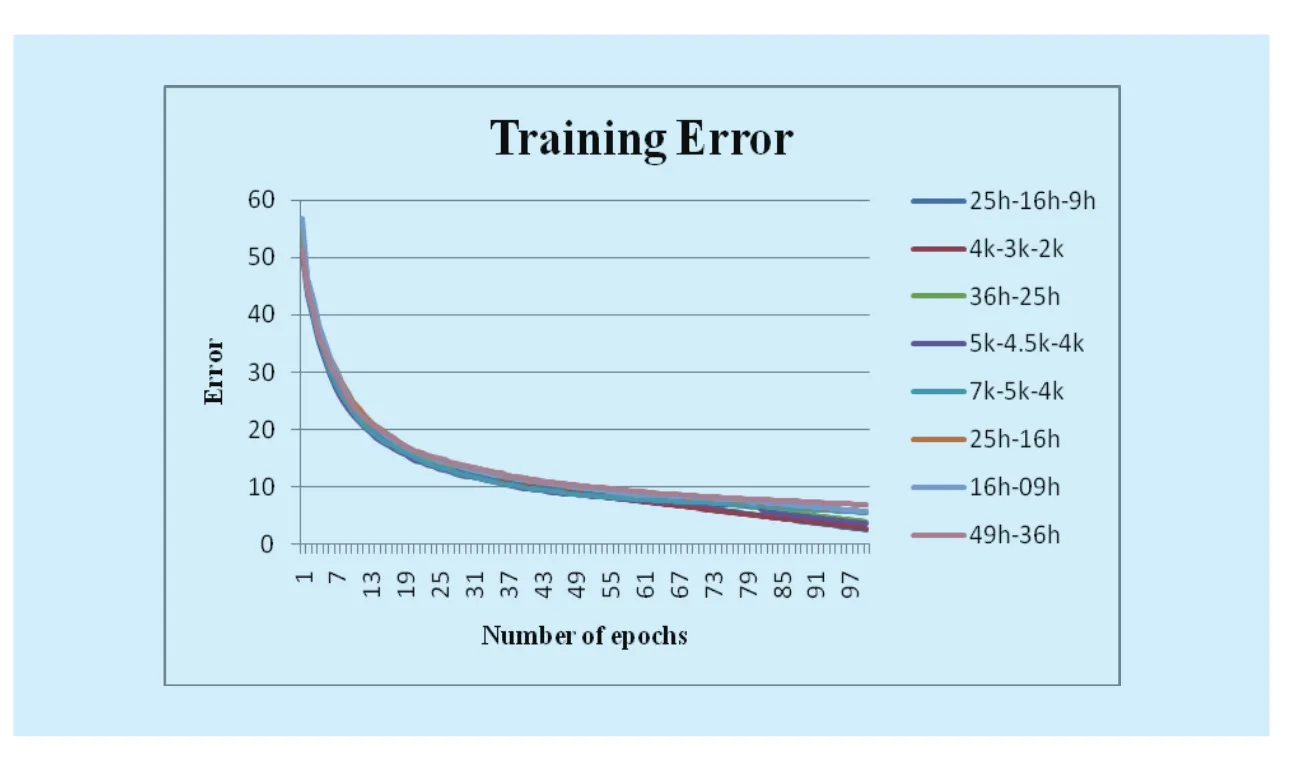
Fig.8 Number of epochs and training error of ULR-SDA
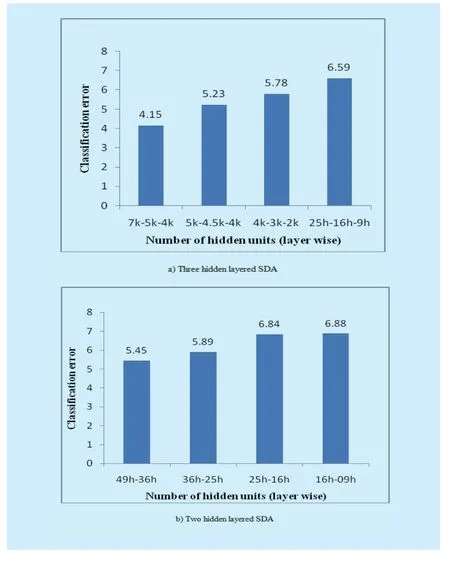
Fig.9 Effect of the number of hidden units in each layer on error

Table I Comparison of ULR-SDA and SVM based on same training and test data Table I(a) Results for 80*80 pictures

Table I(b) Results for 15*15 pictures
IV.RESULTS
In this section, the results of ULR-SDA and SVM are compared.After the comparison, the analysis of different structures of ULR-SDA is presented.At the end, the effects of input and middle layer dimensions on error are discussed.
4.1 Comparison of ULR-SDA and SVM
In order to evaluate the performance of ULRSDA, the system is trained on the un-degraded ligatures of UPTI dataset.The trained network is then tested on elastic elongation, jitter and sensitivity degraded versions of the same dataset.
For comparison purpose, a multiclass SVM with Radial basis function(rbf) kernel is trained and tested in the similar fashion as ULR-SDA.Both classifiers namely ULR-SDA and SVM are trained on 80*80 and 15*15 input dimensions for 3732 output classes.
Three layered ULR-SD achieved the ligature recognition accuracy of 96% where the SVM got 95% accuracy for 80*80 input dimensions as shown in Table I(a).Similarly,three layered ULR-SDA recognized ligature with the accuracy of 95.86% and SVM got 85% accuracy for 15*15 input dimensions Table I(b).The ULR-SDA shows superior recognition result as compare to state of the art SVM algorithm as shown in Table I.Furthermore, both classifiers achieved better accuracy on 80*80 input dimensions as compared to 15*15, which is obvious because former contains more pixel information of every ligature as input.
4.2 Structure of ULR-SDA
The structure of the proposed ULR-SDA is evaluated on two parameters: firstly by increasing the number of neurons of hidden layers and secondly by increasing the number of hidden layers as are shown in Figures 9 and 10 respectively.
For this evaluation, 15*15 input dimensions have been used for all networks.Figure 9(a) shows the performance deteriorates with the decrease in the number of hidden units per layer.Three layered network [7000, 5000,4000] performs better than the network with hidden layers [5000, 4500, 400], [4000, 3000,2000], and [2500, 1600, 900].Similarly, Figure 9(b) shows two layered network [4900,3600] and [3600, 2500] performs better than[2500, 1600] and [1600, 900].
Figure 10 shows the increased performance of ULR-SDA, as we increase the number of hidden layers from 1 to 3, for three different networks.Apart from Figure 10, Figure 9 also shows that the performance of the 3 layered networks is better than that of two layered networks.
4.3 Dimensions
The performance of ULR-SDA varies by input data dimensions and dimension of middle layer as shown in Table II and Figure 11.ULRSDA has been trained on examples of 80*80 and 15*15 dimensions.ULR-SDA outputs better results when trained and tested on examples of 80*80 input dimensions as shown in Table II.
The recognition accuracies of ULR-SDA upon training and testing the examples of 80*80 and 15*15 dimensions with hidden layers [7000, 5000, 4000] are 96% and 95.86%respectively as shown in Table II(a).
Similarly, the recognition accuracies for 80*80 and 15*15 input data dimensions with hidden layers [5000, 4500, 4000] are 96% and 94.77% respectively as shown in Table II(b).The accuracy will be increased with the increase in dimensions of input data.
In Figure 11(b), the general trend is showing an increase in error for two layered network as well.More informative middle layer representation results in better accuracy in URL-SDA can, therefore, be confirmed.
V.CONCLUSION AND FUTURE WORK
This work is inspired by the success of recent SDA deep networks for characters and digits recognition.At the same time, the recent work on SDA for recognition of Bangla Lanuage[24-25] motivated us towards the implementation of deep SDA for Urdu Nastaleeq recognition.This works mainly introduces the use of deep neural networks (SDA) in the field of Urdu OCR.Also, it demonstrates that the pro-cess of recognition may become very straightforward and easy, if raw pixel values are used instead of calculating different features.In this way, better representation of all aspects of input data may be efficiently achieved, which may enhance the performance of existing Urdu OCR systems.
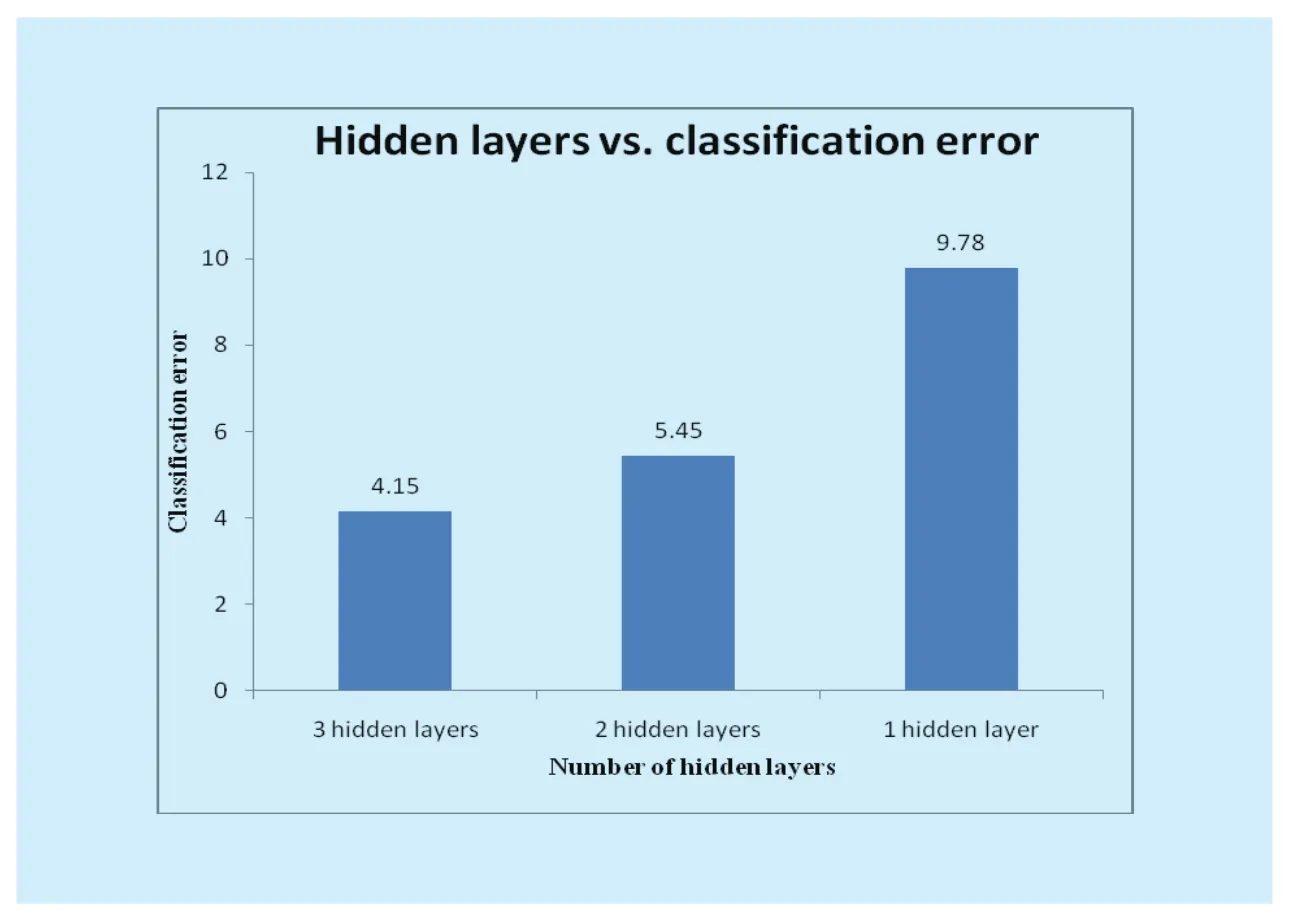
Fig.10 Effect of the number of hidden layers on error
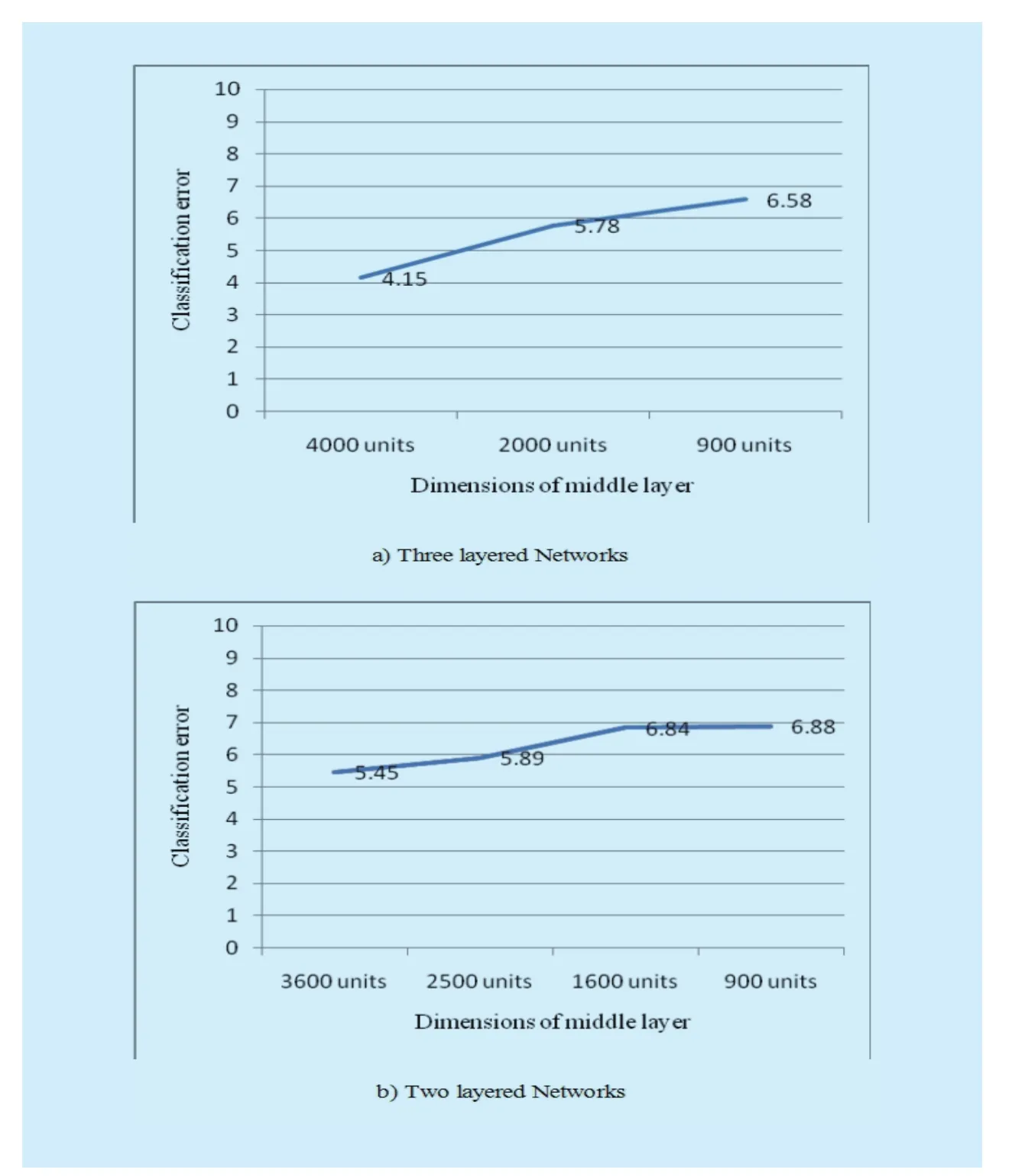
Fig.11 Dimension of middle layer and error
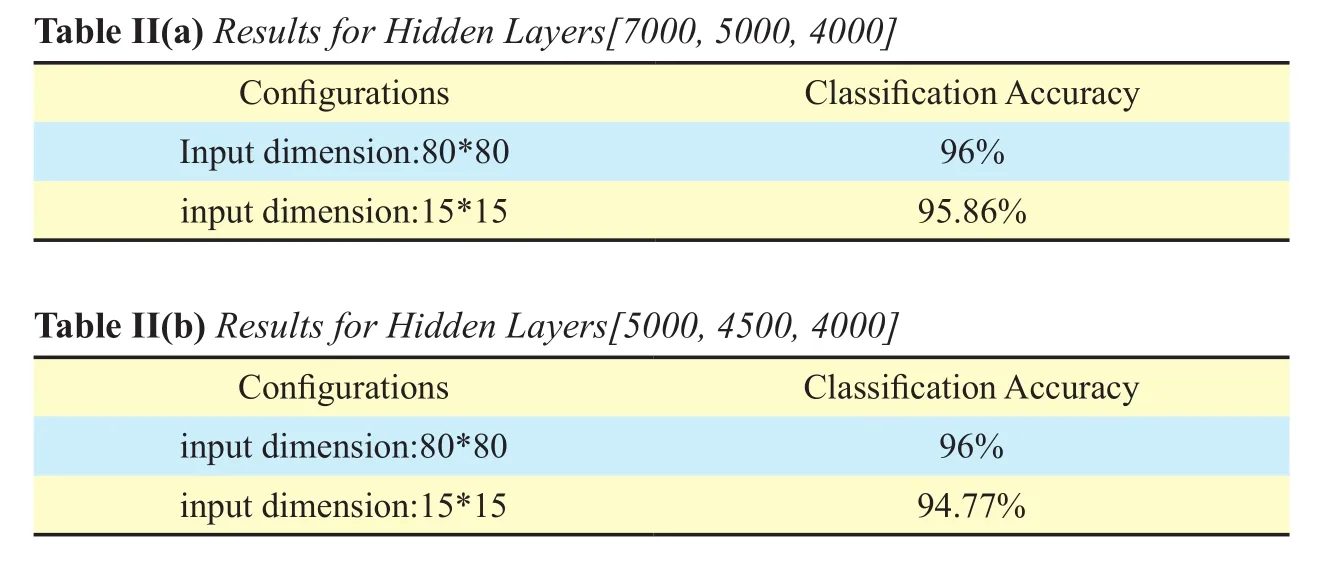
Table II Effect of number of input data dimensions on accuracy (3732 classes,180k training examples)
In this paper, stacked denoising autoencoders and softmax at output layer have been used for automatic feature extraction directly from raw pixel values and classification respectively.Different stacked denoising autoencoders have been trained on 178573 ligatures with 3732 classes from un-degraded UPTI (Urdu Printed Text Image) data set.The trained networks are then validated and tested on degraded versions of UPTI data set.To compare the performance of ULR-SDA, multi class SVM classifiers have been trained and tested on the same train and test sets.Test results show that the accuracies of ULR-SDA networks are 93%to 96%, while the accuracies of SVM classifiers are in the range of 80% to 95%.The results of ULR-SDA based ligature recognition achieved are therefore better than the precision realized by the prevailing Urdu OCR systems for such a large dataset of ligatures.
In the future, we will pay more attention towards a better segmentation algorithm.It would also be interesting to investigate deep denoising autoencoders with more than three hidden layers.We have used static corruption process, it also needs further investigation.
Note
In this paper, we introduce stacked denoising autoencoders and softmax for automatic feature extraction directly from raw pixel values and classification respectively.
ACKNOWLEDGEMENTS
The financial supports from National Natural Science Foundation of China (Project No.61273365) and 111 Project (No.B08004) are gratefully acknowledged.
[1] S.HUSSAIN, S.ALI, and Q.AKRAM, “Nastalique Segmentation-Based Approach for Urdu OCR,” International Journal on Document Analysis and Recognition (IJDAR), vol.18, no.4, pp.357-374, 2015.
[2] I.Shamsher, Z.Ahmad , J.K.Orakzai, and A.Adnan, “OCR for printed Urdu script using feed forward neural network, ” In the Proceedings of World Academy of Science, Engineering and Technology, vol.23, pp.172-175, 2007.
[3] K.P.Imran, Abdulbari A.A, Ali, and R.J Ramteke,“Recognition of offline handwritten isolated Urdu character, ” International Journal on Advances in Computational Research, vol.4, no.1,pp.117-121, 2012.
[4] J.Tariq, U.Nauman, and M.U.Naru, “Softconverter: a novel approach to construct OCR for printed urdu isolated characters, ” In International Conference on Computer Engineering and Technology (ICCET), vol.3, pp.495-498,April.2010.
[5] Q.U.Akram, S.Hussain, Z.Habib, “Font size independent OCR for Noori Nastaleeq, ” Proceedings of Graduate Colloquium on Computer Sciences (GCCS), Department of Computer Science, FAST-NU Lahore, vol.1, 2010.
[6] K.Khan, R.Ullah, N.A.Khan, and K.Naveed,“Urdu character recognition using principal component analysis, ” International Journal of Computer Applications, vol.60, no.11, pp 1-4,2012.
[7] Ahmad Z, Orakzai JK, Shamsher I, Adnan A.“Urdu Nastaleeq optical character recognition,” In Proceedings of world academy of science,engineering and technology, vol.26, pp.249-252, Dec, 2007.
[8] T.Nawaz, S.A.Naqvi, H.urRehman, and A.Faiz,“Optical character recognition system for urdu(naskh font) using pattern matching technique,” International Journal of Image Processing(IJIP), vol.3, no.3, p.92, Jun, 2009.
[9] N.Sabbour and F.Shafait, “A segmentation-free approach to Arabic and Urdu OCR, ” InIS&T/SPIE Electronic Imaging, pp.86580N-86580N,Feb, 2013.
[10] A.Ul-Hasan, S.B.Ahmed, F.Rashid, F.Shafait,and T.M.Breuel, “Offline printed Urdu Nastaleeq script recognition with Bidirectional LSTM networks, ” In Document Analysis and Recognition (ICDAR), Conf.12, pp.1061-1065, Aug,2013.
[11] S.Naz, A.I.Umar, R.Ahmad, S.B.Ahmad, S.H.Shirazi, I.Siddiqi, and M.I.Razzak, “Offline cursive urdu nastaliq script recognition using multidimensional recurrent neural networks, ”Neurocomputing, vol.177, pp.228–241, Feb,2016.
[12] G.S.Lehal, “Ligature segmentation for urdu OCR, ” In 12th International Conference on Document Analysis and Recognition (ICDAR),pp.1130–1134, Aug, 2013, doi: 10.1109/ICDAR.2013.229
[13] S.A.Husain, “A multi-tier holistic approach for Urdu Nastaliq recognition, ” In International Multi topic conference (INMIC), pp.84-84, Dec,2002.
[14] S.T.Javed and S.Hussain, “Segmentation Based Urdu Nastalique OCR, ” In Iberoamerican Congress on Pattern Recognition, pp.41-49, 2013.
[15] Q.Akram, S.Hussain, F.Adeeba, S.Rehman,and M.Saeed, “Framework of Urdu Nastalique Optical Character Recognition System, ” In the Proceedings of Conference on Language and Technology (CLT 14), Karachi, Pakistan, 2014.
[16] P.Vincent, H.Larochelle, Y.Bengio, and P.A.Manzagol, “Extracting and composing robust features with denoising autoencoders, ” In Proceedings of the 25th international conference on Machine learning, pp.1096-1103, Jul, 2008.
[17] G.E.Hinton and R.R.Salakhutdinov, “Reducing the dimensionality of data with neural networks,” Science.313(5786), pp.504-507, Jul, 2006.
[18] P.Vincent, H.Larochelle, I.Lajoie, Y.Bengio Y,and P.A.Manzagol, “Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion, ”The Journal of Machine Learning Research, vol.11, no.Dec, pp.3371-3408, Mar, 2010
[19] Y.Bengio, “Learning deep architectures for AI,” Foundations and trends in Machine Learning,vol.2, no.1, pp.1-27.Jan, 2009.
[20] H.Larochelle, D.Erhan, and P.Vincent, “Deep learning using robust interdependent codes, ”In International Conference on Artificial Intelligence and Statistics, pp.312-319, 2009.
[21] S.Naz, K.Hayat, I.Razzak, W.Anwar, M.Madani,and U.Khan.“The optical character recognition of Urdu-like cursive scripts, ” Pattern Recognition, vol.47, no.3, pp.1229-1248, 2014.
[22] S.T.Javed, S.Hussain, A.Maqbool, S.Asloob,S.Jamil, and H.Moin, “Segmentation free nastalique urdu ocr, ” World Academy of Science,Engineering and Technology, vol.46, pp.456-461, 2010.
[23] S.Sardar and A.Wahab, “Optical character recognition system for Urdu, ” In International Conference on Information and Emerging Technologies (ICIET), pp.1-5, Jun, 2010.
[24] A.Pal and J.D.Pawar, “Recognition of online handwritten Bangla characters using hierarchical system with Denoising Autoencoders, ” In International Conference on Computation of Power, Energy Information and Communication,pp.47-51, Apr, 2015.
[25] A.Pal, “Bengali handwritten numeric character recognition using denoising autoencoders, ” In IEEE International Conference on Engineering and Technology, pp.1-6, Mar, 2015.
[26] Y.Bengio, P.Lamblin, D.Popovici, and H.Larochelle, “Greedy layer-wise training of deep networks, ” Advances in neural information processing systems, vol.19, pp.153, Dec, 2007.
[27] P.Baldi, “Autoencoders, unsupervised learning,and deep architectures, ” Unsupervised and Transfer Learning Challenges in Machine Learning, vol.7, no.1, pp.37-50, 2012.
[28] H.S.Baird, “Document image defect models, ”In Structured Document Image Analysis, vol.1,pp.546-556, Jan, 1992.
[29] F.Feng, X.Wang, R.Li, and I.Ahmad, “Correspondence Autoencoders for Cross-Modal Retrieval, ” ACM Transactions on Multimedia Computing, Communications, and Applications,vol.12, no.1s, pp.26, Oct, 2015.
[30] O.K.Oyedotun, E.O.Olaniyi, and A.Khashman, “Deep Learning in Character Recognition Considering Pattern Invariance Constraints, ”International Journal of Intelligent Systems and Applications, vol.7, no.7, pp.1, Jun, 2015.

- China Communications的其它文章
- A Non-Cooperative Differential Game-Based Security Model in Fog Computing
- Dynamic Weapon Target Assignment Based on Intuitionistic Fuzzy Entropy of Discrete Particle Swarm
- Directional Routing Algorithm for Deep Space Optical Network
- Identifying the Unknown Tags in a Large RFID System
- Reputation-Based Cooperative Spectrum Sensing Algorithm for Mobile Cognitive Radio Networks
- Toward a Scalable SDN Control Mechanism via Switch Migration